登录社区云,与社区用户共同成长
邀请您加入社区
采用 NVIDIA Blackwell 架构的 NVIDIA GB200 NVL72 和 NVIDIA GB300 NVL72 系统是机架级超级计算机。它们采用 18 个紧密合的计算托盘、大型 GPU 网络和整体式高带宽网络设计。对于 AI 架构师和 HPC 平台运营商而言,挑战不仅仅在于机架和堆叠硬件,还在于将基础设施转变为面向最终用户的安全、高性能且易于使用的资源。机架级硬件拓扑与调度器抽象之
物理 AI (在基于物理性质的模拟环境中感知、推理和行动的 AI 系统) 正在改变团队设计和验证机器人和工业系统的方式,而这一切远早于任何产品交付到工厂车间。在大会上,NVIDIA 强调物理 AI 是机器人和的关键方向,在基于物理的环境中训练和验证策略。为使 NVIDIA Omniverse 更易于集成到现有应用中,NVIDIA 在现有平台的基础上增加了一个基于库的模块化架构。ovrtxovphy
MiniMax M2.7 的发布为流行的模型增加了增强功能,该模型专为代理式线束以及推理、ML 研究工作流程、软件、工程和办公室工作等领域的其他复杂用例而构建。MiniMax M2.7 的开源权重版本现已通过 NVIDIA 和整个开源推理生态系统提供。MiniMax M2 系列是稀疏混合专家 (MoE) 模型系列,专为提高效率和功能而设计。MoE 设计可保持较低的推理成本,同时保留 230B 参数
在这个过程中,零一万物基于 NVIDIA 软硬结合的技术栈,在功能开发、调试和性能层面,与 NVIDIA 团队合作优化,完成了在大模型的 FP8 训练和验证。在此基础上,零一万物团队进一步的设计了训练容错方案:由于没有 BF16 的 baseline 来检查千亿模型 FP8 训练的 loss 下降是否正常,于是,每间隔一定的步数,同时使用 FP8 和 BF16 进行训练,并根据 BF16 和 FP
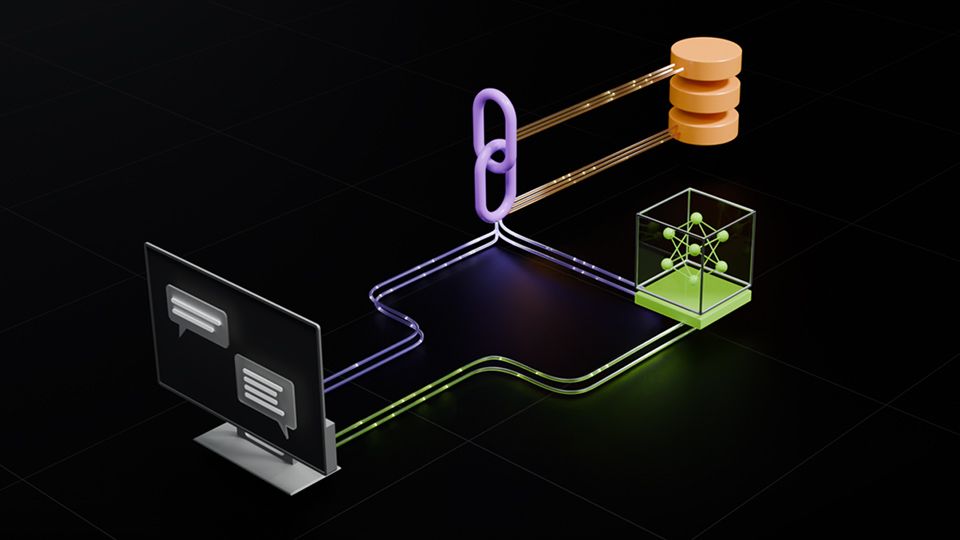
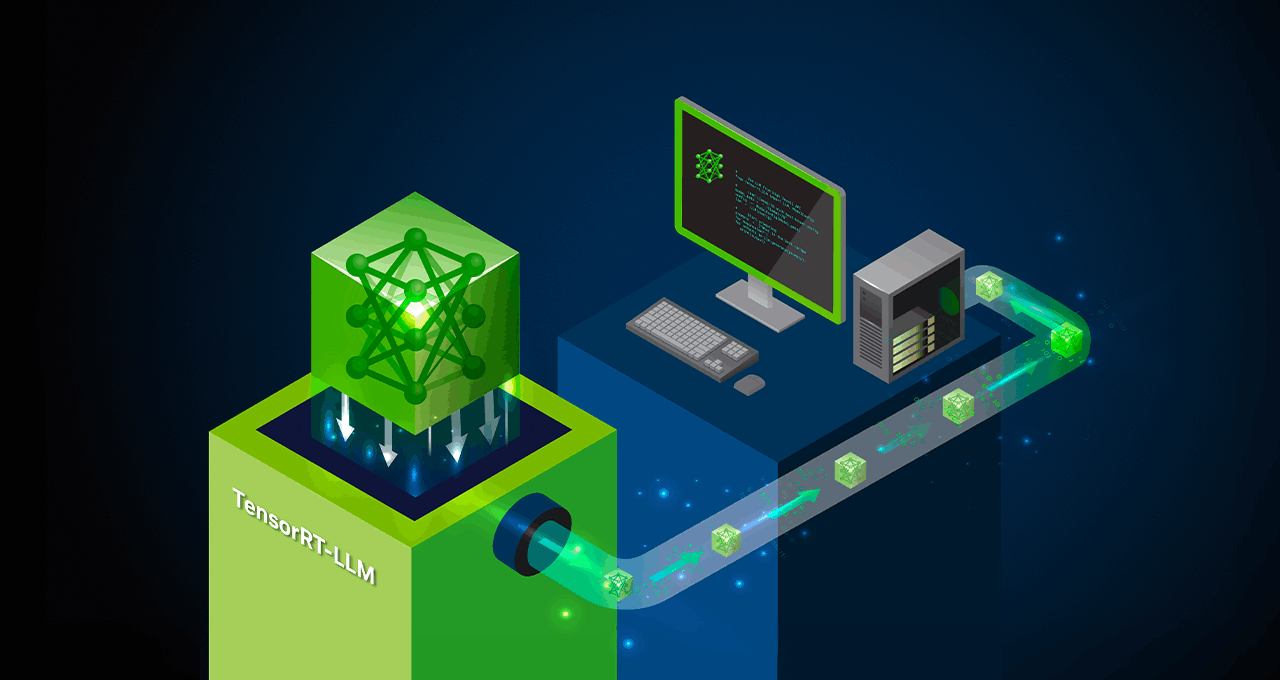
过往,许多用户在将 TensorRT-LLM 集成到自身软件栈的过程中,总是希望能更好地了解 TensorRT-LLM 的 Roadmap。即日起,NVIDIA 正式对外公开 TensorRT-LLM 的 Roadmap ,旨在帮助用户更好地规划产品开发方向。近期,我们收到了许多用户的积极反馈,并表示,TensorRT-LLM 不仅显著提升了性能表现,还成功地将其应用集成到各自的业务中。这不仅有助
NVIDIA CUDA 13.3 为整个 CUDA 生态系统的开发者带来了新功能和性能优化。通过在 C++ 中引入,支持基于 Tile 的高级内核开发,能够自动管理复杂的底层 GPU 细节,从而实现卓越的性能和可移植性。此外,CUDA Tile 编程现在不仅支持所有其他已支持的 GPU 架构,还新增了对计算能力 9.0(NVIDIA Hopper)GPU 的支持。我们还将发布 CUDA Pytho
Mistral Large 3 是专家混合 (MoE) 模型,无需为每个 token 激活全部神经元,可以仅调用模型中影响最大的部分,既可在无浪费的前提下实现高效扩展,又可确保准确性不受损,使企业级 AI 不仅成为可能,而且更具实用性。通过整合 NVIDIA Grace Blackwell 机架级扩展系统与 Mistral AI 的 MoE 架构,企业可借助先进的并行计算与硬件优化技术,高效部署并
NVIDIA 面向数据中心多节点环境的开源分布式推理服务框架 Dynamo 的组件 AIConfigurator 和 Grove,分享它们分别如何解决 PD 分离架构下大模型推理的两个核心落地难题:在庞大配置空间中高效寻优,以及在 Kubernetes 上优雅编排多组件推理服务。P/D 分离的抉择,到 Prefill/Decode 资源的配比,再到并行策略的设定,庞大的参数空间使得人工调优如同大海
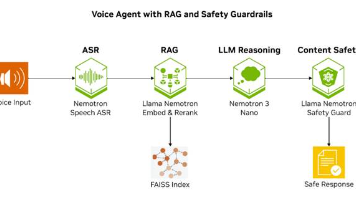
现在,您拥有一个由 Nemotron 驱动的智能体核心结构,该结构由四个核心组件组成:用于语音交互的语音 ASR、用于实现信息真实性的多模态 RAG、考虑文化差异的多语言内容安全过滤,以及用于长上下文推理的 Nemotron 3 Nano。每一层都有自己的接口、延迟限制和集成挑战,一旦跨过简单的原型就会开始感受到这些挑战。您可以在本地 GPU 上进行开发,然后将相同的代码部署到可扩展的 NVIDI
领先科技企业例如博世、CodeRabbit、CrowdStrike、Cohesity、Fortinet、Franka Robotics、Humanoid、Palantir、Salesforce、ServiceNow、日立和 Uber 等,正在使用并基于 NVIDIA 的开放模型技术进行开发。在 Hugging Face 平台上,机器人技术是增长较快的领域,开发安全、可规模化的辅助驾驶依赖于 AI