
多模态(文本、图像)表征(嵌入)模型:jina-embeddings-v4
Jina Embeddings v4是一个基于Qwen2.5-VL-3B-Instruct构建的多模态通用嵌入模型,支持文本、图像和视觉文档的统一嵌入表示。该模型具有2048维密集嵌入和128维多向量嵌入能力,支持30多种语言,特别适合处理包含图表、表格等复杂元素的文档检索。技术亮点包括FlashAttention2注意力机制和灵活的可调嵌入维度(最低128维)。模型可通过API或开源框架使用,同
一、快速入门
本文介绍了 Jina Embeddings v4,这是一个用于多模态和多语言检索的通用嵌入模型。它特别适用于复杂的文档检索,包括包含图表、表格和插图等视觉元素的文档。
二、使用场景与模型信息
(一)模型构建基础
Jina Embeddings v4 基于 Qwen/Qwen2.5-VL-3B-Instruct 构建。
(二)功能特点
-
统一嵌入 :为文本、图像和视觉文档提供统一的嵌入表示,支持密集(单向量)和后期交互(多向量)检索。
-
多语言支持 :支持 30 多种语言,适用于包括技术性和视觉复杂文档在内的多种领域。
-
任务特定适配器 :在推理时可选择用于检索、文本匹配和代码相关任务的适配器。
-
灵活嵌入尺寸 :密集嵌入默认为 2048 维,但可截断至低至 128 维,且性能损失 minimal(原文如此,意为 “极小”)。
(三)特征概要
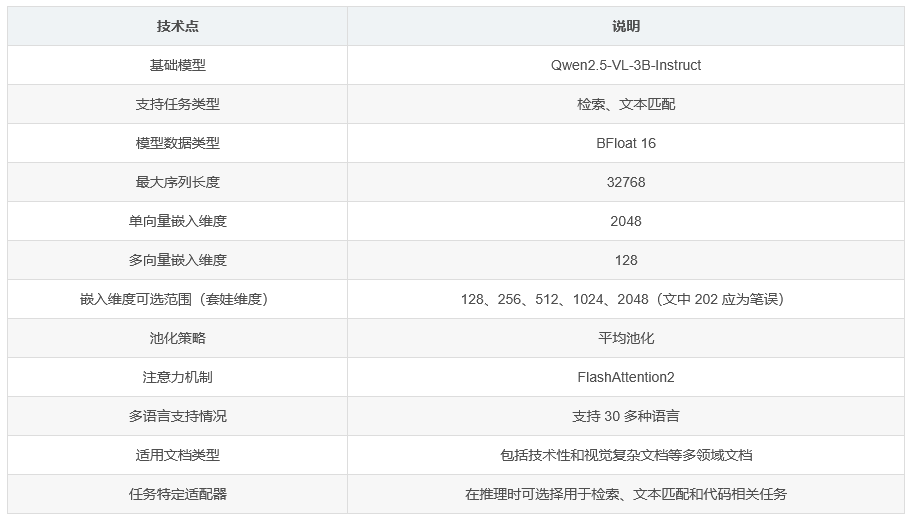
| 基础模型 | Qwen2.5-VL-3B-Instruct |
|---|---|
| 支持任务 | 检索、文本匹配 |
| 模型数据类型 | BFloat 16 |
| 最大序列长度 | 32768 |
| 单向量维度 | 2048 |
| 多向量维度 | 128 |
| 套娃维度 | 128、256、512、1024、202(推测应为 2048,原文有笔误) |
| 池化策略 | 平均池化 |
(四)技术亮点
其注意力机制采用了 FlashAttention2。
三、训练与评估
文中提及训练细节和基准测试可参阅 Jina Embeddings v4 的技术报告。
四、使用方法
可通过 Jina AI Embeddings API、transformers 或 sentence-transformers 来满足相关要求并使用该模型。
五、Jina - VDR
随 Jina Embeddings v4 一起发布的还有 Jina VDR,这是一个用于视觉文档检索的多语言、多领域基准。任务集合可在相应页面查看,评估说明也可在指定位置找到。
六、核心技术汇总

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)