
第二十五章:多模态 latent 融合方式对比(拼接 vs Cross Attention)
多模态融合
前言:当“视觉”与“听觉”在AI大脑中相遇
我们人类的大脑,在处理多模态信息时,是一个无与伦比的融合大师。当你看到一只狗在叫时,你的视觉皮层和听觉皮层的信息,会无缝地融合,让你产生一个统一的认知:“一只正在吠叫的狗”。
那么,AI模型是如何模拟这个过程的呢?当它得到了一个图像Latent(来自视觉编码器)和一个文本Latent(来自文本编码器)时,这两个同样强大但“语言”不同的高维向量,应该如何“沟通”和“融合”,以产生一个统一的、更深刻的理解?
今天,我们将深入探讨两种主流的“融合”策略:简单直接的拼接,和精妙优雅的交叉注意力。理解它们的差异,是你从“使用者”晋升为“架构师”的必经之路
第一章:终极比喻 —— 一场关于“项目报告”的会议
想象一下,CEO(代表最终的决策层/生成层)需要听取一个项目的汇报。项目信息有两个来源:PPT部门(代表图像模态)和财务部门(代表文本模态)。
1.1 拼接 (Concatenation):PPT部门和财务部门“各自念稿”
流程:CEO说:“好了,你们两个部门,把你们的报告(Latent)拼在一起,给我念一遍。”
于是,PPT部门先展示了30页精美的图片,然后财务部门接着念了20页枯燥的报表。
特点:
简单直接:信息只是被“物理上”地连接在了一起。
信息无交互:在汇报阶段,PPT和财务报表之间没有任何交流。
融合靠“会后消化”:CEO需要自己在大脑里,费力地去理解“哦,原来第3页的这张图,对应的是第15页的这个数据”。所有的融合压力,都在下游的“决策层”(比如一个大语言模型)身上。
1.2 交叉注意力 (Cross-Attention):CEO向PPT部门“精准提问”
流程:这次,CEO(财务部门)拿着自己的财务报表(文本Latent),主动地向PPT部门(图像Latent)提问。
CEO(财务Q):“我的报表第5行提到了‘用户增长率飙升’,请问你们PPT里,哪几张图(图像K)能证明这一点?”
PPT部门(图像V):“报告CEO,第8、9、10页的用户活跃度曲线图和市场占有率图,可以证明。”
特点:
主动查询:一个模态(文本)主动地从另一个模态(图像)中,查询和提取自己需要的信息。
信息强交互:融合发生在“汇报”阶段,信息是动态、按需交互的。
融合效率高:CEO(决策层)得到的是已经经过筛选和对齐的、高度相关的“图文并茂”的信息,理解负担大大减轻。
第二章:拼接融合 (Concatenation) 详解与实战
深入讲解拼接法的实现、优劣和适用场景,并以LLaVA为例。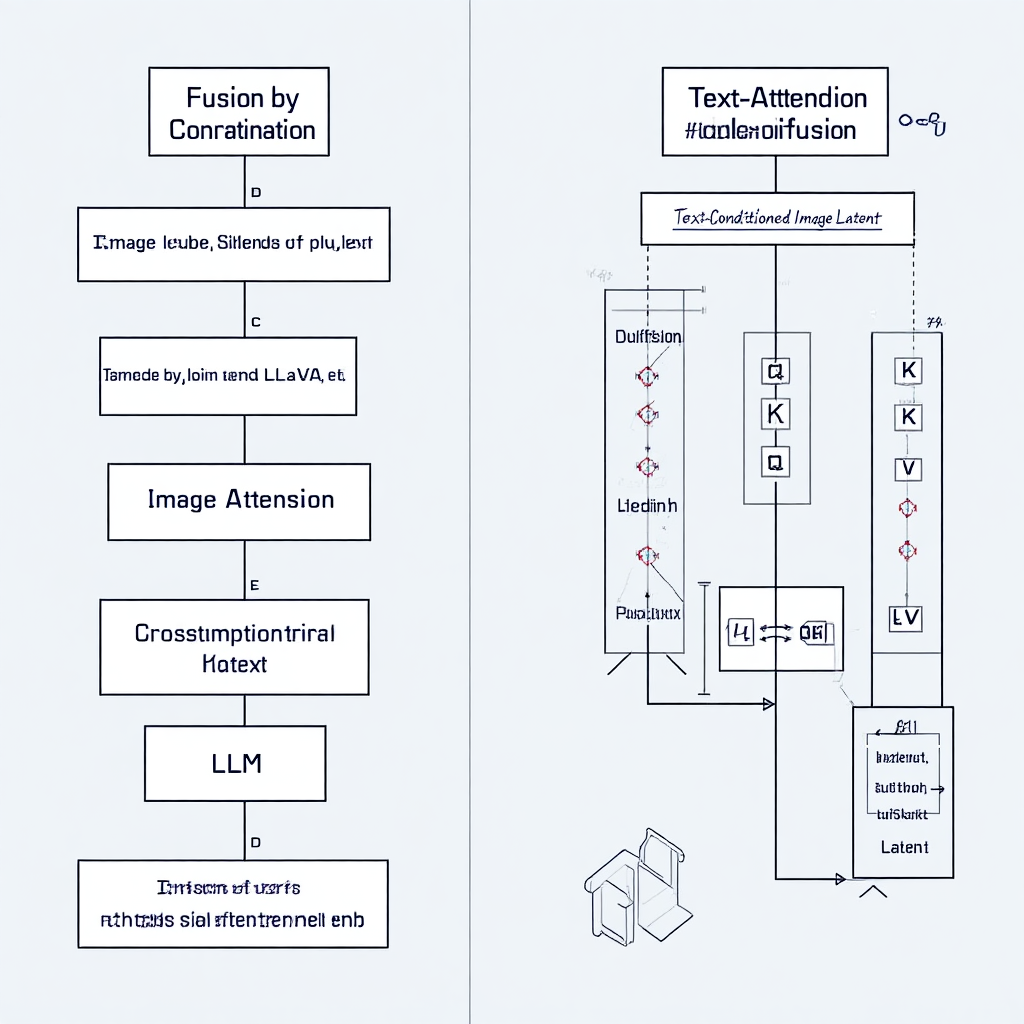
2.1 架构原理:简单、直接、“物理连接”
在数学上,拼接就是torch.cat。假设我们有一个图像Latent,形状为[B, L_img, D],和一个文本Latent,形状为[B, L_txt, D]。
拼接后,我们得到一个新的、更长的序列,形状为[B, L_img + L_txt, D]。
2.2 适用场景:当两个模态“地位平等”时 (e.g., LLaVA)
在像LLaVA这样的大型多模态模型(LMM)中,目标是让一个大语言模型(LLM)同时“理解”图像和文本。
做法:将图像编码后的Latent序列,和文本编码后的Latent序列,直接拼接起来,然后一起喂给LLM。LLM内部强大的自注意力机制,会自己去学习这两个拼接在一起的序列之间的复杂关系。
这种方式,赋予了两个模态平等的“话语权”,让LLM自己去当那个“聪明的CEO”。
2.3 用PyTorch代码实现图像与文本Latent的拼接
我们将模拟LLaVA的核心思想,创建两个代表图像和文本的Latent张量,然后使用torch.cat,将它们在“序列长度”这个维度上,像拼接火车车厢一样连接起来。
代码实现
# case_2_3_concatenation.py
import torch
# --- 1. 定义模拟的Latent张量超参数 ---
batch_size = 2 # B: 假设我们一次处理2个样本 (e.g., 2张图和2段文字)
img_seq_len = 4 # L_img: 假设每张图被编码成4个Token (e.g., 2x2的patch)
txt_seq_len = 5 # L_txt: 假设每段文字被编码成5个Token
embedding_dim = 8 # D: 为了方便展示,我们用一个很小的嵌入维度
# --- 2. 创建模拟的图像和文本Latent ---
# 形状: [B, L_img, D]
image_latents = torch.randn(batch_size, img_seq_len, embedding_dim)
# 形状: [B, L_txt, D]
text_latents = torch.randn(batch_size, txt_seq_len, embedding_dim)
print("--- 融合前 ---")
print(f"图像Latent形状 (B, L_img, D): {image_latents.shape}")
print(f"文本Latent形状 (B, L_txt, D): {text_latents.shape}")
# --- 3. 【核心操作】使用torch.cat进行拼接 ---
# 我们要在“序列长度”的维度上进行拼接,这个维度是dim=1
# dim=0 是Batch维度, dim=2 是Embedding维度
fused_latents = torch.cat([image_latents, text_latents], dim=1)
print("\n--- 拼接融合后 ---")
print(f"融合后Latent形状 (B, L_img + L_txt, D): {fused_latents.shape}")
# --- 4. 验证结果 ---
expected_seq_len = img_seq_len + txt_seq_len
print(f"\n预期的序列长度: {expected_seq_len}")
print(f"实际的序列长度: {fused_latents.shape[1]}")
assert fused_latents.shape[1] == expected_seq_len
print("\n✅ 成功!图像和文本Latent被无缝拼接成了一个更长的序列。")
print("这个融合后的长序列,就可以直接作为下游LLM的输入了。")
代码解读】
这段代码的核心只有一行:torch.cat([image_latents, text_latents], dim=1)。
torch.cat就像一个胶水,它将两个张量沿着我们指定的维度dim=1(序列长度维度)粘在了一起。你可以想象,我们把4节代表图像的“火车车厢”和5节代表文本的“火车车厢”,首尾相连,组成了一列总共9节车厢的“长火车”。
关键点:在这个过程中,图像Latent和文本Latent之间没有发生任何内部的信息交互。它们只是被简单地放在了同一个序列中,等待下游的模型(比如一个LLM)用其自身的自注意力机制去慢慢“消化”和“理解”它们之间的关系。
第三章:交叉注意力融合 (Cross-Attention) 详解与实战
深入讲解交叉注意力的非对称机制,并以Stable Diffusion为例。
3.1 架构原理:非对称的“查询-应答”机制
Cross-Attention与我们之前学的Self-Attention最大的不同在于:
Self-Attention:Q, K, V都来自同一个输入序列(自己对自己提问)。
Cross-Attention:Q来自一个输入序列(比如图像),而K和V来自另一个输入序列(比如文本)。
这是一个非对称的结构,天然地蕴含了**“引导”或“控制”**的意味。
3.2 适用场景:当一个模态“引导”另一个模态时 (e.g., Stable Diffusion)
在Stable Diffusion中,任务是用文本Prompt,去“引导”图像的生成。
做法:在U-Net的每一步去噪中:
Q:来自带噪的图像Latent。它在“提问”:“我该如何变得更清晰?”
K, V:来自文本Prompt的Embedding。它在“回答”:“根据‘宇航员骑马’这个指令,你应该朝这个方向变清晰。”
这种方式,赋予了文本模态**“主导”的地位,而图像模态则是“被引导”**的一方。
3.3 用PyTorch代码实现图像对文本的“交叉注意力
我们将模拟Stable Diffusion的核心机制,构建一个简化的Cross-Attention模块。我们将看到,图像Latent(作为Query)是如何主动地从文本Latent(作为Key和Value)中“提取”和“吸收”信息的。
# case_3_3_cross_attention.py
import torch
import torch.nn as nn
import torch.nn.functional as F
# --- 1. 定义一个简化的Cross-Attention模块 ---
class SimpleCrossAttention(nn.Module):
def __init__(self, query_dim, context_dim):
super().__init__()
# 线性层,用于将输入投影到Q, K, V空间
self.query_proj = nn.Linear(query_dim, query_dim)
self.key_proj = nn.Linear(context_dim, query_dim) # K的维度需要和Q匹配
self.value_proj = nn.Linear(context_dim, query_dim) # V的维度通常和K一致
def forward(self, query, context):
# query (e.g., 图像Latent) 形状: [B, L_query, D_query]
# context (e.g., 文本Latent) 形状: [B, L_context, D_context]
# 将输入投影到Q, K, V
q = self.query_proj(query)
k = self.key_proj(context)
v = self.value_proj(context)
# 计算注意力分数: Q @ K^T
attention_scores = torch.matmul(q, k.transpose(-2, -1))
# 缩放
d_k = k.size(-1)
attention_scores = attention_scores / (d_k ** 0.5)
# Softmax归一化
attention_weights = F.softmax(attention_scores, dim=-1)
# 加权求和
output = torch.matmul(attention_weights, v)
return output
# --- 2. 准备模拟的Latent张量 ---
batch_size = 2
img_seq_len = 4
txt_seq_len = 5
embedding_dim = 8
# 图像Latent,它将扮演“提问者”(Query)的角色
image_latents = torch.randn(batch_size, img_seq_len, embedding_dim)
# 文本Latent,它将扮演“信息源”(Context -> Key, Value)的角色
text_latents = torch.randn(batch_size, txt_seq_len, embedding_dim)
print("--- 融合前 ---")
print(f"图像Latent (Query) 形状: {image_latents.shape}")
print(f"文本Latent (Context) 形状: {text_latents.shape}")
# --- 3. 【核心操作】执行Cross-Attention融合 ---
cross_attention_layer = SimpleCrossAttention(query_dim=embedding_dim, context_dim=embedding_dim)
fused_output = cross_attention_layer(query=image_latents, context=text_latents)
print("\n--- 交叉注意力融合后 ---")
print(f"融合后输出形状: {fused_output.shape}")
# --- 4. 验证结果 ---
# 输出的序列长度应该和Query(图像)的序列长度一致
assert fused_output.shape[1] == img_seq_len
# 输出的嵌入维度也应该和Query(图像)的嵌入维度一致
assert fused_output.shape[2] == embedding_dim
print("\n✅ 成功!图像Latent主动查询了文本Latent,并得到了一个“被文本语义浸染”的新图像Latent。")
print("注意,输出的形状与Query(图像)完全相同,这意味着它可以无缝地替换回原始的图像Latent,继续在U-Net中流动。")
【代码解读】
这段代码的核心在于forward函数中的数据流:
Q 来自 query (图像Latent)。
K 和 V 都来自 context (文本Latent)。
这清晰地展示了交叉注意力的非对称性。最终的输出output,其形状[B, L_img, D]与输入的query(图像Latent)完全相同,但它内部的每一个向量值,都已经是文本信息(V)的加权平均和。
关键点:与拼接不同,交叉注意力是一种动态的信息注入。图像序列中的每个Token,都会根据自己的需要,去“看”一遍文本序列中的所有Token,然后决定从哪些文本Token中“吸收”多少信息。这是一种主动的、有选择性的、深度交互的融合方式。
第四章:“融合”的时机:早期、中期还是晚期融合?
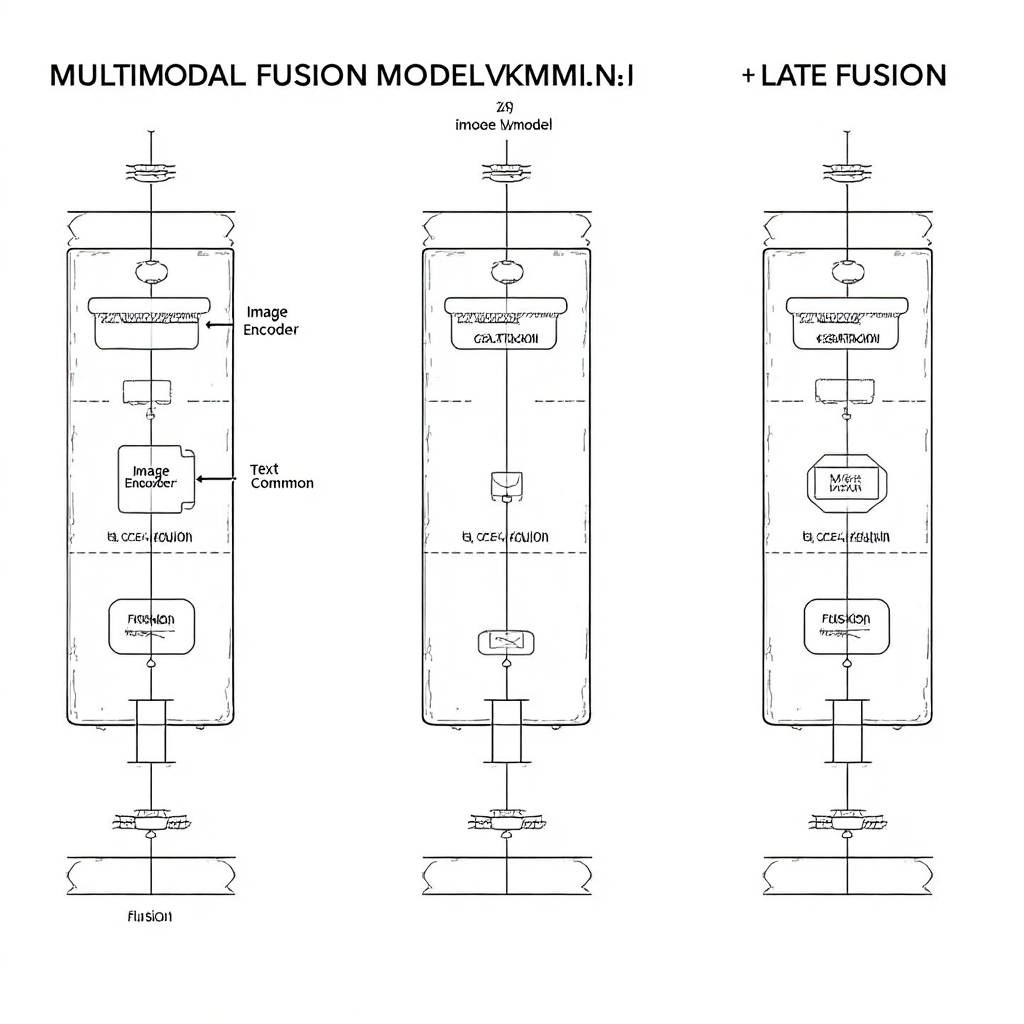
多模态融合,不仅有“方式”的区别,还有**“时机”**的区别。
早期融合 (Early Fusion):在输入层,就把原始数据(如像素和Token ID)进行某种形式的拼接。
中期融合 (Mid-level Fusion):像我们讨论的这样,在各自的Encoder提取出高级特征(Latent)后,再进行融合。这是最主流、效果最好的方式。
晚期融合 (Late Fusion):让每个模态的模型独立地完成所有计算,直到最后输出层,才把各自的预测结果进行融合(比如加权平均)。
总结与展望:没有“最优解”,只有“最合适”的架构
恭喜你!今天你已经从一个模型的使用者,晋升到了一个能从“架构”层面,去思考和评判模型的“AI架构师”。
✨ 本章惊喜概括 ✨
| 你掌握了什么? | 对应的技能/工具 |
|---|---|
| 理解了两种核心融合策略 | ✅ 拼接 (Concatenation) vs. 交叉注意力 (Cross-Attention) |
| 洞悉了其适用场景 | ✅ “平等对话”(LLaVA) vs. “单向引导”(Stable Diffusion) |
| 亲手实现了两种机制 | ✅ 用PyTorch代码构建了torch.cat和CrossAttention |
| 了解了架构设计的权衡 | ✅ 早期、中期、晚期融合的差异 |
| 在AI的世界里,不存在一种“万能”的融合架构。拼接的简单高效,使其在需要让下游大模型自行学习复杂关系时非常有用。而交叉注意力的精准高效,使其在需要用一个模态去精确控制另一个模态的生成时,无与伦比。 |

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐



 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)