
NVIDIA Nemotron Nano 2 及 Nemotron 预训练数据集 v1
Nemotron-CC-v2:此前研究表明,从高质量英文网页爬取数据生成的合成多样化问答数据,能显著提升大语言模型 (LLM) 通用能力(如 MMLU 等基准测试显示)。如“NVIDIA Nemotron Nano 2:准确、高效的混合 Mamba-Transformer 推理模型”技术报告所示,推理模型 NVIDIA-Nemotron-Nano-v2-9B 在复杂推理基准测试中,实现了与领先的同
NVIDIA 正式推出准确、高效的混合 Mamba-Transformer 推理模型系列 NVIDIA Nemotron Nano 2。您可复制链接至浏览器来试用该模型:
https://www.nvidia.cn/ai/
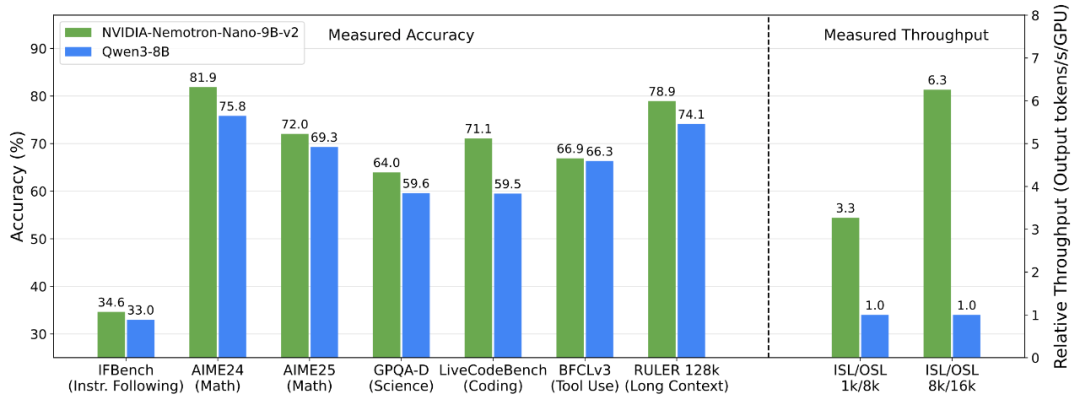
*图中,ISL 与 OSL 分别代表输入和输出序列长度,吞吐量数据均在单颗 NVIDIA GPU 上以 bfloat16 精度测得。
如“NVIDIA Nemotron Nano 2:准确、高效的混合 Mamba-Transformer 推理模型”技术报告所示,推理模型 NVIDIA-Nemotron-Nano-v2-9B 在复杂推理基准测试中,实现了与领先的同规模开源模型 Qwen3-8B 相当乃至更佳的准确率,吞吐量较后者至高提升 6 倍。
我们在 Hugging Face 上发布了以下三个模型,它们均支持 128K 上下文长度:
-
NVIDIA-Nemotron-Nano-9B-v2:经过对齐和剪枝的推理模型
-
NVIDIA-Nemotron-Nano-9B-v2-Base:经过剪枝的基础模型
-
NVIDIA-Nemotron-Nano-12B-v2-Base:未经过对齐或剪枝的基础模型
数据集
此外,作为行业领先开源模型的首次尝试,我们公开了在预训练中使用的大部分数据。
Nemotron-Pre-Training-Dataset-v1 数据集包含 6.6 万亿个 Token,涵盖高质量网络爬取、数学、代码、SFT 和多语言问答数据,分为以下四个类别:
-
Nemotron-CC-v2:基于 Nemotron-CC(Su 等人,2025 年)的后续版本,新增了 2024 至 2025 年间的八个 Common Crawl 快照数据集。数据集经过整体去重处理,并使用 Qwen3-30B-A3B 对其进行了合成重述。此外,该数据集还包含 15 种语言的合成多样化问答,可支持强大的多语言逻辑推理和通用知识预训练。
-
Nemotron-CC-Math-v1:一个以数学为重点的数据集,包含 1,330 亿个 Token。该数据集使用 NVIDIA Lynx + LLM 管线从 Common Crawl 中提取数据,在保留方程和代码格式的同时,将数学内容统一标准化为 LaTex 的编辑形式,确保了关键数学内容和代码片段完整无损,生成的预训练数据在基准测试中显著优于现有数学数据集。
-
Nemotron-Pretraining-Code-v1:基于 GitHub 构建的大规模精选代码数据集。该数据集经过多阶段去重、许可证强制执行和启发式质量检查过滤,包含 11 种编程语言的 LLM 生成代码问答对。
-
Nemotron-Pretraining-SFT-v1:覆盖 STEM、学术、逻辑推理和多语言领域的合成生成数据集。该数据集包含复杂的多选题和解析题,这些问题源自高质量数学和科学素材、研究生级的学术文本以及经过指令微调的 SFT 数据(涵盖数学、代码、通用问答和逻辑推理任务)。
-
Nemotron-Pretraining-Dataset-sample:数据集的精简采样版本,包含 10 个代表性子集,内容涵盖高质量问答数据、专注于数学领域的提取内容、代码元数据及 SFT 风格指令数据。
技术亮点
数据集的亮点包括:
-
Nemotron-CC-Math:通过文本浏览器 (Lynx) 渲染网页并结合大语言模型 (phi-4) 进行后处理,首次实现在大规模网页下正确保留各种数学格式的方程和代码的处理流程(包括长尾格式)。相较于过去基于启发式的方法,这是一次突破性改进。内部预训练实验表明,使用 Nemotron-CC-Math 数据集训练的模型在 MATH 测试上较最强基线提升了 4.8 至 12.6 分,在 MBPP+ 代码生成任务上提升了 4.6 至 14.3 分。
-
Nemotron-CC-v2:此前研究表明,从高质量英文网页爬取数据生成的合成多样化问答数据,能显著提升大语言模型 (LLM) 通用能力(如 MMLU 等基准测试显示)。在此基础上,我们通过将此数据集翻译成 15 种语言,把这一发现扩展到更多语言。消融实验显示,加入翻译过的多样化问答数据后,Global-MMLU 平均准确率比仅使用多语言 Common Crawl 数据提升了 10.0 分。
-
Nemotron-Pretraining-Code:除 1,751 亿个高质量合成代码数据 Token 外,我们还发布了元数据,使用户能够复现一个精心整理、宽松授权的代码数据集(规模达 7,474 亿 Token)。
模型的亮点包括:
-
预训练阶段:Nemotron-Nano-12B-v2-Base 采用 Warmup-Stable-Decay 学习率调度器在 20 万亿个 Token 上以 FP8 精度进行预训练。随后,通过持续的预训练长上下文扩展阶段,可在不降低其他基准性能的情况下支持 128k 上下文长度。
-
后训练阶段:Nemotron Nano 2 通过监督式微调 (SFT)、组相对策略优化 (GRPO)、直接偏好优化 (DPO) 和基于人类反馈的强化学习 (RLHF) 进行后训练。其中约 5% 的数据包含故意截断的逻辑推演,使推理时能够精细控制思考预算。
-
压缩:最后,我们对基础模型和对齐后的模型进行了压缩,使其能够在单颗 NVIDIA GPU (22 GiB 内存,bfloat16 精度) 上实现 128k Token 上下文长度的推理。此结果通过扩展基于 Minitron 的压缩策略以压缩受约束的逻辑推理模型实现。
更多详情,请参见以下技术报告和论文:
-
NVIDIA Nemotron Nano 2:准确、高效的混合 Mamba-Transformer 推理模型
https://research.nvidia.com/labs/adlr/files/NVIDIA-Nemotron-Nano-2-Technical-Report.pdf
-
Nemotron-CC-Math:1330 亿 Token 级高质量数学预训练数据集
https://research.nvidia.com/labs/adlr/files/NVIDIA-Nemotron-CC-Math.pdf
数据示例
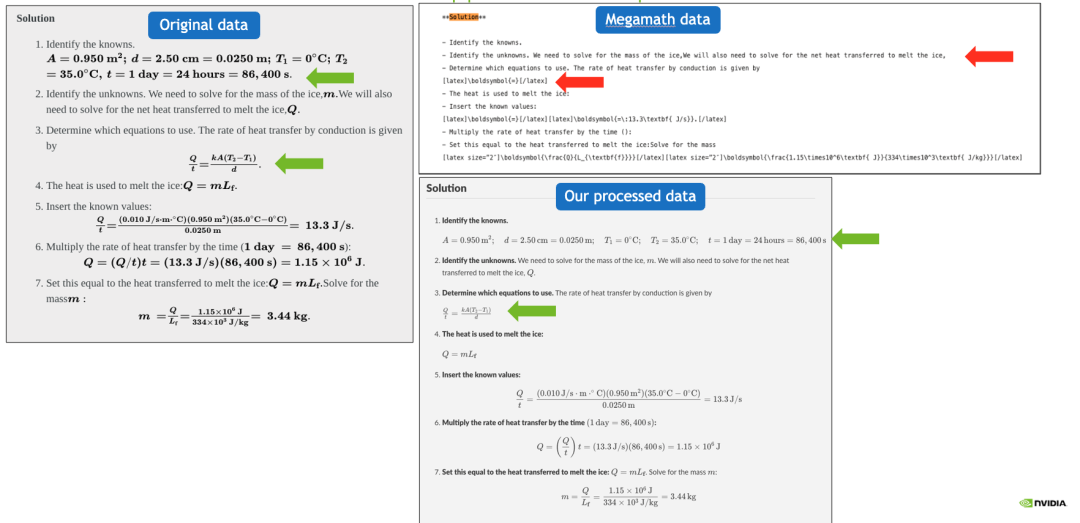
示例 1:我们的处理流程能够同时保留数学公式和代码,而之前的预训练数据集通常会丢失或损坏数学公式。
引用
@misc{nvidia2025nvidianemotronnano2,title={NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model},author={NVIDIA},year={2025},eprint={2508.14444},archivePrefix={arXiv},primaryClass={cs.CL},url={https://arxiv.org/abs/2508.14444},

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐

 16
16 0
0- 0



 已为社区贡献103条内容
已为社区贡献103条内容

所有评论(0)