
轻松部署、加速推理:TensorRT LLM 1.0 正式上线,全新易用的 Python 式运行
对于需要基于 PyTorch 实现自定义模型的开发者,TensorRT LLM 提供了清晰的迁移与注册流程。首先,若开发者已拥有 Hugging Face 生态中的 Torch 建模代码,可直接将其引入 TensorRT LLM 系统,同时完成关键组件的注册,确保模型能与框架的运行时模块正常交互,启动基础推理功能。。

2024年 12月 2日
By Laikh Tewari
TensorRT LLM 核心定位与实现路径
TensorRT LLM作为 NVIDIA 为大规模 LLM 推理打造的推理框架,核心目标是突破 NVIDIA 平台上的推理性能瓶颈。为实现这一目标,其构建了多维度的核心实现路径:一方面,针对需部署热门开源模型的应用场景,框架已支持 GPT-OSS、DeepSeek、Llama 2 及 Llama 3 等主流模型的端到端部署,开发者可直接基于框架完成性能优化,无需额外搭建复杂适配流程;另一方面,框架将部署功能封装为可扩展的 Python 框架,这一设计让拥有自定义或专有模型的开发者能更便捷地接入,无需从零构建部署体系;同时,TensorRT LLM 还承担着推理领域新技术载体的角色,通过将前沿创新引入 LLM 推理生态,持续提升整个生态系统合作伙伴的技术能 TensorRT LLM 1.0:易用性优化与实现方式

TensorRT LLM 1.0:易用性优化与实现方式
TensorRT LLM 1.0 版本的核心升级聚焦于易用性提升,且针对不同角色的用户需求进行了差异化设计。对于模型部署者,框架支持热门模型从研究阶段快速过渡到生产环境,大幅缩短落地周期;对于框架开发者,其模块化系统允许灵活提取核心组件并集成到自定义软件中,降低二次开发难度;对于使用自定义模型的用户,框架则通过简化功能调用流程,降低了技术扩展门槛,便于基于新技术迭代模型。
为实现这些易用性目标,框架在技术层面做了多重优化:首先,支持将现有 PyTorch 模型(如 Hugging Face 生态中的建模代码)迁移至 TensorRT LLM,且优化过程可分步实施,例如先完成基础迁移,再逐步用自定义注意力 Torch 操作替换普通注意力层,或注册高级 GEMM 组件以获取并行化能力;其次,框架完全兼容 PyTorch 与 Python 生态中的调试工具,开发者可直接使用 PDB 调试或打印张量中间值等熟悉的方式排查问题;此外,新运行时采用模块化 Python 构建块设计,为核心组件定义清晰接口并提供 Python 实现,若需扩展功能或调整行为,可直接修改 Python 代码或遵循协议引入自定义模块;同时,框架无需提前编译或构建显式引擎,支持快速迭代参数与跨硬件切换;最后,所有功能均开源在 GitHub,开发者可直接与 NVIDIA 团队协作,通过贡献代码推动框架路线图演进。
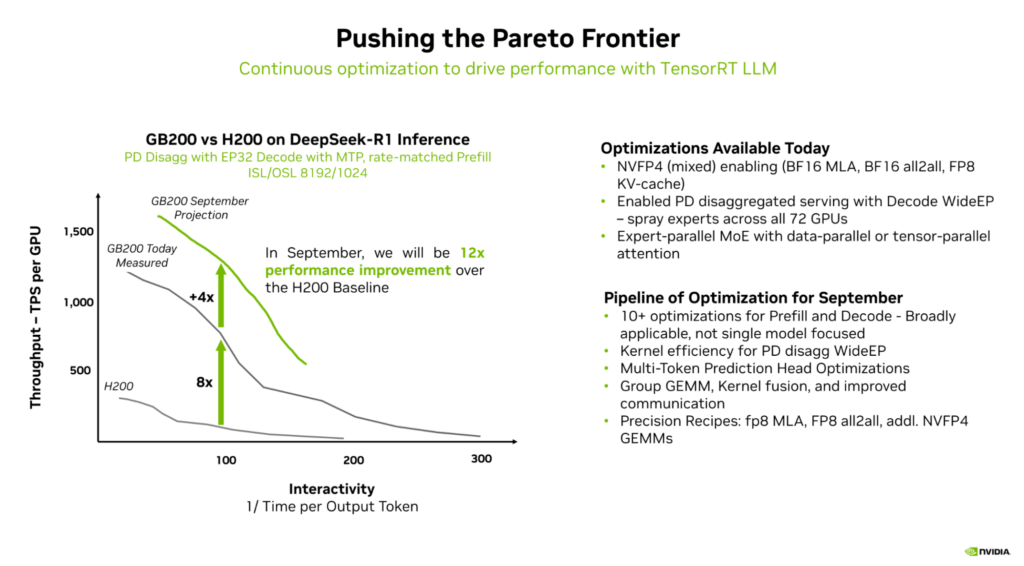
TensorRT LLM 性能突破:软硬件协同与评估维度
评估 TensorRT LLM 的核心价值,需重点关注其在推理性能极限上的突破能力,而这一突破依赖于对全堆栈优化机会的精准把握与软硬件协同优化。从 Hopper 架构到最新的 Blackwell 架构,NVIDIA 借助大型 NVLink 域、FP4 Tensor Cores 等硬件新技术,结合框架层面的模型分解服务,实现了软硬件能力的深度协同。
针对 NVIDIA 平台的优化过程中,这种协同设计让 Hopper 到 Blackwell 两代硬件的性能实现 8 倍提升。在分析性能前沿时,需重点关注两个关键维度:一是交互性(即用户体验),具体表现为 token 在终端用户屏幕上的传播速度,直接影响用户使用时的流畅感;二是系统产能,即单位时间内系统的 token 输出量,决定了系统的服务效率。通过软硬件协同优化,TensorRT LLM 可同时改善这两个维度的表现,真正突破 LLM 推理的性能极限,推动领域发展边界。

支撑易部署易扩展的三大核心特征
TensorRT LLM 之所以能实现易部署、易扩展的特性,并持续突破性能边界,核心依赖于三类关键技术特征的支撑。
第一类特征是针对 LLM 推理中最常见操作的优化内核,包括快速注意力内核、GEMM 内核、通信内核等,这些内核以 Torch 自定义操作的形式实现模块化封装,可直接在模型前向传递过程中调用,确保核心计算环节的高效性。
仅优化模型前向传递无法满足大规模部署的端到端性能需求,因此框架的第二类核心特征是提供高效运行时支持。该运行时集成了动态批处理、高级 KV Cache 重用、预测性解码、高级并行化等关键技术,能够从系统层面优化整体性能,而非局限于模型单一计算环节的提升。
第三类核心特征则是将所有技术能力封装至 Pythonic 框架中,开发者可直接在 PyTorch 环境中编写模型代码,同时通过 Python 运行时模块灵活自定义系统行为,既降低了使用门槛,又保留了足够的扩展灵活性,让不同技术背景的开发者都能高效利用框架能力。

快速启动并使用TensorRT LLM
为帮助开发者快速启动并使用 TensorRT LLM,框架提供了三种核心交互方式。首先,通过 TRT LLM serve CLI 工具,开发者可仅用一行代码启动服务器,该工具是框架内置的服务器实用程序,支持部署单个实例并提供与 OpenAI 兼容的模型端点,无需额外搭建复杂的服务架构,大幅降低基础部署门槛。
对于更大规模的部署场景,尤其是需要多实例编排的需求,开发者可借助 Dynamo 等工具实现高级数据中心规模优化。这类工具能提供实例间的智能调度、资源分配等能力,进一步提升系统的端到端性能,满足高并发、大规模的服务需求。
若开发者需要更灵活、稳定的 API 支持,框架推荐使用 LLM API。该 API 在 1.x 版本中保持接口稳定,能确保部署过程的稳定性与无缝性,同时支持各类自定义场景,无论是调整运行时参数还是集成自定义模块,都能通过 API 便捷实现,兼顾稳定性与灵活性。
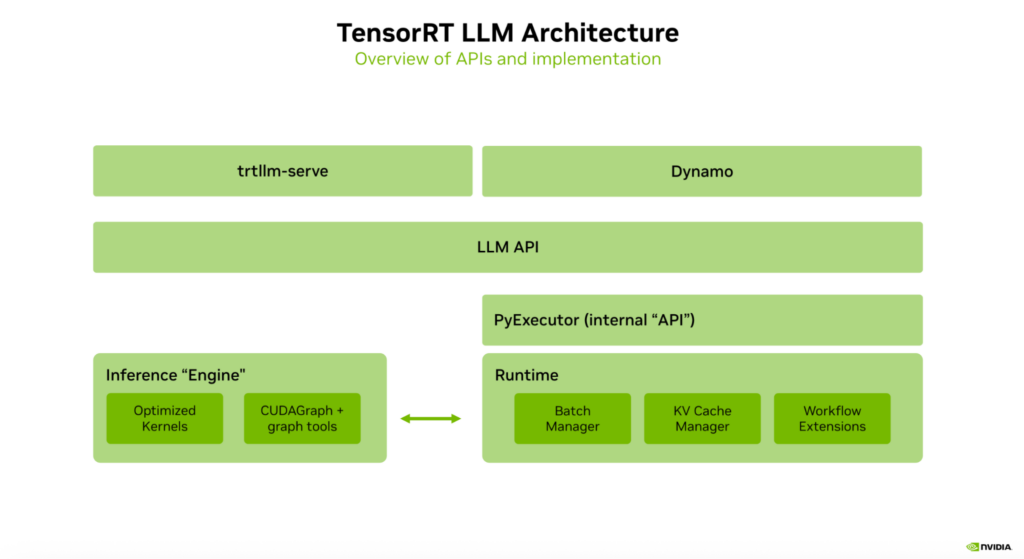
TensorRT LLM 系统架构层级解析
TensorRT LLM 的系统架构采用分层设计,清晰划分不同功能模块,便于开发者理解与使用。架构的第一层为服务层,该层包含 trtllm-serve 工具、Dynamo 等核心组件,同时支持开发者引入自定义服务层。这些服务层模块通常基于框架提供的 LLM API 构建,得益于 LLM API 的稳定性与功能完备性,服务层的开发与扩展无需过多关注底层实现细节,可快速搭建符合需求的服务体系。
针对高级用户,架构提供了 PyExecutor 组件,虽然该组件属于快速开发中的内部 API,但能直观体现系统的内部结构。PyExecutor 的核心由引擎与运行时两部分构成:引擎模块负责封装优化后的内核,并通过图形实用程序将这些内核组合为统一的引擎抽象,确保计算环节的高效调用;运行时模块则负责引擎的部署与管理,集成了批处理管理器、KV Cache 管理器、工作流扩展程序等组件,实现对推理流程的全生命周期管理。
TensorRT LLM 开源特性与社区协作支持
TensorRT LLM 采用完全开源的开发模式,所有开发过程均在 GitHub 上公开,开发者可实时查看最新代码变更与提交记录,便于跟踪框架演进方向。这种开源模式不仅支持开发者自由合并代码、调试问题,还能通过公开的 CI/CD 流程,让开发者自行测试贡献代码的兼容性与稳定性,确保 PR 合并的高效与可靠。
此外,GitHub 仓库中还设有专门的技术博客板块,详细解析框架中新技术与新创新的构建过程,例如内核优化思路、运行时设计逻辑等。这些内容不仅帮助开发者深入理解框架技术细节,还能为生态系统合作伙伴提供性能优化的参考,助力整个生态共同提升技术水平。
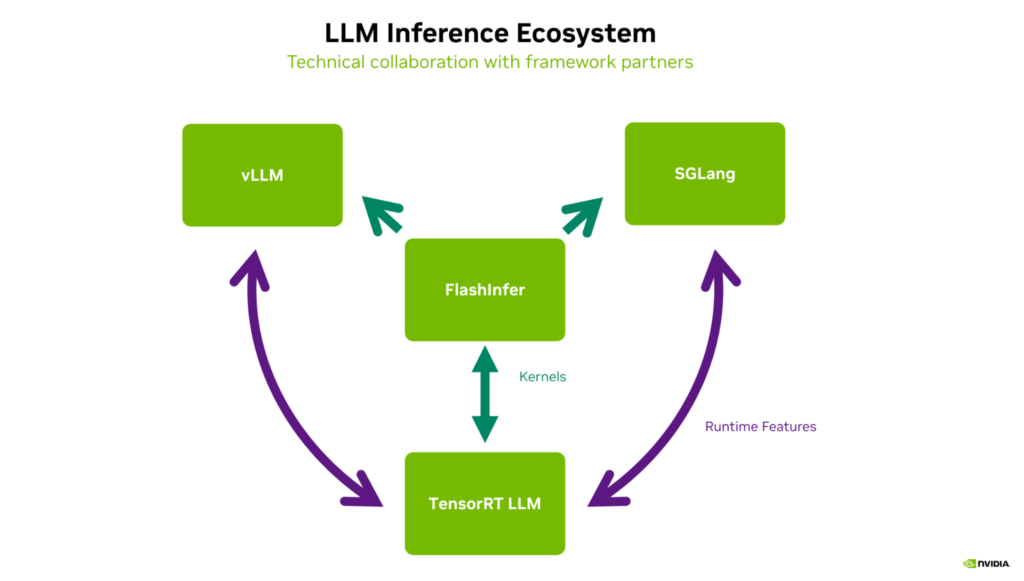
借助 Flashinfer 库实现内核级别的技术共享
为推动生态系统合作伙伴的性能提升,NVIDIA 围绕 TensorRT LLM 构建了两大核心技术路径。第一条路径是通过 GitHub 开源开发与技术博客实现技术透明与共享:开源模式让合作伙伴能直接获取框架核心代码与优化逻辑,技术博客则通过深度解析加速合作伙伴对新技术的理解与应用,两者结合确保技术成果能快速在生态中传播。
第二条路径是借助 FlashInfer 库实现内核级别的技术共享。NVIDIA 会将 TensorRT LLM 中的核心内核发布至 FlashInfer 库,该库作为优秀的开源项目,支持生态系统中的内核开发者自由自定义、修改内核,甚至贡献新的高级内核用于 LLM 推理。实际上,TensorRT LLM 中的诸多优化内核也常被提取至 FlashInfer 库,形成技术双向流动,既丰富了 FlashInfer 的能力,也让 TensorRT LLM 能持续吸收生态中的优秀内核成果。
TensorRT LLM 1.0 部署 GPT-OSS 模型
以 TensorRT LLM 1.0 部署 1200 亿参数的 GPT-OSS 模型为例,可直观了解框架的实战部署流程。首先,开发者需通过 trt-llm serve CLI 工具启动兼容 OpenAI 的模型端点,为确保部署后性能达到最优,需通过 config.yml 配置文件对系统关键组件进行参数设置,包括 KV Cache 的管理策略、预测解码的启用方式、内核的选择逻辑等,这些配置直接影响模型推理的效率与稳定性。
在模型头的处理上,开发者有两种选择:一是自行训练符合需求的模型头,适配特定业务场景;二是直接下载 NVIDIA 在 Hugging Face 平台上发布的预训练模型头,这类预训练模型头已针对 TensorRT LLM 做了优化,可快速投入使用,减少训练成本。除 GPT-OSS 模型外,框架还支持多种模型与场景的部署,更多详细指南可参考官方文档页面中的对应内容。

TensorRT LLM 1.0 模块化设计与请求处理逻辑
TensorRT LLM 1.0 在设计之初便深度融入模块化理念,这种设计不仅让框架易于扩展,还能确保各组件的职责清晰,便于维护与定制。从系统处理传入请求的逻辑可直观体现模块化优势:当请求进入系统后,首先会被调度至批量管理模块,该模块负责分配 KV Cache 资源并确保缓存的有效重用,减少重复计算;随后,系统会调用模型前向传递模块执行核心计算;最后,通过解码与采样逻辑生成最终结果并返回给用户。
整个请求处理流程中的每个组件均对应运行时的模块化单元,开发者可根据需求单独定制调整某一模块,无需修改整体架构。值得注意的是,模型前向通道基于原生 PyTorch 实现,这意味着开发者可从任意 Torch 实现的模型入手,仅需修改关键组件(如替换注意力层为优化版本)并完成系统注册,即可获得开箱即用的出色性能,大幅降低定制化开发的难度。

自定义模型实现:基于 PyTorch 的迁移与注册流程
对于需要基于 PyTorch 实现自定义模型的开发者,TensorRT LLM 提供了清晰的迁移与注册流程。首先,若开发者已拥有 Hugging Face 生态中的 Torch 建模代码,可直接将其引入 TensorRT LLM 系统,同时完成关键组件的注册,确保模型能与框架的运行时模块正常交互,启动基础推理功能。
接下来需完成三个核心步骤:第一步是定义模型配置,开发者可选择直接复用 Hugging Face 中的 config.json 文件,若模型为自定义架构,则需编写专属的 config.json,明确模型的结构参数与运行时需求;第二步是执行子模块替换,需将模型架构中的关键组件(如普通注意力层)替换为 NVIDIA 优化内核支持的 Torch 自定义操作,这类优化组件能显著提升 KV Cache 系统的性能,替换后需完成注册以确保框架能识别;第三步是模型权重加载,将训练好的模型检查点实际载入 TensorRT LLM 系统,完成权重与框架的适配。完成上述步骤后,开发者即可在本地部署中注册该自定义模型,后续无需频繁管理上游代码变更,确保模型运行的稳定性。

运行时定制:新调度策略的模块化实现方式
若开发者需要修改运行时行为(如实现新的调度策略以适配特定并发场景),TensorRT LLM 可通过模块化方式轻松实现。NVIDIA 为框架提供了基础的容量调度器类,该类定义了调度策略的核心接口与基础逻辑,开发者无需从零构建调度器,只需在 Python 环境中创建该类的子类,然后根据自定义需求覆盖任意相关方法(如请求分配逻辑、资源调度优先级等)即可。
在完成自定义方法的编写后,开发者仅需将该自定义容量调度器向系统注册,即可启动并应用新的调度策略,整个过程无需修改框架核心代码,也无需重新编译,充分体现了框架的灵活性与可扩展性。这种模块化的运行时定制方式,让开发者能快速适配不同业务场景的调度需求,提升系统在特定场景下的效率。
备注:本文内容及图片皆整理自此视频,欢迎观看完整直播回放以获取更多信息。
TensorRT LLM 1.0 现已在 GitHub 正式发布,欢迎下载体验:https://github.com/NVIDIA/TensorRT-LLM/releases/tag/v1.0.0
TensorRT LLM 快速入门指南:https://nvidia.github.io/TensorRT-LLM/1.2.0rc0/overview.html

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐



 30
30 0
0- 0



 已为社区贡献151条内容
已为社区贡献151条内容

所有评论(0)