
自动驾驶Occupancy梳理笔记(四):GaussianFormer, OSP, ViewFormer, OPUS
四篇Occ论文方法整理和详细解读:GaussianFormer[ECCV2024], OSP[ECCV2024], ViewFormer[ECCV2024], OPUS[NIPS2024]
·
【如果笔记对你有帮助,欢迎关注&点赞&收藏,收到正反馈会加快更新!谢谢支持!】
往期:
自动驾驶Occupancy梳理笔记(二):SurroundOcc, OccFormer, VoxFormer, FB-OCC-CSDN博客
自动驾驶Occupancy梳理笔记(三): SelfOcc, SparseOcc(华为&上交), SparseOcc(上海AI Lab), OccWorld-CSDN博客
目录
2.14 Occupancy as Set of Points [ECCV 2024]
2.16 OPUS: Occupancy Prediction Using a Sparse Set [NIPS 2024]
重要论文梳理
2.13 GaussianFormer: Scene as Gaussians for Vision-Based 3D Semantic Occupancy Prediction [ECCV 2024]
- 任务:3D语义占用预测
- 优化点:用3D高斯表示场景,稀疏且可以关注感兴趣区域(对比:voxel表征、平面表征(BEV, TPV)这些grid-based表征方式会因为空网格而造成大量冗余)
- 高斯表示:
- 3D高斯如何表示Occ?
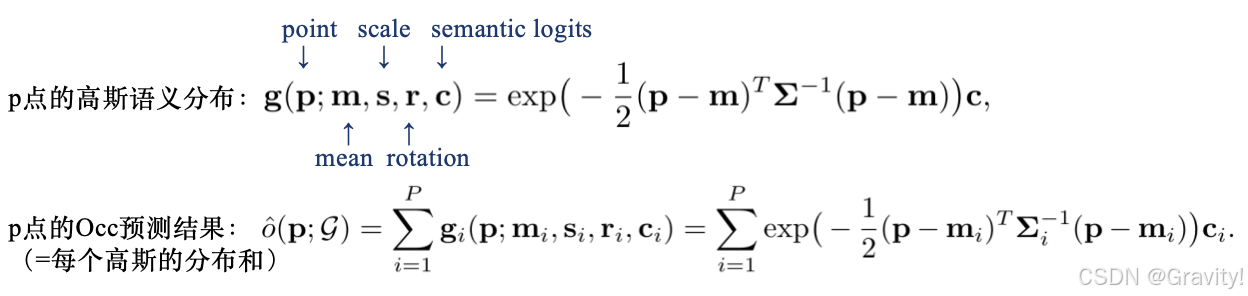
- 优势:
- 可以适应物体大小和场景复杂度来进行动态调整(均值方差可学)
- 不会损失细节(3D高斯比2D平面表征要精确)
- 3D高斯自带语义信息,将高斯表征转化到Occ更容易(不需要高维特征)
- 3D高斯如何表示Occ?
- Pipeline:
- Gaussian properties: 即👆高斯表示,初始化为均值不一的高斯点
- Gaussian queries:用来学习图像和3D空间特征,初始化为可学习向量
- 初始化 Properties & Queries → [ Self-encoding【体素化,稀疏卷积】→ 图像Corss-Attn【提取图像特征】 → Refinement模块【修正Gaussian properties】] × B → Splatting【通过局部聚合转化到Occ】→ Occ 预测结果
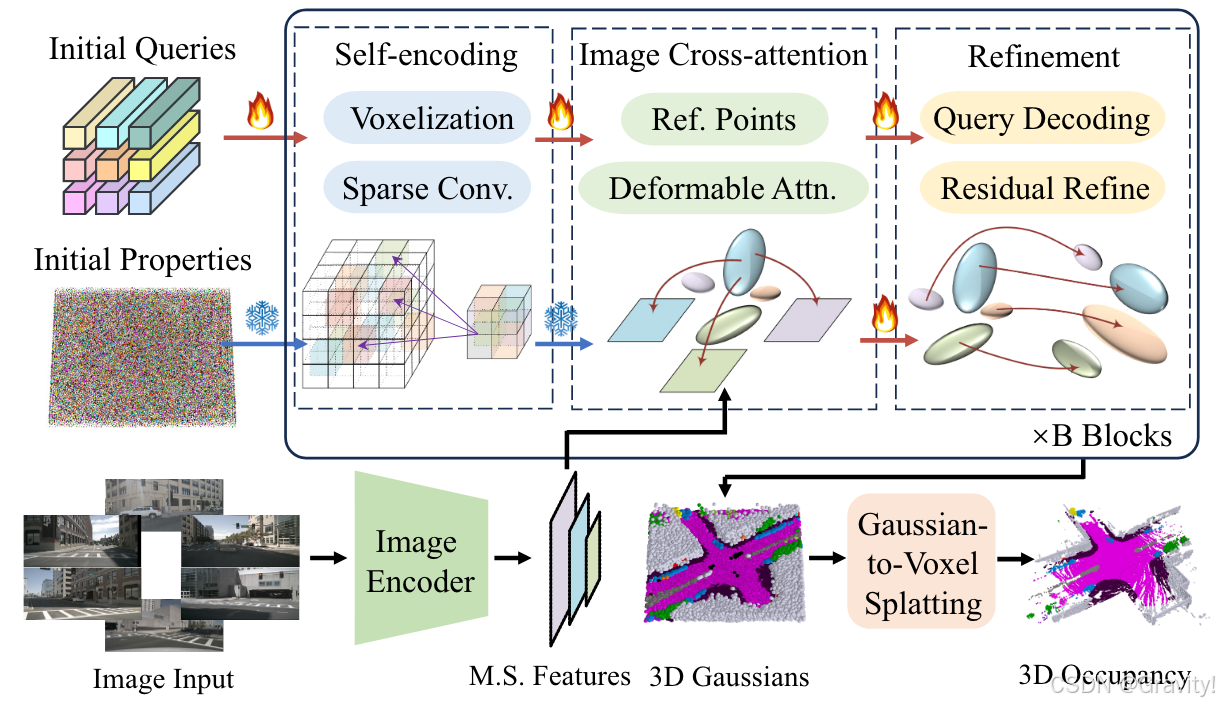
- 核心模块1: Image Cross-Attention
- 用Deformable Attention提取图像特征
- Query:Gaussian queries
Key:通过3D高斯生成3D参考点(m+∆m,置偏移量),通过内外参找到图像对应的位置
Value:图像特征
- 核心模块2: Refinement Module
- 用带有3D空间和语义信息的Gaussian queries(
) 修正Gaussian properties(
)
- 方法:先通过Gaussian queries解码出一个3D Gaussian(
) , 然后修正
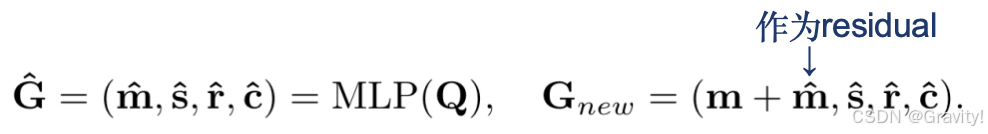
- 用带有3D空间和语义信息的Gaussian queries(
2.14 Occupancy as Set of Points [ECCV 2024]
- 任务:3D语义占用预测
- 优化点:用兴趣点表示场景(对比BEV:BEV均匀采样难以关注重点区域)
- 兴趣点 Points of Interest (PoIs):表示需要重点关注的物体或区域
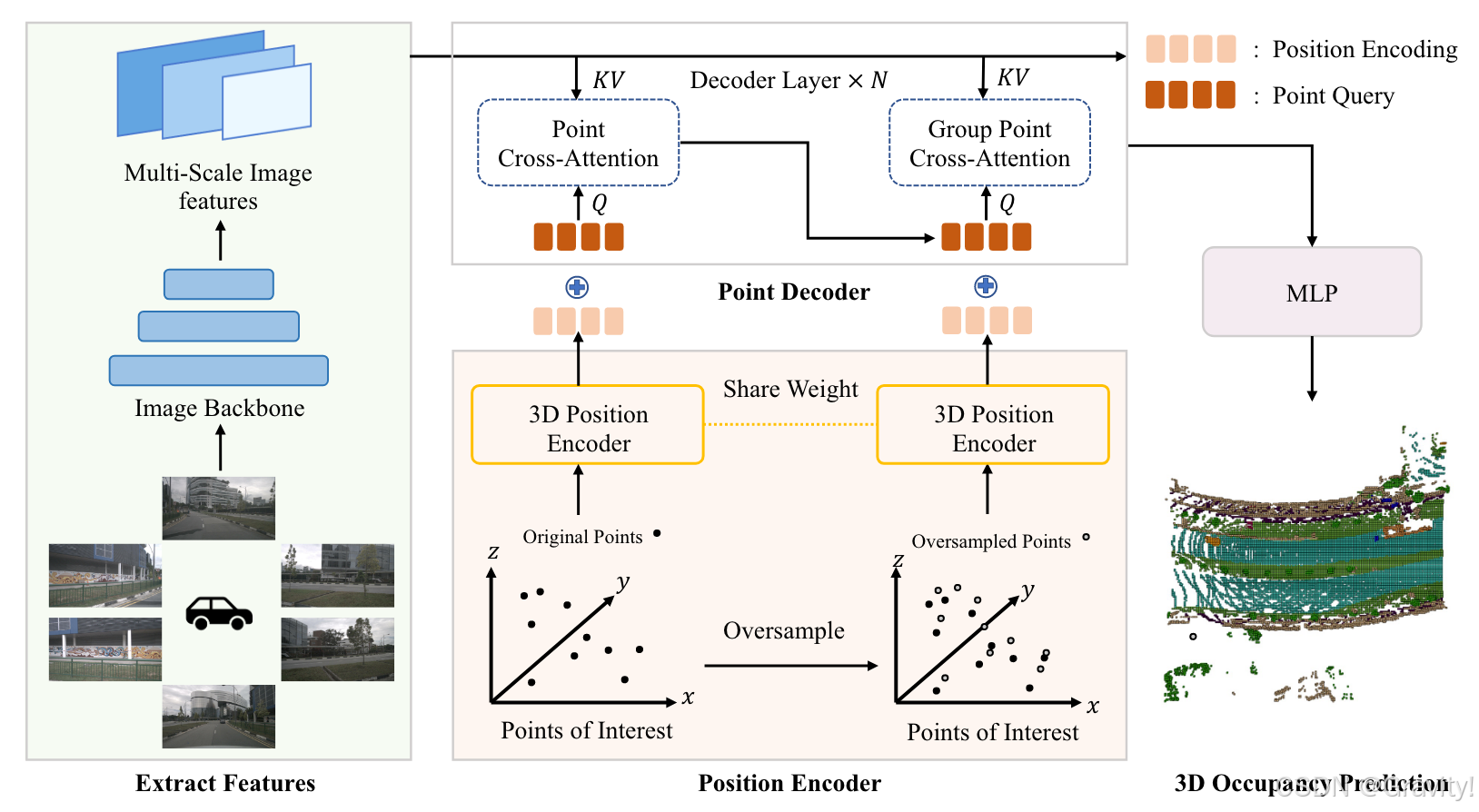
- Pipeline:
- 图像特征:环视图【输入】→ ResNet & FPN【提取图像特征,多尺度特征融合】
- 位置编码: 采样空间中的3D点【作为Pols】→ 3D Position Encoder【正余弦位置编码】→ Position Encoding (同时对采样点周围的点做上采样,重复流程,提高精度)
- 点解码:图像特征(k,v) & Point Query(初始化为0)+位置编码 → [ Point Cross-Attn【Deformable Attn实现特征采样】→ Group Point Cross-Attn【用周围点聚合局部信息】] × N → MLP【任务头】→ Occ 预测结果
2.15 ViewFormer: Exploring Spatiotemporal Modeling for Multi-View 3D Occupancy Perception via View-Guided Transformers [ECCV 2024]
- 任务:3D语义占用预测
- 优化点:
- 改进了3D参考点投影到2D图像的特征采用方式(因为受限于传感器)
【优化版:先学习3D局部点】 - 时序建模:online video多帧交互
- 改进了3D参考点投影到2D图像的特征采用方式(因为受限于传感器)
- Pipeline:
环视图【输入】→ 图像Backbone【提取图像特征】→ View Attention【聚合多视角图像特征给Voxel Query】→ Streaming Temporal Attention【和历史帧的BEV特征交互,融合时序信息】→ Occ语义占用&Occ Flow预测结果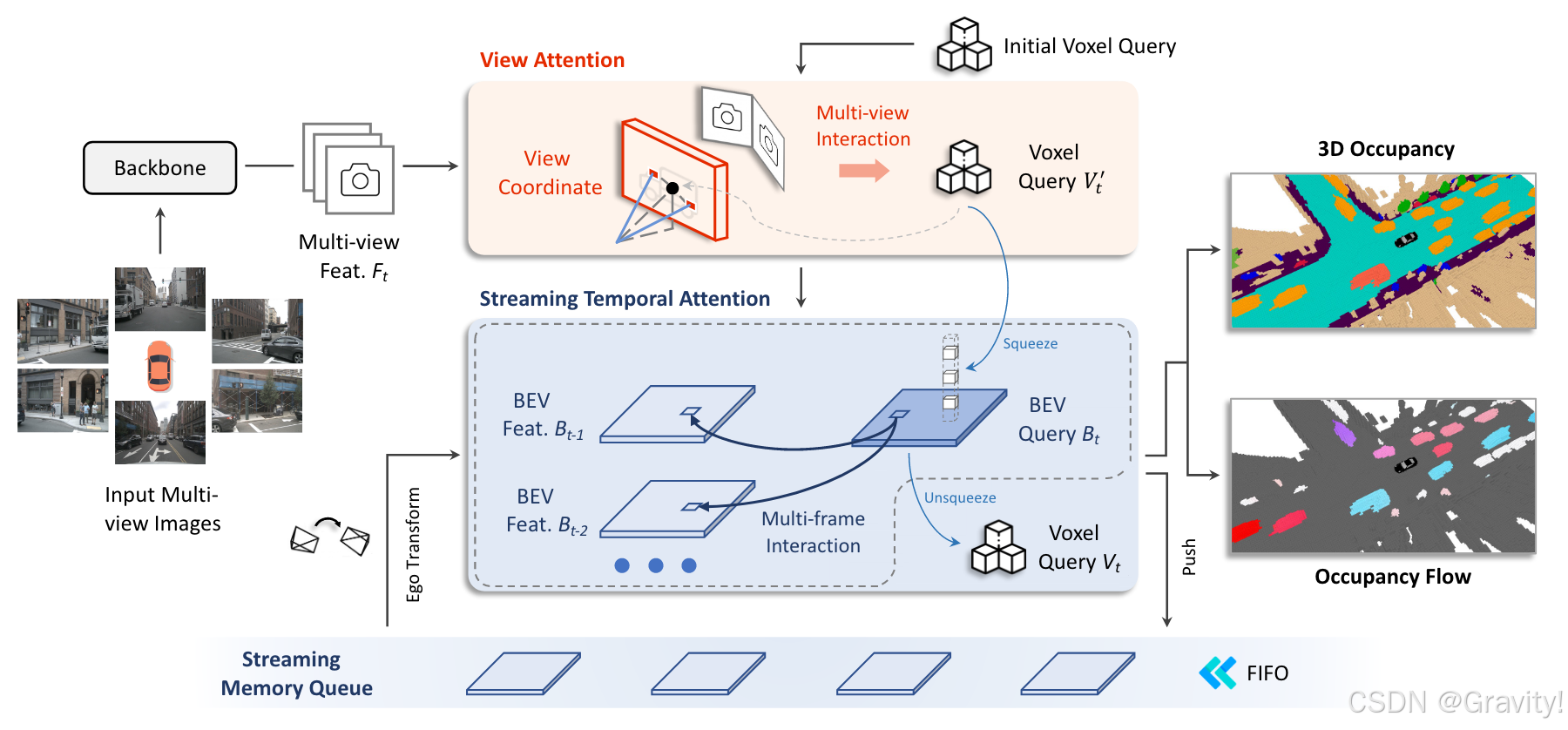
- 核心模块1: View Attention
- 通过query学习,设立更有效的3D采样点,采样图像信息
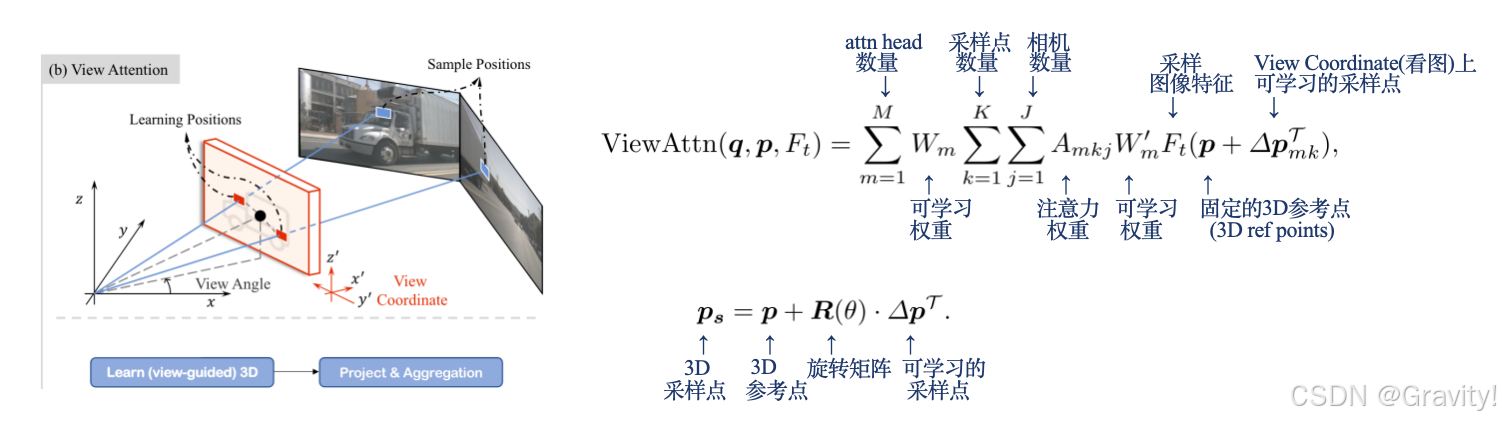
- 通过query学习,设立更有效的3D采样点,采样图像信息
- 核心模块2:Streaming Temporal Attention
- 作用:给当前帧的Voxel Query提供时序上的变化信息
- Streaming Memory Queue:通过队列方式,储存历史帧的BEV特征
- 实现方法:Voxel Query → 压缩到BEV Query → 用Deformable Attn和历史帧BEV交互 → 升维到Voxel Query
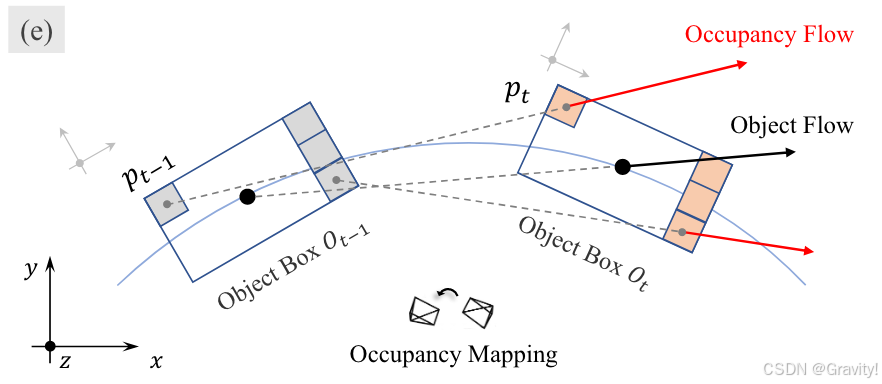
- 为什么需要Occ Flow?(ViewFormer最后预测Occ和Occ Flow)
- Flow表示运动变化
- Occ Flow可以提供更加精细的物体变化情况,物体的每个部分是不同的(比如一辆车转弯时,车头车尾的变化就不同)
- 看图例子,Occ flow对每个voxel都有估计,而Object flow只针对物体中心点
2.16 OPUS: Occupancy Prediction Using a Sparse Set [NIPS 2024]
- 任务:3D语义占用预测
- 优化点:将Occ预测任务转化到点集预测(然后就可以端到端训练稀疏网络)
- 拆成两个任务:1. 点的位置预测 2. 点的语义预测
- Pipeline:
环视图【输入】→ 图像Backbone【提取图像特征】→ Decoder【用图像特征修正query】→ 带语义的点集预测结果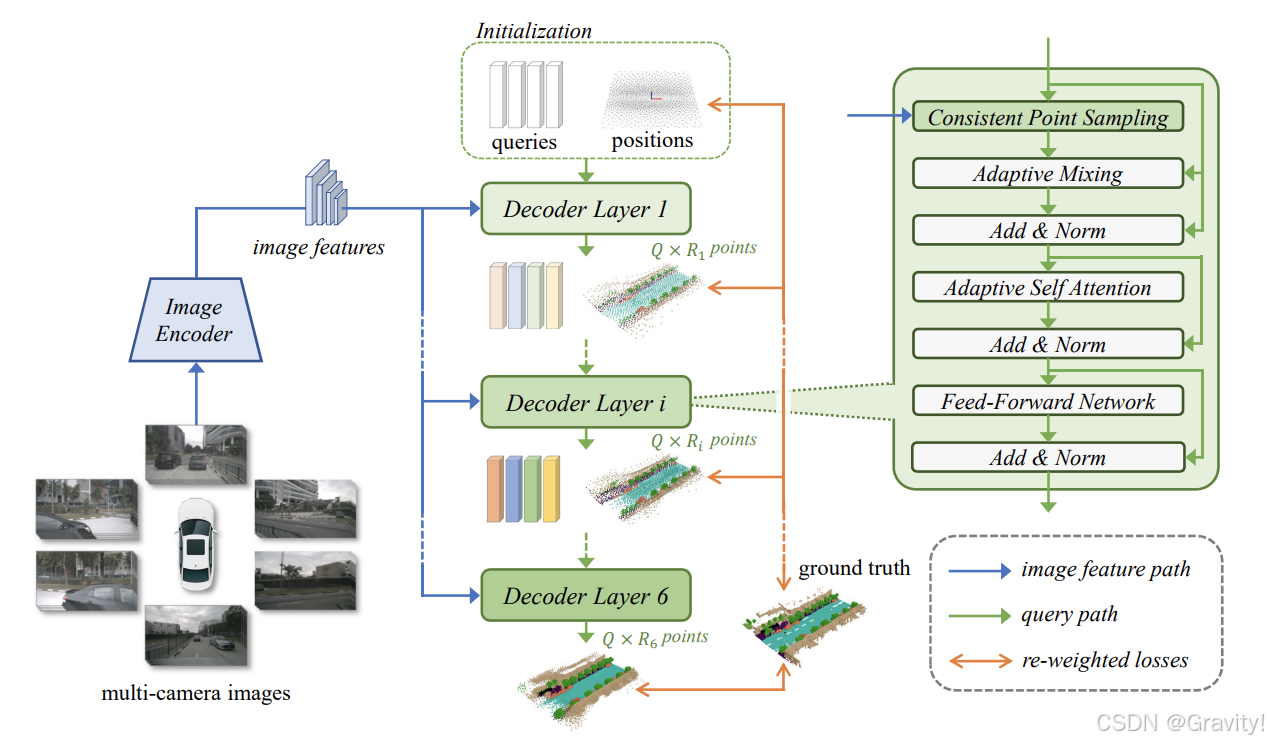
- 核心模块:Decoder
- 初始化:可学习的query【用来预测点集,decoder的每一层都会预测一次】
- Coarse-to-fine策略:Layer i 比 Layer i-1 预测更多的点(越来越精细)
- Query → 预测点集【Chamfer distance loss监督】 → 采样3D点 → 用3D点聚合图像特征 → 语义类别预测【Focal loss监督】
- 自适应Loss权重

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐


 35
35 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)