
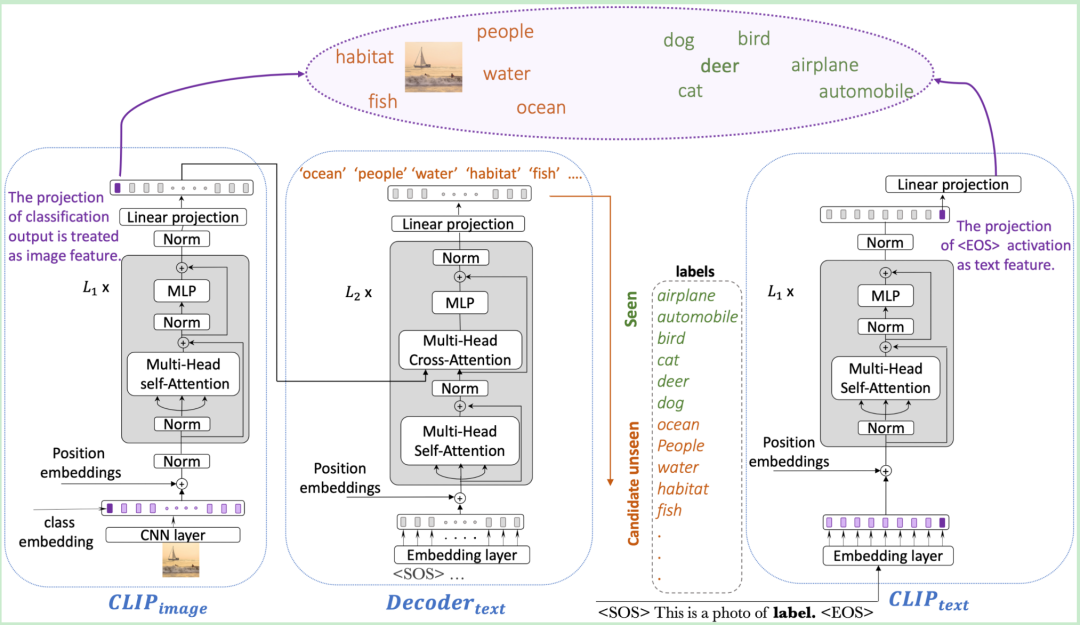
多模态对比学习模型CLIP原理是什么?(讲人话版)
CLIP(Contrastive Language-lmage Pre-training)
CLIP是由OpenAl提出的多模态对比学习模型通过400万组互联网图文对预训练,学习图像与文本的联合语义空间。
其核心架构为双塔编码器: 图像编码器(如ViT或ResNet)提取视觉特征,文本编码器(Transformer)提取语言特征,最终通过对比损失函数对齐两类特征。
讲人话
CLIP像一位“图文匹配专家”,它能同时看懂图片和文字。比如给它一张猫的图片和包子“一只蜷缩的猫”,CLIP能判断两者是否相关。
训练时,它反复对比海量图片和文字描述,直到学会精准匹配。
CLIP的原理
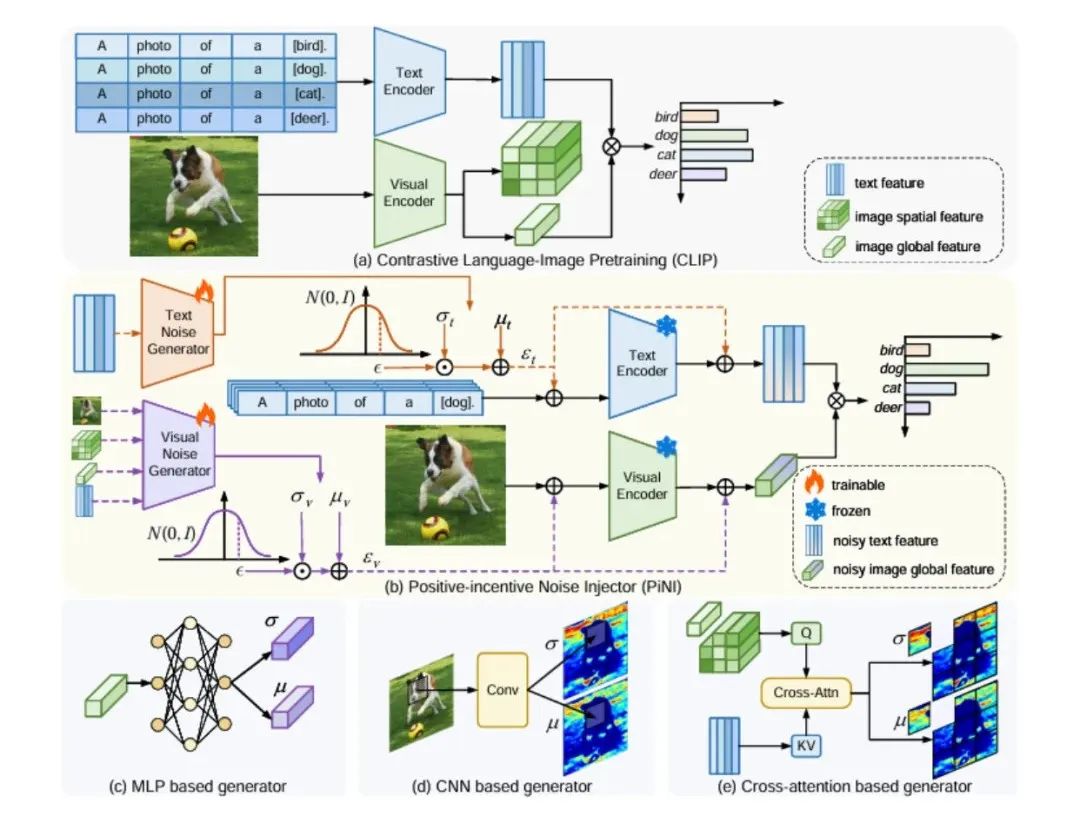
传统视觉模型需预设固定类别(如1000种物体),而CLIP利用自然语言监督,将任意文本描述作为监督信号。
其关键创新是对比学习目标函数(如InfoNCE损失),通过最大化匹配图文对的相似度、最小化不匹配对的相似度,实现跨模态语义对齐。
这使得模型具备零样本迁移能力–无需额外训练即可识别新类别。
讲人话
CLIP的聪明在于“用文字教电脑认图”。例如,训练时它看到“狗追球”的图片和文字,就记住两者关联;看到“狗吃草”的错误配对则降低关联分。
最终,它学会用文字描述理解任何新图片,比如输入“斑马条纹”,即使从未见过斑马也能识别 。
CLIP实践案例
DALL·E2图像生成: CLIP为生成模型提供跨模态引导,用户输入文字(如“星空下的鲸鱼”),模型生成匹配图像。
零样本分类器: 直接将类别名称(如“熊猫”“竹子”)输入CLIP,模型可对ImageNet图片分类,无需训练数据,准确率媲美全监督ResNet-50。
医疗影像分析: 通过描述病症(如“肺部结节”),辅助X光片诊断,减少标注依赖。
讲人话
CLIP已用于许多酷炫应用: 让AI“按文字画图”、给照片打标签不用提前教它类别,甚至帮医生看片时理解诊断报告的关键词。
总结
CLIP是一个“语言引导的视觉专家”,它通过对比海量图文,学会用文字理解图片。
传统模型像死记硬背的学生(需预设类别)CLIP则像会举一反三的侦探(用文字描述推理新事物)。
其双塔结构分别处理图像和文本,对比学习让两者默契配合。
这使它无需重新训练就能适配新任务,成为多模态AI的基石,但也依赖高质量图文数据。
核心价值
突破固定类别限制,让AI像人类一样通过语言灵活理解视觉世界。
最近两年,大家都可以看到AI的发展有多快,我国超10亿参数的大模型,在短短一年之内,已经超过了100个,现在还在不断的发掘中,时代在瞬息万变,我们又为何不给自己多一个选择,多一个出路,多一个可能呢?
与其在传统行业里停滞不前,不如尝试一下新兴行业,而AI大模型恰恰是这两年的大风口,整体AI领域2025年预计缺口1000万人,其中算法、工程应用类人才需求最为紧迫!
学习AI大模型是一项系统工程,需要时间和持续的努力。但随着技术的发展和在线资源的丰富,零基础的小白也有很好的机会逐步学习和掌握。【点击蓝字获取】
【2025最新】AI大模型全套学习籽料(可白嫖):LLM面试题+AI大模型学习路线+大模型PDF书籍+640套AI大模型报告等等,从入门到进阶再到精通,超全面存下吧!

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐


 23
23 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)