
2025-08月 AI大模型论文精选 | 多模态大模型最新进展
【AI大模型研究精选摘要】 本期精选10篇AI大模型领域前沿研究,涵盖多模态模型优化、医疗应用及安全风险等方向: LVLM幻觉消除 《Analyzing and Mitigating Object Hallucination》提出POPEv2基准和Obliviate方法,通过调整语言建模头部参数,显著降低视觉语言模型(LVLM)的物体幻觉问题,参数量仅需更新2%。 医疗知识编辑基准 《MedMKE
我们从2025-08-06到2025-08-11的105篇文章中精选出10篇优秀的工作分享给读者,主要研究方向包括多模态模型幻觉,医学多模态模型,多模态融合等
-
Analyzing and Mitigating Object Hallucination: A Training Bias Perspective
-
MedMKEB: A Comprehensive Knowledge Editing Benchmark for Medical Multimodal Large Language Models
-
Beyond the Visible: Benchmarking Occlusion Perception in Multimodal Large Language Models
-
ECMF: Enhanced Cross-Modal Fusion for Multimodal Emotion Recognition in MER-SEMI Challenge
-
Can Large Multimodal Models Actively Recognize Faulty Inputs? A Systematic Evaluation Framework of Their Input Scrutiny Ability
-
MM-FusionNet: Context-Aware Dynamic Fusion for Multi-modal Fake News Detection with Large Vision-Language Models
-
Model Inversion Attacks on Vision-Language Models: Do They Leak What They Learn?
-
NEARL-CLIP: Interacted Query Adaptation with Orthogonal Regularization for Medical Vision-Language Understanding
-
PET2Rep: Towards Vision-Language Model-Drived Automated Radiology Report Generation for Positron Emission Tomography
-
Large Language Model Data Generation for Enhanced Intent Recognition in German Speech
1.Analyzing and Mitigating Object Hallucination: A Training Bias Perspective
Authors:Yifan Li, Kun Zhou, Wayne Xin Zhao, Lei Fang, Ji-Rong Wen
Affiliations: Renmin University of China; University of California, San Dieg; DataCanvas Alaya NeW
https://arxiv.org/abs/2508.04567
论文摘要
As scaling up training data has significantly improved the general multimodal capabilities of Large Vision-Language Models (LVLMs), they still suffer from the hallucination issue, generating text that is inconsistent with the visual input. This phenomenon motivates us to systematically investigate the role of training data in hallucination. We introduce a new benchmark, POPEv2, which consists of counterfactual images collected from the training data of LVLMs with certain objects masked. Through comprehensive evaluation on POPEv2, we find that current LVLMs suffer from training bias: they fail to fully leverage their training data and hallucinate more frequently on images seen during training. Specifically, they perform poorly on counterfactual images, often incorrectly answering Yes to questions about masked objects. To understand this issue, we conduct probing experiments on the models' internal components, revealing that this training bias is primarily located in the language modeling (LM) head, which fails to correctly translate accurate visual representations into textual outputs. Based on these findings, we propose Obliviate, an efficient and lightweight unlearning method designed to mitigate object hallucination via training bias unlearning. Obliviate identifies the discrepancy between ground-truth labels and model outputs on the training data as a proxy for bias and adopts a parameter- and data-efficient fine-tuning strategy that only updates the LM head. Extensive experiments demonstrate the effectiveness of our approach. While only reusing the training data and updating approximately 2% of the parameters, Obliviate significantly reduces hallucination across both discriminative and generative tasks. Furthermore, it demonstrates strong scalability with respect to both model size (2B to 72B) and training data volume, and exhibits promising generalization to hallucination types beyond object-level hallucination. Our code and data will be publicly released.
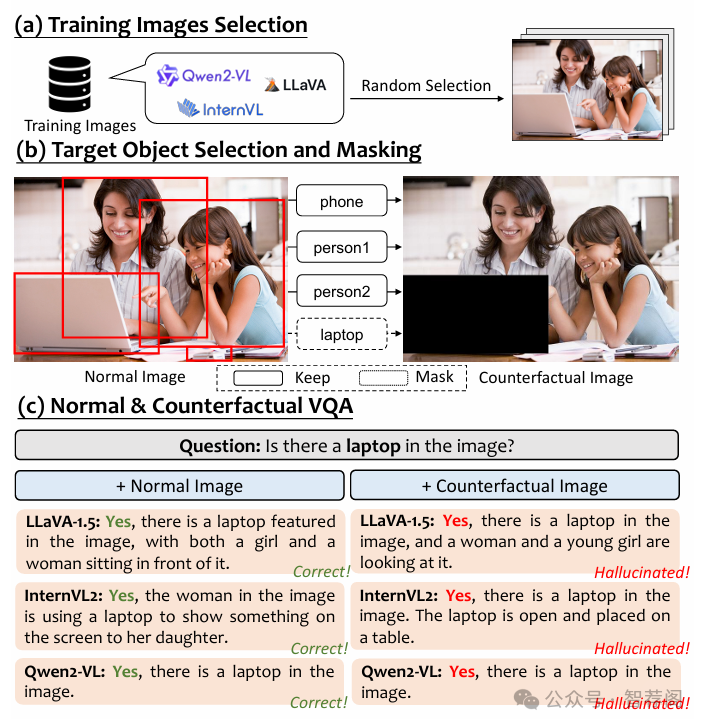
论文简评: 这篇关于大型视觉语言模型(Large Vision-Language Models, LVLMs)中的幻觉的研究论文,不仅深入探讨了幻觉在大型语言模型中出现的原因及其影响,还提出了一个新的评估指标——POPEv2,用于衡量训练数据对幻觉的影响程度。此外,作者通过实验验证了Obliviate方法的有效性,该方法旨在通过轻量级方式消除语言建模头中存在的偏见,从而有效防止幻觉的发生。论文整体结构清晰、逻辑性强,具有较高的研究价值。
2.MedMKEB: A Comprehensive Knowledge Editing Benchmark for Medical Multimodal Large Language Models
Authors:Dexuan Xu, Jieyi Wang, Zhongyan Chai, Yongzhi Cao, Hanpin Wang, Huamin Zhang, Yu Huang
Affiliations: Peking University; Peking University; China Academy of Chinese Medical Sciences
https://arxiv.org/abs/2508.05083
论文摘要
Recent advances in multimodal large language models (MLLMs) have significantly improved medical AI, enabling it to unify the understanding of visual and textual information. However, as medical knowledge continues to evolve, it is critical to allow these models to efficiently update outdated or incorrect information without retraining from scratch. Although textual knowledge editing has been widely studied, there is still a lack of systematic benchmarks for multimodal medical knowledge editing involving image and text modalities. To fill this gap, we present MedMKEB, the first comprehensive benchmark designed to evaluate the reliability, generality, locality, portability, and robustness of knowledge editing in medical multimodal large language models. MedMKEB is built on a high-quality medical visual question-answering dataset and enriched with carefully constructed editing tasks, including counterfactual correction, semantic generalization, knowledge transfer, and adversarial robustness. We incorporate human expert validation to ensure the accuracy and reliability of the benchmark. Extensive single editing and sequential editing experiments on state-of-the-art general and medical MLLMs demonstrate the limitations of existing knowledge-based editing approaches in medicine, highlighting the need to develop specialized editing strategies. MedMKEB will serve as a standard benchmark to promote the development of trustworthy and efficient medical knowledge editing algorithms.
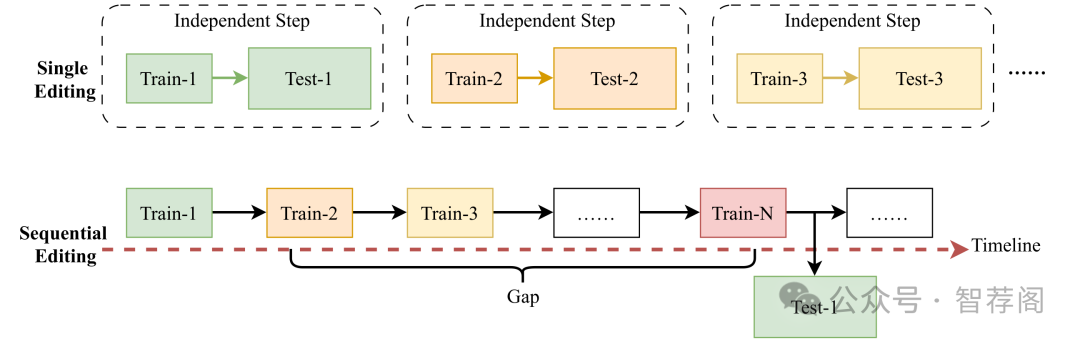
论文简评: MedMKEB是医学多模态大型语言模型(MLLMs)知识编辑评估基准,旨在解决医疗知识编辑中的独特挑战,如高精度和多模态复杂性,并提出一个全面的评估框架,涵盖可靠性、局部性、普遍性、可移植性和鲁棒性等指标。通过大量实验,证明了现有知识编辑方法在医疗领域的局限性。该研究不仅填补了相关领域中关于医疗MLLMs知识编辑评估的空白,还提供了丰富而实用的研究工具,对于推动这一领域的发展具有重要意义。

3.Beyond the Visible: Benchmarking Occlusion Perception in Multimodal Large Language Models
Authors:Zhaochen Liu, Kaiwen Gao, Shuyi Liang, Bin Xiao, Limeng Qiao, Lin Ma, Tingting Jiang
Affiliations: Peking University
https://arxiv.org/abs/2508.04059
论文摘要
Occlusion perception, a critical foundation for human-level spatial understanding, embodies the challenge of integrating visual recognition and reasoning. Though multimodal large language models (MLLMs) have demonstrated remarkable capabilities, their performance on occlusion perception remains under-explored. To address this gap, we introduce O-Bench, the first visual question answering (VQA) benchmark specifically designed for occlusion perception. Based on SA-1B, we construct 1,365 images featuring semantically coherent occlusion scenarios through a novel layered synthesis approach. Upon this foundation, we annotate 4,588 question-answer pairs in total across five tailored tasks, employing a reliable, semi-automatic workflow. Our extensive evaluation of 22 representative MLLMs against the human baseline reveals a significant performance gap between current MLLMs and humans, which, we find, cannot be sufficiently bridged by model scaling or thinking process. We further identify three typical failure patterns, including an overly conservative bias, a fragile gestalt prediction, and a struggle with quantitative tasks. We believe O-Bench can not only provide a vital evaluation tool for occlusion perception, but also inspire the development of MLLMs for better visual intelligence. Our benchmark will be made publicly available upon paper publication.

论文简评: O-Bench, the benchmark for evaluating occlusion perception in multimodal large language models (MLLMs), has been introduced in this paper. The paper presents a comprehensive dataset of 1,365 images and 4,588 question-answer pairs to assess the performance of MLLMs on occlusion tasks. The results reveal a significant performance gap between MLLMs and humans, indicating that they struggle with quantitative tasks despite being capable of generating coherent text. This study highlights the importance of incorporating real-world challenges into model training to improve their ability to understand context and generate meaningful responses. Overall, O-Bench serves as an essential resource for researchers and developers seeking to evaluate the effectiveness of MLLMs in various applications.
4.ECMF: Enhanced Cross-Modal Fusion for Multimodal Emotion Recognition in MER-SEMI Challenge
Authors:Juewen Hu, Yexin Li, Jiulin Li, Shuo Chen, Pring Wong
Affiliations: BIGAI
https://arxiv.org/abs/2508.05991
论文摘要
Emotion recognition plays a vital role in enhancing human-computer interaction. In this study, we tackle the MER-SEMI challenge of the MER2025 competition by proposing a novel multimodal emotion recognition framework. To address the issue of data scarcity, we leverage large-scale pre-trained models to extract informative features from visual, audio, and textual modalities. Specifically, for the visual modality, we design a dual-branch visual encoder that captures both global frame-level features and localized facial representations. For the textual modality, we introduce a context-enriched method that employs large language models to enrich emotional cues within the input text. To effectively integrate these multimodal features, we propose a fusion strategy comprising two key components, i.e., self-attention mechanisms for dynamic modality weighting, and residual connections to preserve original representations. Beyond architectural design, we further refine noisy labels in the training set by a multi-source labeling strategy. Our approach achieves a substantial performance improvement over the official baseline on the MER2025-SEMI dataset, attaining a weighted F-score of 87.49% compared to 78.63%, thereby validating the effectiveness of the proposed framework.
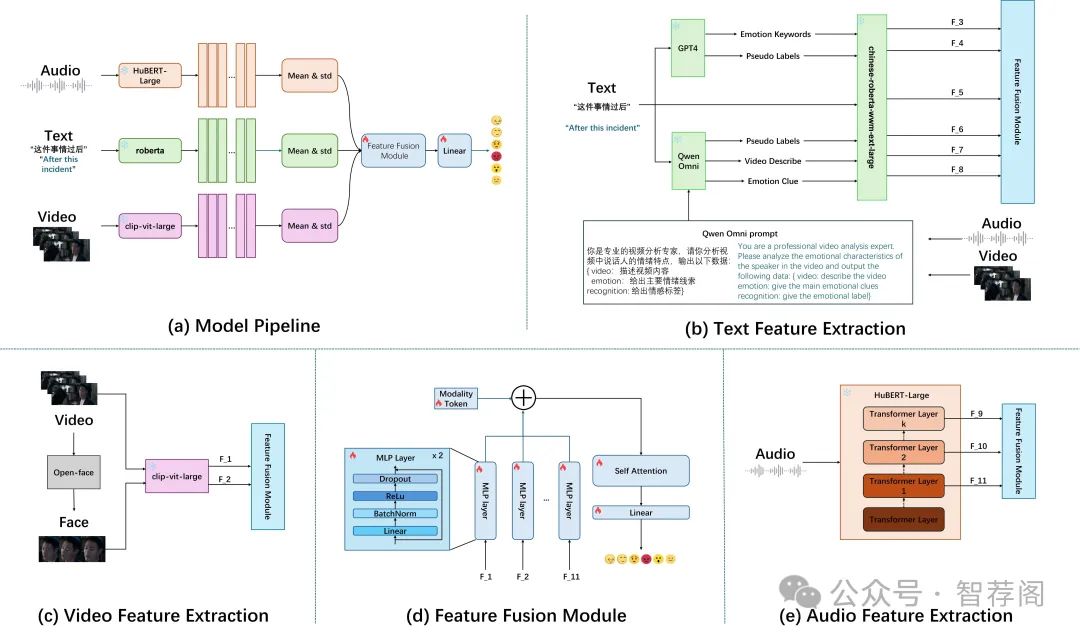
论文简评: 该篇论文提出了一种针对MER-SEMI挑战赛的新颖多模态情感识别框架,旨在利用预训练模型从音频、视觉和文本等多种模态中提取特征。它引入了一个双分支的视觉编码器,一种上下文丰富的方法用于文本,并采用了融合策略,其中自注意力机制发挥了重要作用。这种方法在性能上取得了显著的进步,其权重F-score达到了87.49%。与基准线相比,该方法实现了重大的性能提升,验证了提出的策略的有效性。通过使用预训练模型进行特征提取,该框架有效地解决了数据稀缺的问题;而双分支视觉编码器能够捕获全局和局部特征,提高视觉表示的质量;采用自注意力机制来动态地分配不同模态的重要性,增强了模型的鲁棒性;实验结果表明,这种改进后的框架在多项指标上表现出了明显的优势,进一步证实了其有效性。
5.Can Large Multimodal Models Actively Recognize Faulty Inputs? A Systematic Evaluation Framework of Their Input Scrutiny Ability
Authors:Haiqi Yang, Jinzhe Li, Gengxu Li, Yi Chang, Yuan Wu
Affiliations: Jilin University; Engineering Research Center of Knowledge-Driven Human-Machine Intelligence, MOE
https://arxiv.org/abs/2508.04017
论文摘要
Large Multimodal Models (LMMs) have witnessed remarkable growth, showcasing formidable capabilities in handling intricate multimodal tasks with exceptional performance. Recent research has underscored the inclination of large language models to passively accept defective inputs, often resulting in futile reasoning on invalid prompts. However, the same critical question of whether LMMs can actively detect and scrutinize erroneous inputs still remains unexplored. To address this gap, we introduce the Input Scrutiny Ability Evaluation Framework (ISEval), which encompasses seven categories of flawed premises and three evaluation metrics. Our extensive evaluation of ten advanced LMMs has identified key findings. Most models struggle to actively detect flawed textual premises without guidance, which reflects a strong reliance on explicit prompts for premise error identification. Error type affects performance: models excel at identifying logical fallacies but struggle with surface-level linguistic errors and certain conditional flaws. Modality trust varies-Gemini 2.5 pro and Claude Sonnet 4 balance visual and textual info, while aya-vision-8b over-rely on text in conflicts. These insights underscore the urgent need to enhance LMMs' proactive verification of input validity and shed novel insights into mitigating the problem. The code is available at this https URL.
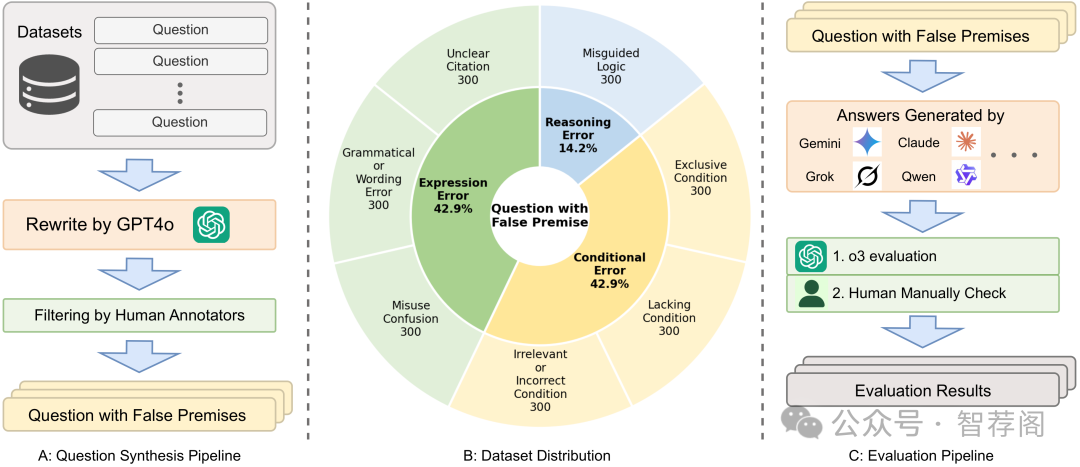
论文简评: 这篇关于大型多模态模型(Large Multimodal Models, LMMs)输入审查能力评估框架(Input Scrutiny Ability Evaluation Framework, ISEval)的研究论文是当前领域中的一项重要突破。该研究旨在评估大型多模态模型(如Transformer、BERT等)在识别错误输入方面的能力,并发现这些模型在主动检测输入错误时面临的挑战。通过引入ISEval框架,研究人员能够对各种类型的错误进行分类,并提供一种结构化的评估方法来衡量LMM的表现。
此外,通过对十种先进的LMM进行详细评估,研究人员揭示了它们在处理输入审查任务中的具体表现及其局限性。这项工作为未来改进LMM的输入审查功能提供了宝贵的见解和指导原则。总之,本文不仅填补了当前在LMM输入审查方面存在的知识空白,还提出了一个创新性的框架来系统地评估LMM在这一领域的性能,这对于推动相关技术的发展具有重要意义。
6.MM-FusionNet: Context-Aware Dynamic Fusion for Multi-modal Fake News Detection with Large Vision-Language Models
Authors:Junhao He, Tianyu Liu, Jingyuan Zhao, Benjamin Turner
Affiliations: Huaiyin Institute of Technology; Universidad Autonoma de Asuncion
https://arxiv.org/abs/2508.05684
论文摘要
The proliferation of multi-modal fake news on social media poses a significant threat to public trust and social stability. Traditional detection methods, primarily text-based, often fall short due to the deceptive interplay between misleading text and images. While Large Vision-Language Models (LVLMs) offer promising avenues for multi-modal understanding, effectively fusing diverse modal information, especially when their importance is imbalanced or contradictory, remains a critical challenge. This paper introduces MM-FusionNet, an innovative framework leveraging LVLMs for robust multi-modal fake news detection. Our core contribution is the Context-Aware Dynamic Fusion Module (CADFM), which employs bi-directional cross-modal attention and a novel dynamic modal gating network. This mechanism adaptively learns and assigns importance weights to textual and visual features based on their contextual relevance, enabling intelligent prioritization of information. Evaluated on the large-scale Multi-modal Fake News Dataset (LMFND) comprising 80,000 samples, MM-FusionNet achieves a state-of-the-art F1-score of 0.938, surpassing existing multi-modal baselines by approximately 0.5% and significantly outperforming single-modal approaches. Further analysis demonstrates the model's dynamic weighting capabilities, its robustness to modality perturbations, and performance remarkably close to human-level, underscoring its practical efficacy and interpretability for real-world fake news detection.
论文简评: 这篇论文是关于多模态假新闻检测的,主要探讨了如何利用大型视觉语言模型(LVLM)来解决这个问题。该框架,即MM-FusionNet,旨在通过引入双向跨模态注意力机制和动态模态门控网络,实现对文本和视觉特征的动态适应性权重调整。这种动态权重调整使得该方法能够根据上下文相关性有效地平衡文本和视觉信息。此外,作者还详细介绍了他们提出的新概念——Context-Aware Dynamic Fusion Module(CADFM),这是一种独特的多模态融合模块,它能够在不牺牲准确性的前提下提高检测器的性能。 总的来说,这篇文章提供了有关如何有效处理多模态假新闻问题的重要见解,并展示了如何利用大型视觉语言模型来解决这一挑战。通过对大规模数据集的深入研究,研究人员证明了他们的方法的有效性和实用性,进一步推动了多模态假新闻检测技术的发展。因此,可以说这篇论文具有重要的学术价值和应用前景。
7.Model Inversion Attacks on Vision-Language Models: Do They Leak What They Learn?
Authors:Ngoc-Bao Nguyen, Sy-Tuyen Ho, Koh Jun Hao, Ngai-Man Cheung
Affiliations: Singapore University of Technology and Design (SUTD)
https://arxiv.org/abs/2508.04097
论文摘要
Model inversion (MI) attacks pose significant privacy risks by reconstructing private training data from trained neural networks. While prior works have focused on conventional unimodal DNNs, the vulnerability of vision-language models (VLMs) remains underexplored. In this paper, we conduct the first study to understand VLMs' vulnerability in leaking private visual training data. To tailored for VLMs' token-based generative nature, we propose a suite of novel token-based and sequence-based model inversion strategies. Particularly, we propose Token-based Model Inversion (TMI), Convergent Token-based Model Inversion (TMI-C), Sequence-based Model Inversion (SMI), and Sequence-based Model Inversion with Adaptive Token Weighting (SMI-AW). Through extensive experiments and user study on three state-of-the-art VLMs and multiple datasets, we demonstrate, for the first time, that VLMs are susceptible to training data leakage. The experiments show that our proposed sequence-based methods, particularly SMI-AW combined with a logit-maximization loss based on vocabulary representation, can achieve competitive reconstruction and outperform token-based methods in attack accuracy and visual similarity. Importantly, human evaluation of the reconstructed images yields an attack accuracy of 75.31%, underscoring the severity of model inversion threats in VLMs. Notably we also demonstrate inversion attacks on the publicly released VLMs. Our study reveals the privacy vulnerability of VLMs as they become increasingly popular across many applications such as healthcare and finance.
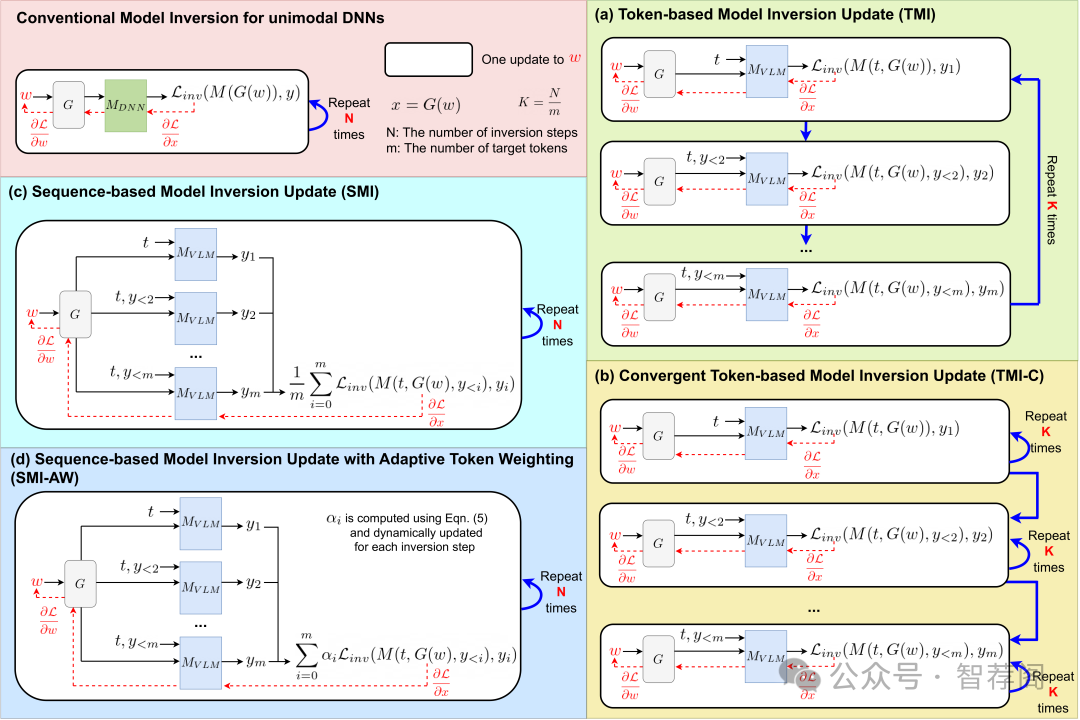
论文简评: 该论文旨在探讨视觉语言模型(VLM)对模式逆向攻击(Model Inversion Attack,MI)的脆弱性,并提出了一种基于令牌和序列的策略来重建训练图像从VLM中。作者通过多数据集和多种模型的实验,揭示了这些多模态系统存在的隐私风险,并证明了VLMs确实容易受到培训数据泄露的影响。这一发现对于理解视觉-语言模型面临的潜在威胁具有重要意义。此外,本文提出的针对VLM的MI策略不仅提供了新的视角,而且也表明了它们的有效性,这对于保护此类系统的安全性和隐私性至关重要。总的来说,这篇论文提供了一个关于如何有效防御视觉语言模型的MI攻击的重要洞见,其重要性和贡献不容忽视。
8.NEARL-CLIP: Interacted Query Adaptation with Orthogonal Regularization for Medical Vision-Language Understanding
Authors:Zelin Peng, Yichen Zhao, Yu Huang, Piao Yang, Feilong Tang, Zhengqin Xu, Xiaokang Yang, Wei Shen
Affiliations: Shanghai Jiao Tong University; Zhejiang University; Mohamed bin Zayed University of Artificial Intelligence; Chinese Academy of Science
https://arxiv.org/abs/2508.04101
论文摘要
Computer-aided medical image analysis is crucial for disease diagnosis and treatment planning, yet limited annotated datasets restrict medical-specific model development. While vision-language models (VLMs) like CLIP offer strong generalization capabilities, their direct application to medical imaging analysis is impeded by a significant domain gap. Existing approaches to bridge this gap, including prompt learning and one-way modality interaction techniques, typically focus on introducing domain knowledge to a single modality. Although this may offer performance gains, it often causes modality misalignment, thereby failing to unlock the full potential of VLMs. In this paper, we propose \textbf{NEARL-CLIP} (i\underline{N}teracted qu\underline{E}ry \underline{A}daptation with o\underline{R}thogona\underline{L} Regularization), a novel cross-modality interaction VLM-based framework that contains two contributions: (1) Unified Synergy Embedding Transformer (USEformer), which dynamically generates cross-modality queries to promote interaction between modalities, thus fostering the mutual enrichment and enhancement of multi-modal medical domain knowledge; (2) Orthogonal Cross-Attention Adapter (OCA). OCA introduces an orthogonality technique to decouple the new knowledge from USEformer into two distinct components: the truly novel information and the incremental knowledge. By isolating the learning process from the interference of incremental knowledge, OCA enables a more focused acquisition of new information, thereby further facilitating modality interaction and unleashing the capability of VLMs. Notably, NEARL-CLIP achieves these two contributions in a parameter-efficient style, which only introduces \textbf{1.46M} learnable parameters.
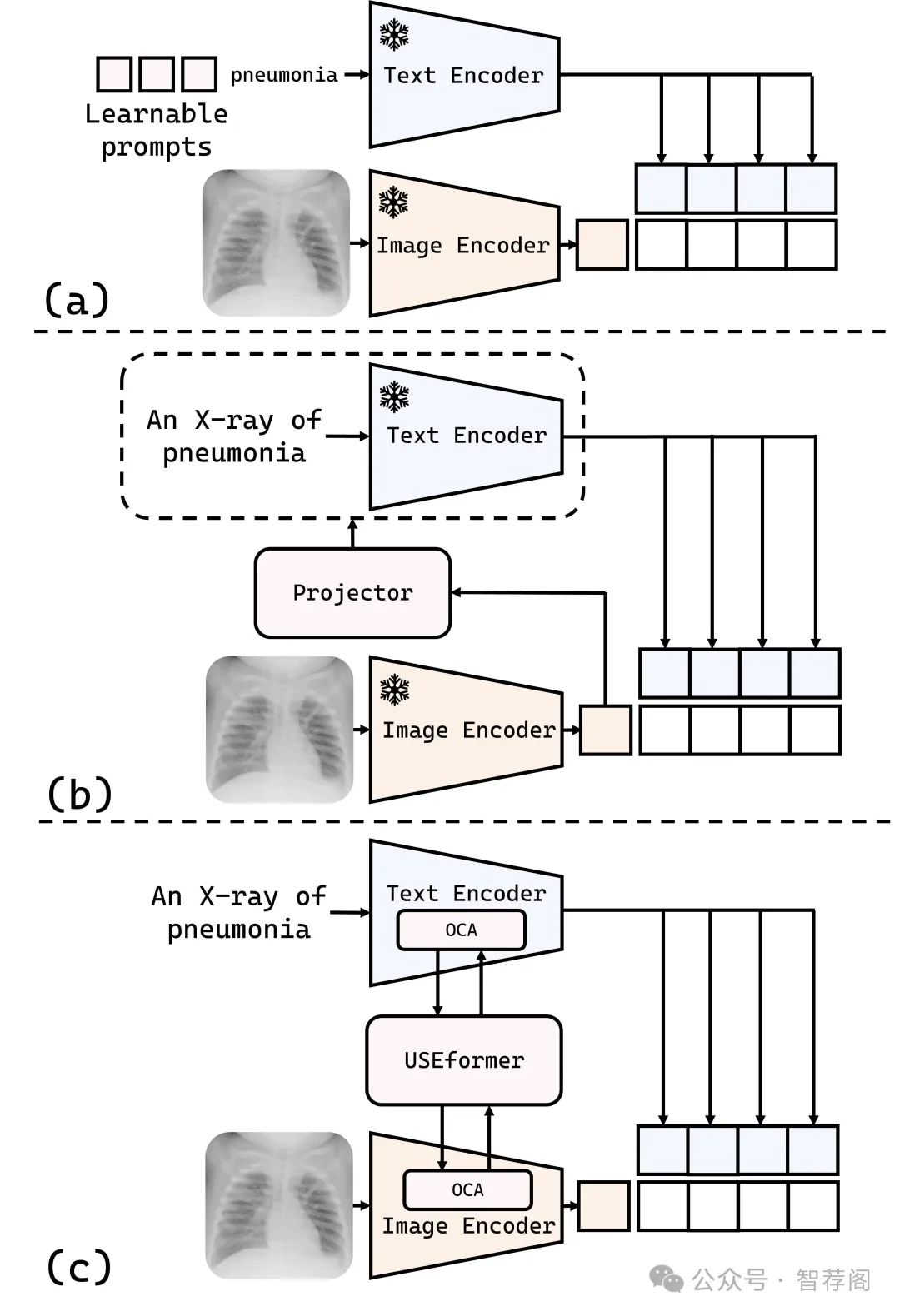
论文简评: 本文《NEARL-CLIP: A Framework for Enhancing Medical Vision-Language Understanding》提出了一个名为NEARL-CLIP的框架,旨在通过跨模态交互增强医疗视觉语言理解能力,从而解决医学影像任务中出现的领域差距问题。该文提出了一对核心组件:USEformer用于双向跨模态互动,以及OCA用于非线性特征分离,实现了多个医疗数据集上最佳性能。
本文的关键特点在于两个方面:一是提出的框架能够有效地利用模态间的双向互动;二是采用基于正交化约束的特征解耦策略,可以有效提升模型性能。实验结果表明,与现有方法相比,该方法取得了显著的性能改进,证明了其有效性。
综上所述,本文不仅提供了关于医疗视觉语言理解的最新进展,也展现了跨模态交互在解决领域挑战中的潜力。因此,它是一个值得关注的研究成果。
9.PET2Rep: Towards Vision-Language Model-Drived Automated Radiology Report Generation for Positron Emission Tomography
Authors:Yichi Zhang, Wenbo Zhang, Zehui Ling, Gang Feng, Sisi Peng, Deshu Chen, Yuchen Liu, Hongwei Zhang, Shuqi Wang, Lanlan Li, Limei Han, Yuan Cheng, Zixin Hu, Yuan Qi, Le Xue
Affiliations: Fudan University; Shanghai Academy of Artificial Intelligence for Science; Shanghai Universal Medical Imaging Diagnostic Center
https://arxiv.org/abs/2508.04062
论文摘要
Positron emission tomography (PET) is a cornerstone of modern oncologic and neurologic imaging, distinguished by its unique ability to illuminate dynamic metabolic processes that transcend the anatomical focus of traditional imaging technologies. Radiology reports are essential for clinical decision making, yet their manual creation is labor-intensive and time-consuming. Recent advancements of vision-language models (VLMs) have shown strong potential in medical applications, presenting a promising avenue for automating report generation. However, existing applications of VLMs in the medical domain have predominantly focused on structural imaging modalities, while the unique characteristics of molecular PET imaging have largely been overlooked. To bridge the gap, we introduce PET2Rep, a large-scale comprehensive benchmark for evaluation of general and medical VLMs for radiology report generation for PET images. PET2Rep stands out as the first dedicated dataset for PET report generation with metabolic information, uniquely capturing whole-body image-report pairs that cover dozens of organs to fill the critical gap in existing benchmarks and mirror real-world clinical comprehensiveness. In addition to widely recognized natural language generation metrics, we introduce a series of clinical efficiency metrics to evaluate the quality of radiotracer uptake pattern description in key organs in generated reports. We conduct a head-to-head comparison of 30 cutting-edge general-purpose and medical-specialized VLMs. The results show that the current state-of-the-art VLMs perform poorly on PET report generation task, falling considerably short of fulfilling practical needs. Moreover, we identify several key insufficiency that need to be addressed to advance the development in medical applications.
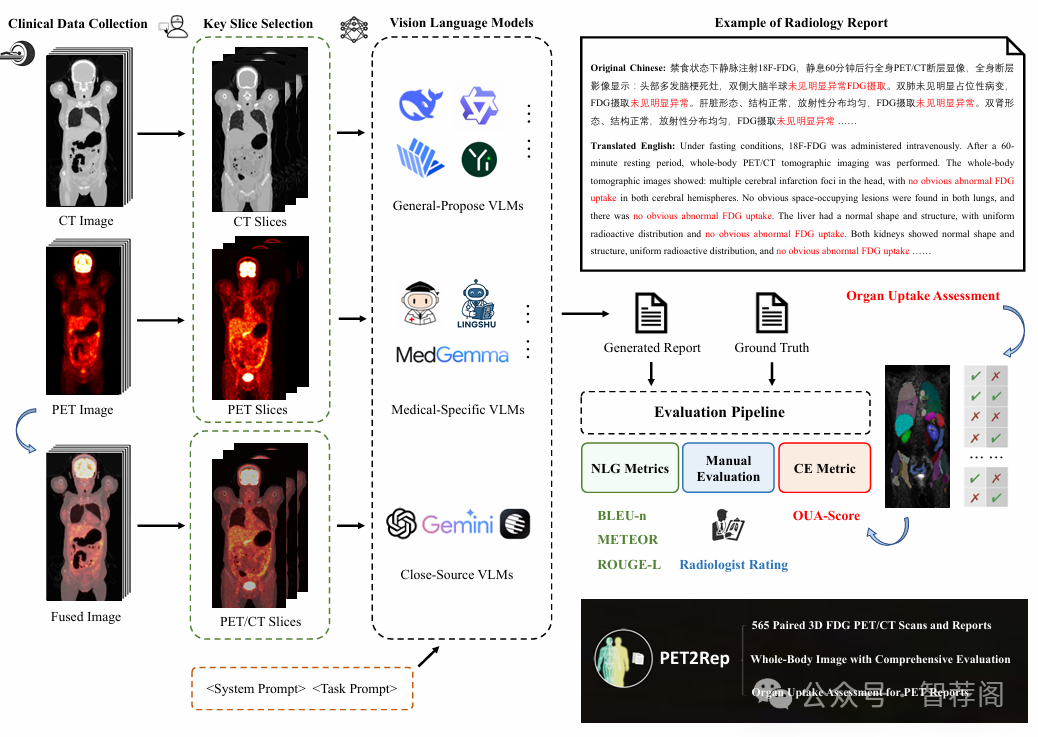
论文简评: 《PET2Rep:首次专用于PET报告生成的基准》这篇论文是关于评估视觉语言模型(VLM)在基于PET图像的放射学报告生成中的表现。它特别关注了PET成像的独特挑战,并提出了一组由565例病例组成的带标签数据集。作者对多种VLM进行了评估,揭示了它们在临床应用中难以产生相关报告的局限性,强调了进一步改进这一领域的必要性。
该文的主要贡献在于引入了PET2Rep这一专门针对PET报告生成的基准,填补了现有基准中缺乏专注于PET成像特性的空白。此外,通过对比不同类型的VLM的表现,论文深入分析了当前技术在实际应用中的不足之处,为未来的研究提供了有价值的参考框架。
总的来说,PET2Rep的出现对于推动视觉语言模型在医疗影像领域的发展具有重要意义,同时也促使研究人员更加注重解决实际问题和提升系统性能。通过提供一个专业的PET报告生成环境,这项研究有望促进跨学科合作,加速视觉语言模型在医学诊断领域的应用进程。
10.Large Language Model Data Generation for Enhanced Intent Recognition in German Speech
Authors:Theresa Pekarek Rosin, Burak Can Kaplan, Stefan Wermter
Affiliations: University of Hamburg- Knowledge Technology
https://arxiv.org/abs/2508.06277
论文摘要
Intent recognition (IR) for speech commands is essential for artificial intelligence (AI) assistant systems; however, most existing approaches are limited to short commands and are predominantly developed for English. This paper addresses these limitations by focusing on IR from speech by elderly German speakers. We propose a novel approach that combines an adapted Whisper ASR model, fine-tuned on elderly German speech (SVC-de), with Transformer-based language models trained on synthetic text datasets generated by three well-known large language models (LLMs): LeoLM, Llama3, and ChatGPT. To evaluate the robustness of our approach, we generate synthetic speech with a text-to-speech model and conduct extensive cross-dataset testing. Our results show that synthetic LLM-generated data significantly boosts classification performance and robustness to different speaking styles and unseen vocabulary. Notably, we find that \mbox{LeoLM}, a smaller, domain-specific 13B LLM, surpasses the much larger ChatGPT (175B) in dataset quality for German intent recognition. Our approach demonstrates that generative AI can effectively bridge data gaps in low-resource domains. We provide detailed documentation of our data generation and training process to ensure transparency and reproducibility.
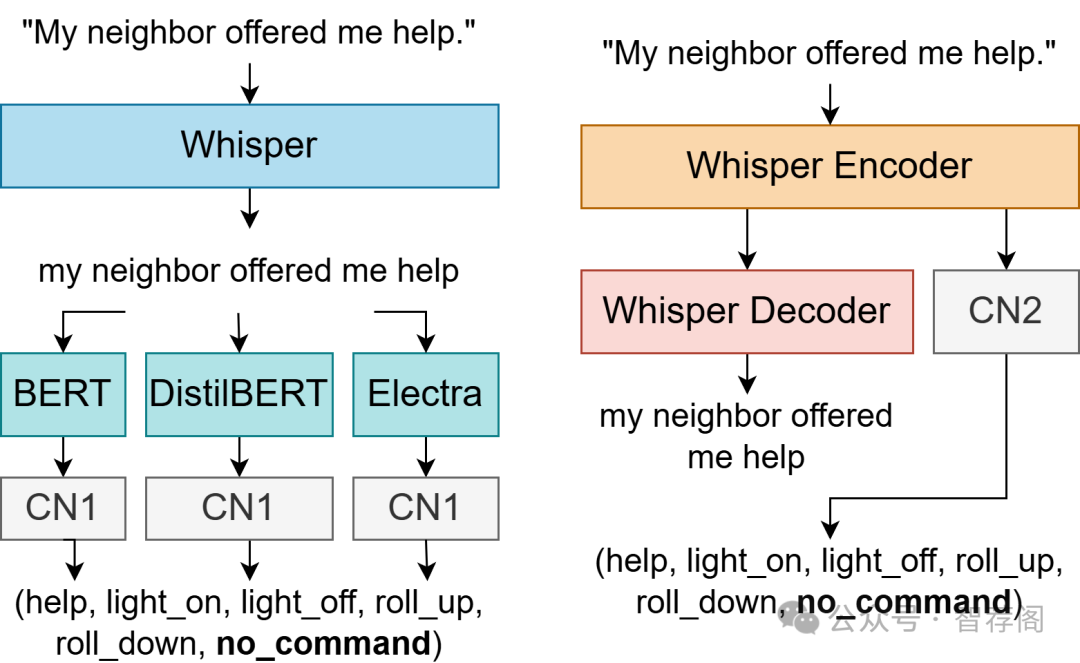
论文简评: 该篇论文提出了一个针对德语语音识别的新方法,特别关注老年用户,通过结合预训练的Whisper ASR模型与基于Transformer的语言模型(由大型语言模型生成的数据)进行训练。实验结果表明,生成的大规模语言模型数据显著提高了分类性能,并增强了对不同说话风格和未见过词汇的鲁棒性。该研究不仅填补了低资源领域的重大空白,而且展示了基于生成AI在非英语语言领域中的潜力。此外,通过对跨任务测试以及性能比较进行了全面评估,进一步验证了这一方法的有效性和实用性。综上所述,这篇论文为解决低资源领域内的语音识别问题提供了宝贵的经验和启示,具有重要的理论价值和应用前景。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份《LLM项目+学习笔记+电子书籍+学习视频》已经整理好,还有完整版的大模型 AI 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)