
解耦视觉编码以实现统一的多模态理解和生成
本文提出了Janus框架,通过解耦视觉编码路径来提升多模态理解与生成性能,并超越现有统一模型。论文题目: Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation论文链接: https://arxiv.org/abs/2410.10486PS: 欢迎大家扫码关注公众号^_^,我们一起在
解耦视觉编码以实现统一的多模态理解和生成
原创 hanscalZheng AI大模型学习基地 2024年11月22日 14:12 上海
本文提出了Janus框架,这是一种统一的多模态理解与生成模型,旨在通过解耦视觉编码路径来提升性能。与以往依赖单一视觉编码器的多模态模型不同,Janus为多模态理解和生成任务分别设计了独立的视觉编码器,同时使用统一的Transformer架构进行处理。这种设计不仅缓解了两类任务对视觉表示需求的冲突,还提高了模型的灵活性和扩展性。实验表明,Janus在多个基准测试中超过了现有的统一模型,并且在某些情况下表现优于专门为特定任务设计的模型,展示了它作为下一代多模态模型的潜力。

1 多模态框架Janus
Janus框架通过解耦视觉编码,将多模态理解和生成任务分开处理。理解任务使用高维语义特征,而生成任务则专注于细粒度的空间结构和纹理细节。两者通过统一的Transformer架构连接,从而避免了同一视觉编码器处理两类任务时的冲突。Janus框架设计简单灵活,可以扩展到处理其他输入类型,如点云、脑电图或音频数据。

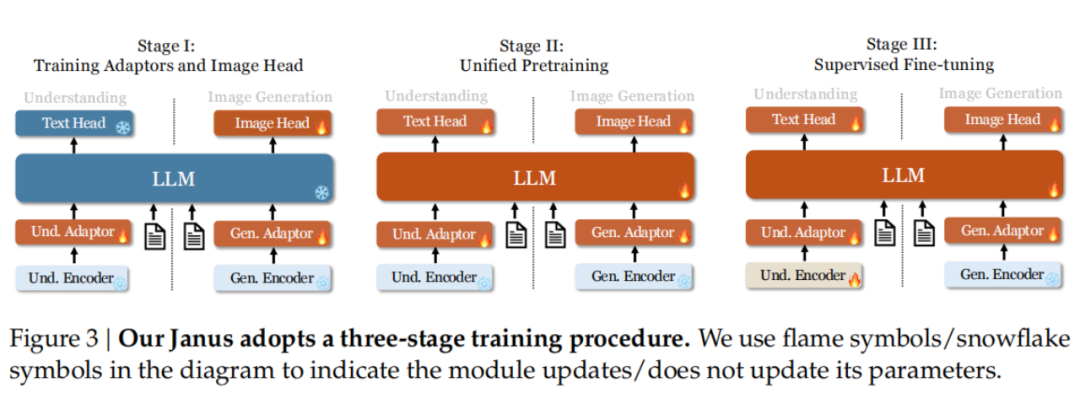
Janus采用自回归模型,训练过程中使用交叉熵损失,在推理阶段,Janus模型采用逐步预测的方式完成文本理解和视觉生成任务。其训练过程分为三个阶段:
-
阶段1:训练理解和生成任务的适配器以及图像生成头部,保持视觉编码器和语言模型的参数冻结 。
-
阶段2:统一预训练,包括多模态理解和生成数据 。
-
阶段3:监督微调,结合指令调优以提升多模态任务的性能 。
2 结语
本文提出了Janus框架,通过解耦视觉编码路径来提升多模态理解与生成性能,并超越现有统一模型。
论文题目: Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
论文链接: https://arxiv.org/abs/2410.10486
PS: 欢迎大家扫码关注公众号^_^,我们一起在AI的世界中探索前行,期待共同进步!
精彩回顾

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐



 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)