
【阅读笔记2】一种基于决策层融合的多模态情感识别方法
多模态情感识别(语音、面部)。通过梅尔频率倒谱系数与卷积神经网络对情感进行识别分类,同时将语音情感识别迁移到神经网络计算棒以降低环境负载。在模态融合时,采用决策层融合的方式来提高识别准确率。(1)提取梅尔倒谱系数,使用AlexNet卷积神经网络进行训练,将训练后的网络迁移至神经网络计算棒,后续通过OpenVINO推理引擎进行情感识别。(2)通过OpenCV进行人脸检测,输入卷积神经网络来识别情感。
一种基于决策层融合的多模态情感识别方法,韩天翊,林荣恒
介绍
结构
结果
介绍
多模态情感识别(语音、面部)。通过梅尔频率倒谱系数与卷积神经网络对情感进行识别分类,同时将语音情感识别迁移到神经网络计算棒以降低环境负载。在模态融合时,采用决策层融合的方式来提高识别准确率。
(1)提取梅尔倒谱系数,使用AlexNet卷积神经网络进行训练,将训练后的网络迁移至神经网络计算棒,后续通过OpenVINO推理引擎进行情感识别。
(2)通过OpenCV进行人脸检测,输入卷积神经网络来识别情感。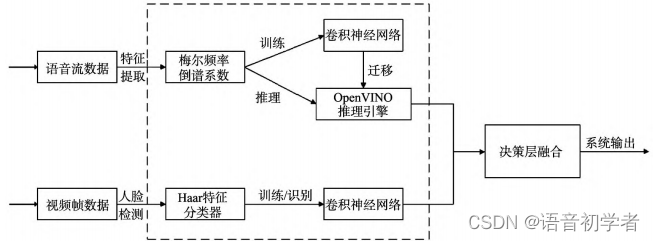
结构
单模态识别后可分别得到由语音和视频识别的结果,然后进行决策层融合。
本文中决策层融合采用加权求和的方式: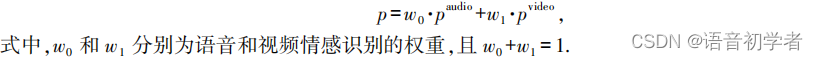
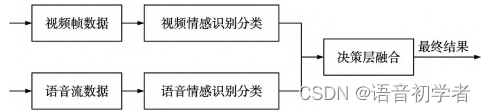
结果
系统对开心、生气与正常3种表情进行识别。
语音识别模型使用营业厅通话录音作为数据集。 数据集按照8:2的比例随机划分为训练集与测试集。使用测试集对语音模型测试,其分类准确度为74.5%。
视频模型的数据集结合了Fer2013、CK+和 GENKI 数据集,训练集和测试集按8:2进行划分,使用支持向量机和深度神经网络作为基线算法. 实验结果如表所示,卷积神经网络识别准确率为78.62%,召回 率77.98%,优于支持向量机和深度神经网络的识别准确率。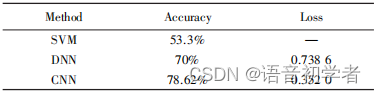

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐

 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)