
利用 NVIDIA Aerial Omniverse 数字孪生精准模拟无线电环境
接下来,为基站(RU)和用户设备(UE)定义天线面板。可以采用如 ThreeGPP38901 等标准模型,也可自定义模型。

5G 和 6G 的发展需要高保真无线电信道建模,但当前生态系统高度分散。链路级模拟器、网络级模拟器与 AI 训练框架通常采用不同的编程语言,独立运行。
如果您是致力于模拟 5G 或 6G 系统物理层关键组件行为的研究人员或工程师,本教程将指导您如何扩展仿真链路,并集成由 Aerial Omniverse 数字孪生 (AODT) 生成的高保真信道模型。
预备知识:
- 硬件: NVIDIA RTX GPU(建议采用 Ada 架构或更新架构以获得更优性能)。
- 软件: 访问 AODT 版本 1.4 容器。
- 知识: 基本熟悉 Python 及无线网络概念,例如无线电单元(RU)和用户设备(UE)。
AODT 通用嵌入式服务架构
图 1 展示了如何将 AODT 嵌入到任意仿真链中,无论该仿真链使用的是 C++、Python 还是 MATLAB。
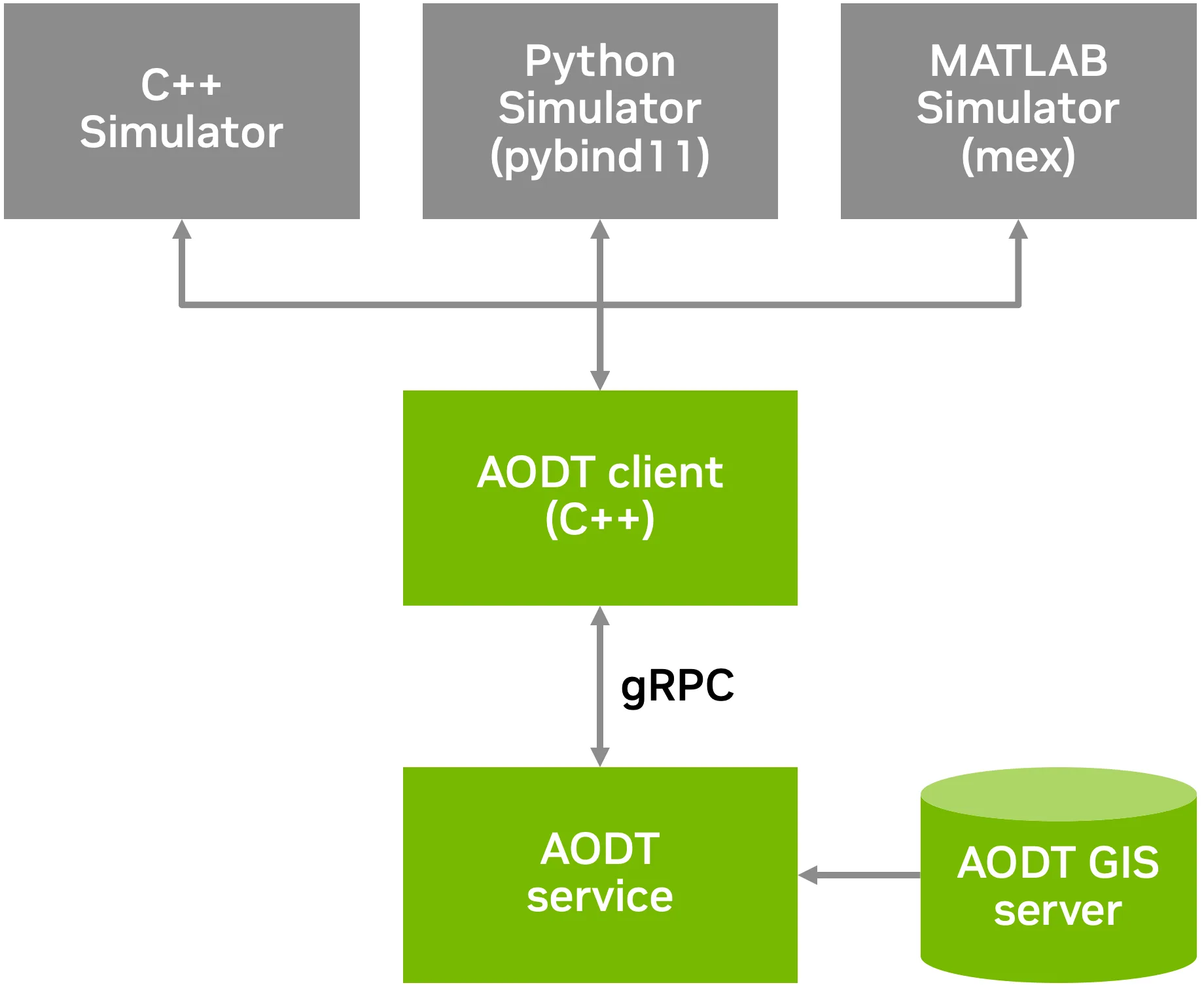
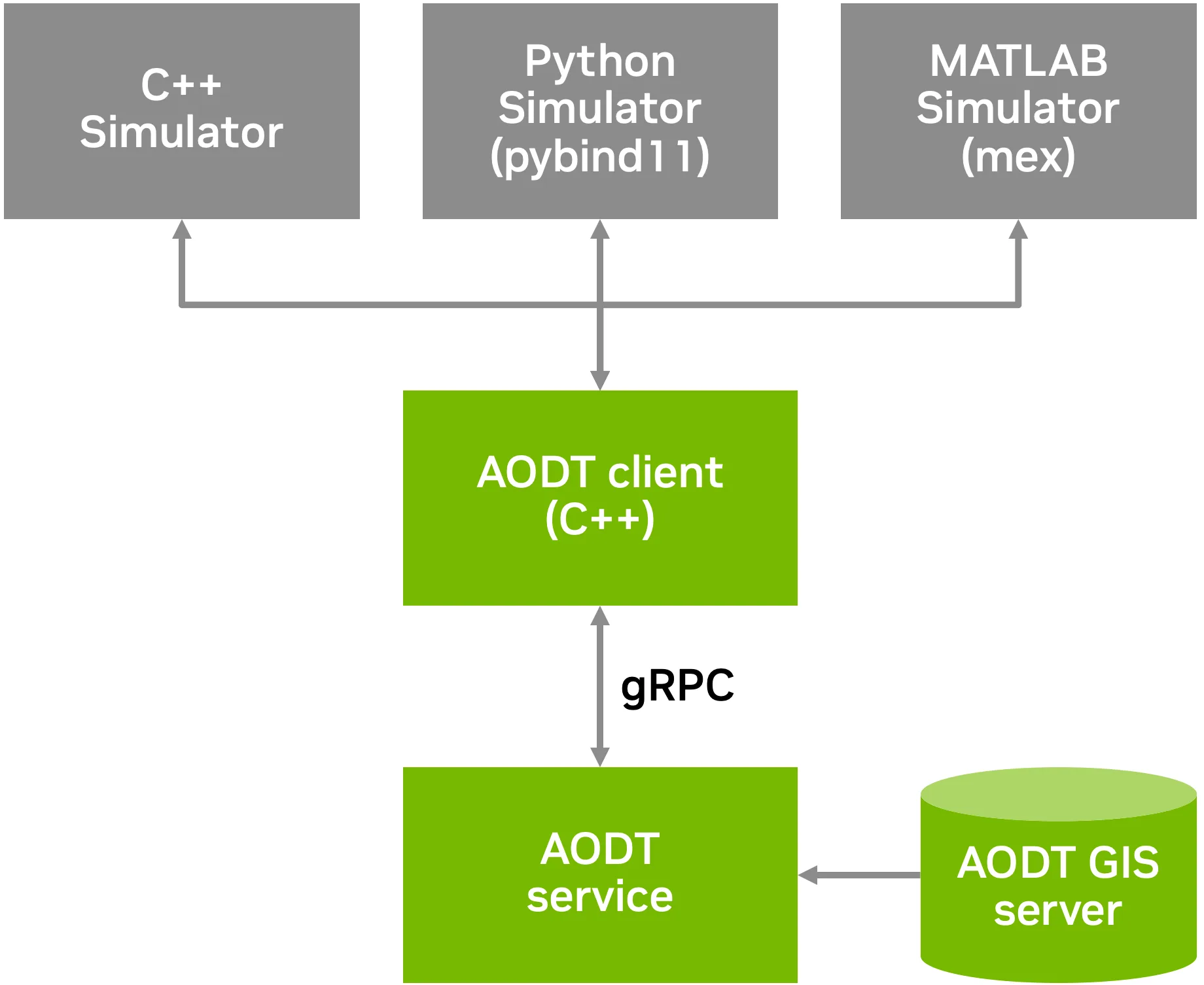
图 1。AODT 通过高性能 gRPC 实现通用嵌入式服务
AODT 分为两个主要组成部分:
- AODT 服务充当集中式、高功率计算核心,负责管理和加载大型 3D 城市模型(例如来自 Omniverse Nucleus 服务器的模型),并执行所有复杂的电磁(EM)物理计算。
- AODT 客户端及语言绑定提供轻量级的开发者接口,客户端处理全部服务调用,并通过 GPU IPC 高效传输数据,实现对无线电信道输出的直接 GPU 显存访问。为支持广泛的开发环境,AODT 客户端提供通用语言绑定,可直接用于 C++、Python(通过
pybind11)以及 MATLAB(通过用户实现的mex)。
工作流程的实际应用:通过 7 个简单步骤计算信道脉冲响应
那么,您实际将如何使用它呢?整个工作流程设计简洁,遵循由客户端编排的精确序列,如图 3 所示。


图 2。AODT 客户端/ 服务工作流程摘要
该过程分为两个主要阶段:
- 配置指定 AODT 要模拟的内容。
- 执行运行仿真以获取数据。
请遵循完整示例:
第 1 阶段:配置 (构建 YAML 字符串)
AODT 服务通过单个 YAML 字符串进行配置。您可手动编写该字符串,同时也可使用功能强大的 Python API 来以编程方式逐步构建配置内容。
第 1 步。初始化仿真配置
首先,导入配置对象并设置基本参数:要加载的场景、仿真模式(例如 SimMode.EM)、要运行的插槽数,以及用于生成可重复且确定性结果的种子。
|
|
第 2 步:定义天线阵列
接下来,为基站(RU)和用户设备(UE)定义天线面板。可以采用如 ThreeGPP38901 等标准模型,也可自定义模型。
|
|
第 3 步:部署网络组件(RU 和手动 UE)
将网络元素置于场景中,我们采用地理参考坐标(纬度/经度)进行精确定位。对于 UE,可定义一系列路标以生成预设路径。
|
|
第 4 步:部署动态元素(程序化生成与散布器)
这就是仿真真正变得动态的地方。您可以定义 spawn_zone,让 AODT 在该区域内程序化地生成具有逼真移动行为的 UE,而无需手动放置每一个 UE。此外,您还可以启用 urban_mobility,以引入动态散射器(如汽车),这些散射器能与无线电信号发生物理交互并影响信号传播。
|
|
第 2 阶段:执行 (客户端 – 服务器交互)
现在我们有了 yaml_string 配置,便可以连接到 AODT 服务并运行仿真。
第 5 步:连接
导入 dt_client 库,创建指向服务地址的客户端,并调用 client.start(yaml_string)。通过这一调用,可将完整配置发送至服务端,随后服务将加载 3D 场景、生成所有对象并准备仿真。
|
|
启动后,您可以查询服务以获取刚刚创建的仿真参数,从而确认一切已准备就绪,并了解预期的插槽、RU 和 UE 数量。
|
|
第 6 步:获取 UE 位置
|
|
第 7 步:检索通道脉冲响应
现在,我们遍历每个模拟插槽,可以在其中获取所有 UE 的当前位置。这对于验证移动模型是否按预期运行,以及将信道数据与位置信息关联起来至关重要。
检索核心仿真数据是至关重要的一步。通道脉冲响应 (CIR) 描述了信号如何从每个 RU 传播到每个 UE,包括所有多路径组件 (其延迟、振幅和相位)。
为/ 从/at 检索大量数据?每个插槽都会变慢。为加快速度,API 采用 IPC 的零复制两步流程。
首先,在循环开始前,您需要请求客户端为 CIR 结果分配 GPU 显存。该服务将执行此操作,并返回一个 IPC 句柄,即指向该 GPU 显存的指针。
|
|
现在,在循环中,您可以调用 client.get_cirs(…),并传入这些内存句柄。AODT 服务会为该插槽执行完整的 EM 模拟,并将结果直接写入共享的 GPU 显存中,无需通过网络复制任何数据,因此效率非常高。客户端将立即收到通知,表明新数据已准备就绪。
|
|
访问 NumPy 中的数据
数据(CIR 值和延迟)仍驻留在 GPU 上。客户端库提供了简单的实用工具,可获取 GPU 指针,同时避免引入额外延迟。为便于使用,也支持通过 NumPy 访问这些数据,具体可通过以下代码实现。
|
|
就是这样!仅用几行 Python 代码,您便已配置了一个复杂、动态且具备地理参考的模拟,该模拟将在功能强大的远程服务器上运行,并将基于物理特性的高保真 CIR 以 NumPy 数组的形式返回。现在,这些数据可用于可视化、分析,或直接输入到 AI 训练管线中。例如,我们可以利用以下图形函数,可视化前述手动声明的 UE 频率响应。
|
|


图 3。所考虑示例的极化频率响应特性
助力 AI 原生 6G 时代
从 5G 到 6G 的过渡必须应对无线信号处理中日益复杂的问题,其特点是数据量庞大、异质性显著,以及 AI 原生网络成为核心任务。传统的孤立模拟方法难以胜任这一挑战。
NVIDIA Aerial Omniverse 数字孪生专为这一新时代而打造。通过在版本 1.4 中迁移到基于 gRPC 的服务架构,AODT 正在推动基于物理的无线电仿真普及,并为机器学习与算法探索提供所需的地面实况数据。
AODT 1.4 可在 NVIDIA NGC。我们诚邀研究人员、开发者和运营商集成这一强大的新服务,携手共建 6G 的未来。

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐



 24
24 0
0- 0



 已为社区贡献142条内容
已为社区贡献142条内容

所有评论(0)