登录社区云,与社区用户共同成长
邀请您加入社区
当代理式 AI、生成式 AI 重塑产业边界,当数据中心成为 AI 工厂,海量算力、算存协同与能效优化成为新一代10 亿瓦级(Gigawatt)数据中心的基石,一场定义未来的技术盛宴即将启幕!完成注册与登录后,自动跳转回到该专场页面,点击“Add to Schedule”绿色按钮,状态变为“Scheduled”即预约成功。NVIDIA 新一代 AI 网络(纵向扩展、横向扩展、跨域扩展)NVIDIA
立即报名NVIDIA 深度学习培训中心(DLI)举办的机器人仿真开发实战培训,系统覆盖机器人仿真环境搭建与开发流程,欢迎广大机器人开发工程师、研究人员及技术爱好者学习。本课程面向机器人工程师、应用研究人员及机器人软件研发团队打造,同时适用于从事机器人系统研发、仿真验证与算法开发的技术人员,以及教育行业和学习者。课程结束后,学员将具备亲手搭建机器人仿真环境的能力,并能将合成数据工作流集成到其中,构建
想系统提升深度学习与 AI 项目落地能力?通过 NVIDIA 深度学习培训中心(DLI)推出的深度学习系列培训,涵盖近 20 门实战课程,帮助您掌握模型构建、优化与部署解决方案所需的核心工具与框架,积累可真正落地的实战经验。课程不仅助力个人职业发展与竞争力提升,更能帮助团队高效推进关键 AI 项目落地,适合希望从理论走向实战、打造硬核 AI 能力的开发者、从业者和学员。探索最先进的 AI 天气预测
注册 NVIDIA 开发者新用户,即可免费任选一门价值 600 元的 AI 实战培训课程,通过动手实操掌握完整的开发流程,完课后可获得 NVIDIA 培训证书,助力开发者技能提升。NVIDIA-Certified Professional (NCP-AII,NCP-AIO,NCP-AIN): 2880 元。报名 NVIDIA 认证讲师全天中文实时在线讲解和答疑的 AI 培训班,配置云端实验环境,动
Mistral Large 3 是专家混合 (MoE) 模型,无需为每个 token 激活全部神经元,可以仅调用模型中影响最大的部分,既可在无浪费的前提下实现高效扩展,又可确保准确性不受损,使企业级 AI 不仅成为可能,而且更具实用性。通过整合 NVIDIA Grace Blackwell 机架级扩展系统与 Mistral AI 的 MoE 架构,企业可借助先进的并行计算与硬件优化技术,高效部署并
NVIDIA 面向数据中心多节点环境的开源分布式推理服务框架 Dynamo 的组件 AIConfigurator 和 Grove,分享它们分别如何解决 PD 分离架构下大模型推理的两个核心落地难题:在庞大配置空间中高效寻优,以及在 Kubernetes 上优雅编排多组件推理服务。P/D 分离的抉择,到 Prefill/Decode 资源的配比,再到并行策略的设定,庞大的参数空间使得人工调优如同大海
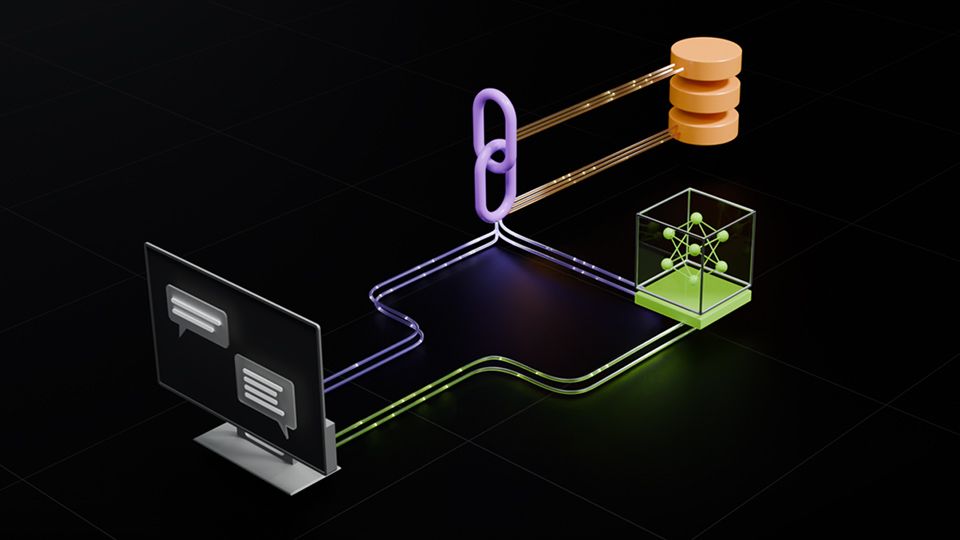
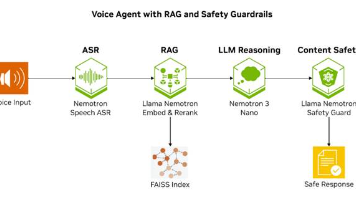
现在,您拥有一个由 Nemotron 驱动的智能体核心结构,该结构由四个核心组件组成:用于语音交互的语音 ASR、用于实现信息真实性的多模态 RAG、考虑文化差异的多语言内容安全过滤,以及用于长上下文推理的 Nemotron 3 Nano。每一层都有自己的接口、延迟限制和集成挑战,一旦跨过简单的原型就会开始感受到这些挑战。您可以在本地 GPU 上进行开发,然后将相同的代码部署到可扩展的 NVIDI
领先科技企业例如博世、CodeRabbit、CrowdStrike、Cohesity、Fortinet、Franka Robotics、Humanoid、Palantir、Salesforce、ServiceNow、日立和 Uber 等,正在使用并基于 NVIDIA 的开放模型技术进行开发。在 Hugging Face 平台上,机器人技术是增长较快的领域,开发安全、可规模化的辅助驾驶依赖于 AI
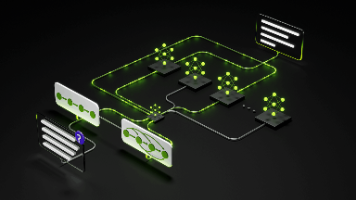
这一全新开放模型系列引入了开放的混合 Mamba-Transformer MoE 架构,使多智能体系统能够进行快速长上下文推理。2025年 12月 15日和系统日益依赖协同运行的智能体集合,包含检索器、规划器、工具执行器、验证器等,它们需在大规模上下文上长时间协同工作。这类系统需要能够提供快速吞吐、高精度及大规模输入持续一致性的模型。它们也需要一定的开放性,使开发者能够在任意运行环境定制、扩展和部
NVIDIA 于 12 月 15 日宣布推出 NVIDIA Nemotron™ 3 系列开放模型、数据和库,为各个行业透明、高效的专业代理式 AI 开发提供助力。Nemotron 3 模型提供 Nano、Super 和 Ultra 三种规模,采用突破性的架构,帮助开发者大规模开发并部署可靠的多智能体系统。随着企业从单模型对话机器人转向协作式多智能体 AI 系统,开发者面临着日益严峻的挑战,包括通信