
YOLOv13最新创新改进系列:多模态识别正式开始!
YOLOv13最新创新改进系列:多模态识别正式开始!
YOLOv13最新创新改进系列:多模态识别正式开始!
购买相关资料后畅享一对一答疑!
详细的改进教程以及源码,戳这!戳这!!戳这!!!B站:AI学术叫叫兽 源码在相簿的链接中,动态中也有链接,感谢支持!祝科研遥遥领先!
原文戳这里!
摘要
在低光照环境下进行目标检测是一项具有挑战性的任务,因为物体在RGB图像中通常不清晰可见。由于红外图像提供了补充RGB图像的清晰边缘信息,融合RGB和红外图像有潜力增强低光照环境下的检测能力。然而,现有涉及可见光和红外图像的工作仅关注图像融合,而非目标检测。此外,它们直接融合了两种图像模态,忽略了它们之间的相互干扰。为了融合两种模态以最大化跨模态的优势,我们设计了一种基于双增强的跨模态目标检测网络DEYOLO,其中设计了语义-空间跨模态和新型双向解耦聚焦模块,以实现以检测为中心的RGB-红外(RGB-IR)相互增强。具体而言,首先提出了双语义增强通道权重分配模块(DECA)和双空间增强像素权重分配模块(DEPA),以在特征空间中聚合跨模态信息,从而提高特征表示能力,使得特征融合能够针对目标检测任务。同时,在DECA和DEPA中设计了一种双增强机制,包括对双模态融合和单模态的增强,以减少两种图像模态之间的干扰。然后,开发了一种新型双向解耦聚焦模块,以在不同方向上扩大骨干网络的感受野,从而提升DEYOLO的表示质量。在M3FD和LLVIP数据集上的大量实验表明,我们的方法明显优于现有的最先进目标检测算法。
关键词:目标检测 · 可见光-红外 · 双增强
1.引言
作为计算机视觉的一项基本任务,复杂场景中的目标检测仍然面临各种挑战。由于可见光的波长范围有限,在光照条件较差(如浓烟)的复杂环境中难以获取目标信息。为了解决这一问题,红外信息被广泛引入。然而,由于红外图像质量较低,普通检测器难以从中提取有用的纹理和颜色信息。因此,仅依靠红外图像难以单独支持检测任务。
相比之下,利用可见光-红外图像的跨模态互补信息可以提高目标检测的性能。常用的方法采用融合与检测策略,即图像融合网络使用目标检测结果作为验证指标。然而,融合与检测方法存在一些不足。首先,双模态图像的融合并不专注于目标检测任务。其次,其冗余的模型结构(例如,分别用于融合和检测的两个独立模型)也增加了训练成本。第三,尽管红外(IR)图像在结构信息上丰富,但其缺点是缺乏纹理。因此,融合模型通常专注于丰富纹理信息,同时消除目标的复杂亮度信息。相反,它们很少考虑两种模态图像之间的相互干扰。例如,在融合过程中,红外图像可能会抵消可见光的成像质量。仅进行直接的图像对融合而不进行跨模态增强,不足以提高目标检测性能。
大多数现有的RGB-IR检测模型要么构建四通道输入,要么将RGB图像和红外图像分别保持在两个独立的分支中,并在下游合并它们的特征。这些多模态信息融合策略在一定程度上提升了检测性能。然而,我们认为这些方法中两种模态之间的交互不足。单模态图像的处理与特征融合之间存在明显的界限,导致跨模态信息的利用不够充分。此外,它们缺乏在通道和空间维度上的复合交互,忽视了语义信息和结构信息之间的潜在关系。
为此,我们提出了一种跨模态特征融合方法,用于在检测任务中双重增强可见光和红外图像的特征图。这种增强策略能够从不同尺度引导双模态特征的融合过程,以确保特征信息的完整性和最优信息提取。针对目标检测,我们设计了DECA和DEPA,分别用于丰富特征图中的语义和结构信息。此外,为了突出模态特定的特征,我们在骨干网络中插入了一种新颖的双向解耦聚焦机制。它在DEYOLO的特征提取阶段多方向地改善了感受野,从而获得了更好的结果。图1展示了DEYOLO与DetFusion [24]、IRFS [30]、PIAFuse [26]、SeaFusion [25]和U2Fusion [31]的检测结果。可以看出,所提出的DEYOLO取得了更好的检测效果。本工作的贡献主要体现在以下三个方面:
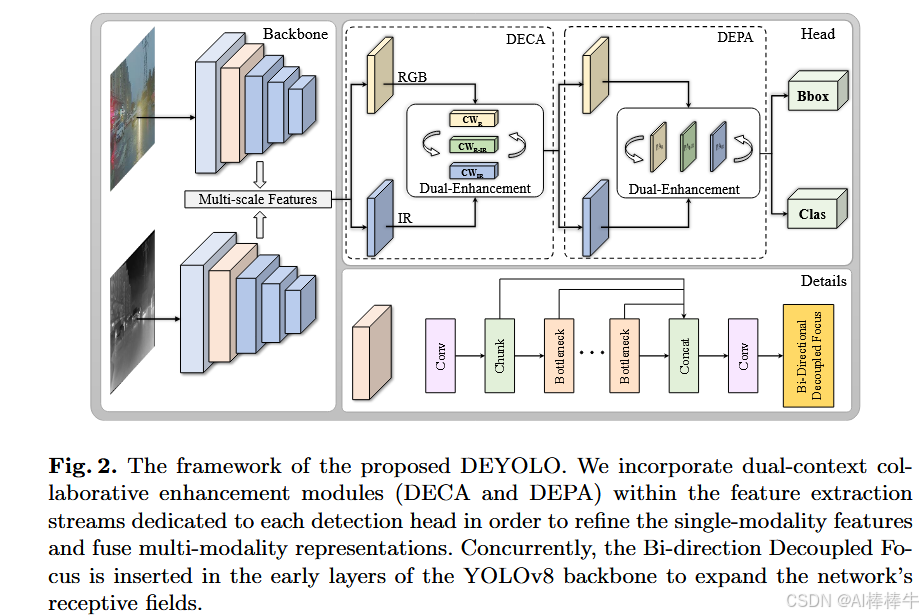
1 我们提出了基于YOLOv8 [12]的DEYOLO,它在骨干网络和检测头之间进行跨模态特征融合。与其他直接融合双模态图像的方法不同,我们在特征空间中融合双模态信息,并专注于目标检测任务。
2 我们提出了利用双增强机制的DECA和DEPA模块。它们减少了两种模态之间的干扰,并通过重新分配通道和像素的权重来实现语义和空间信息的增强。
3 为了使骨干网络提取的特征更适应我们的双增强机制,我们设计了双向解耦聚焦模块。它在不同方向上下采样浅层特征图,增加了感受野而不丢失周围信息。

2.相关工作
在本节中,我们首先回顾了常用的单模态目标检测算法。随后,介绍了一些最新的可见光和红外图像融合方法。
2.1 单模态目标检测
近年来,深度神经网络被提出以提升目标检测任务的准确性,包括CNN及其变体,例如Sparse R-CNN [23]、CenterNet2 [36]和YOLO系列 [21,2,29],以及基于Transformer的模型,例如DETR [3]和Swin Transformer [18]。尽管这些模型能够取得出色的性能,但它们都仅利用了单模态图像的信息。此外,这些模型严重依赖图像的纹理特征,这限制了它们在红外图像上的检测能力。
为了处理红外目标检测问题,研究人员不断引入不同的网络结构和机制。ALCNet [5] 使用骨干网络提取图像的高层语义特征,并通过模型驱动的编码器学习局部对比特征。ISTDU-Net [7] 有效地整合了编码和解码阶段,并通过跳跃连接促进信息传递。这种结构能够在保持高分辨率的同时增加感受野。IRSTD-GAN [34] 将红外目标视为一种特殊的噪声,它可以根据GAN学习到的数据分布和层次特征从输入图像中预测红外小目标。这些模型仅考虑了红外图像,而没有从可见光图像中提取信息。
上述单模态方法在复杂光照条件下的目标检测中并不十分适用。相比之下,双模态融合能够从可见光和红外图像中提取互补信息,从而减少对纹理信息的过度依赖。
2.2 融合与检测方法
考虑到红外图像在光照条件不佳的情况下表现更为稳定,各种可见光和红外图像融合方法已被提出。
U2Fusion [31] 是一种无监督的端到端图像融合网络,能够解决不同的融合问题。它通过特征提取和信息度量自动估计相应源图像的重要性,并提出自适应信息保留度。PIAFusion [26] 使用光照感知损失来考虑光照因素。SwinFusion [19] 引入了基于自注意力 [28] 和交叉注意力的融合单元,以挖掘同一领域内和跨领域的长依赖关系。CDDFuse [35] 引入了 Transformer-CNN 提取器,并成功分解出所需的模态特定特征和模态共享特征。在融合过程之后,获得的图像被输入到单独的模型中进行目标检测。
3.方法
如图2所示,为了处理从双模态图像中提取的多尺度特征,我们在YOLOv8 [12]模型的骨干网络和颈部之间添加了新设计的模块DECAs和DEPAs(图3)。通过特定的双增强机制,语义信息和空间信息的融合使得双模态特征更加协调。同时,对于骨干网络,为了更好地提取和保留双模态图像的有用特征,我们提出了一种新颖的双向解耦聚焦策略。它增加了骨干网络在不同方向上的感受野,并确保原始信息不会丢失。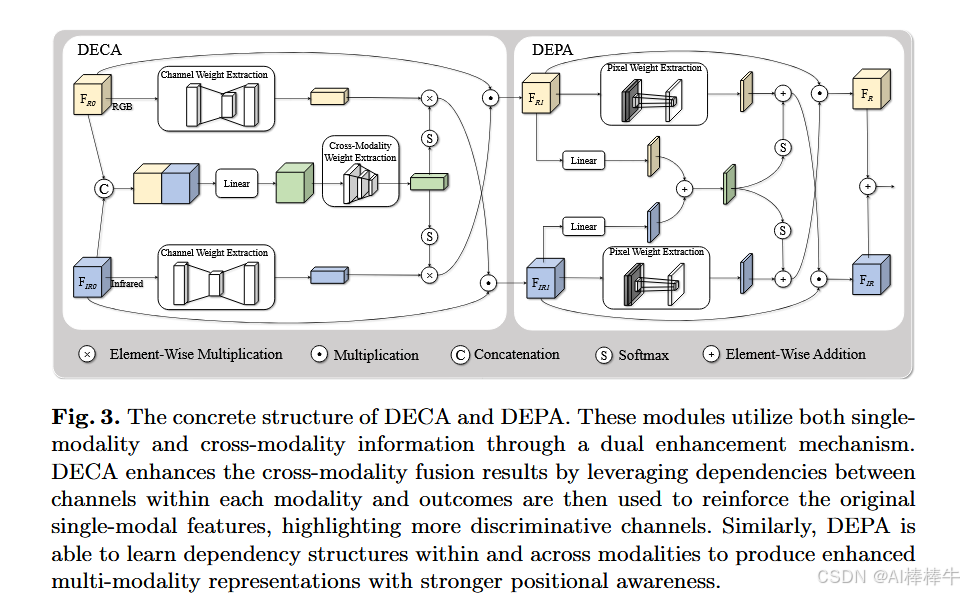
这里的双重增强机制指的是通过单模态信息在通道间对双模态融合结果进行增强,以及通过双模态融合的互补信息对单模态进行进一步增强。因此,DECA能够根据每个通道的重要性分配权重,从而强调语义信息。
详细内容务必认真研读原文!
写在最后
学术因方向、个人实验和写作能力以及具体创新内容的不同而无法做到一通百通,所以本文作者即B站Up主:Ai学术叫叫兽
在所有B站资料中留下联系方式以便在科研之余为家人们答疑解惑,本up主获得过国奖,发表多篇SCI,擅长目标检测领域,拥有多项竞赛经历,拥有软件著作权,核心期刊等经历。因为经历过所以更懂小白的痛苦!因为经历过所以更具有指向性的指导!
祝所有科研工作者都能够在自己的领域上更上一层楼!!!
所有科研参考资料均可点击此链接,合适的才是最好的,希望我的能力配上你的努力刚好合适!


分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐


 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)