
手撕自动驾驶算法——词袋模型Bag-of-Words(BoW)
词袋模型词袋模型(Bag-of-Words,BoW)把特征当成一个个单词,通过比较两张图片中出现的单词是否一致,来判断这两张图片是否是同一场景。使用一种 k 叉树来表达字典。它的思路很简单,类似于层次聚类,是 k-means 的直接扩展。假定我们有 N个特征点,希望构建一个深度为 d,每次分叉为 k 的树,那么做法如下:最终在叶子层构建了单词,而树结构中的中间节点仅供快速查找时使用。这样...
词袋模型
词袋模型(Bag-of-Words,BoW)把特征当成一个个单词,通过比较两张图片中出现的单词是否一致,来判断这两张图片是否是同一场景。
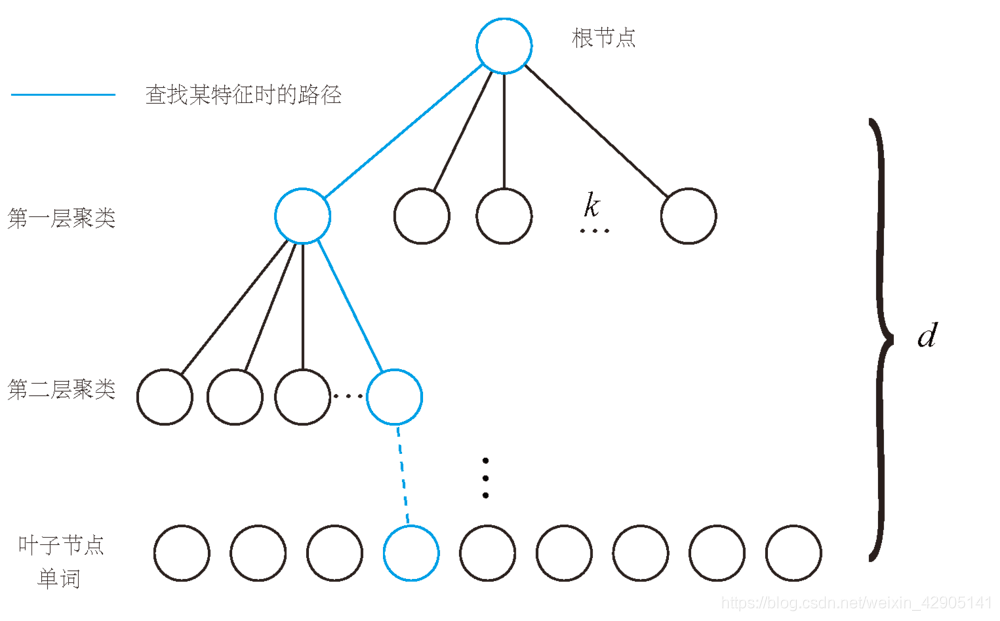
使用一种 k 叉树来表达字典。它的思路很简单,类似于层次聚类,是 k-means 的直接扩展。假定我们有 N个特征点,希望构建一个深度为 d,每次分叉为 k 的树,那么做法如下:
最终在叶子层构建了单词,而树结构中的中间节点仅供快速查找时使用。这样一个 k 分支,深度为 d 的树,可以容纳 k d 个单词。另一方面,在查找某个给定特征对应的单词时,只需将它与每个中间结点的聚类中心比较(一共 d 次),即可找到最后的单词,保证了对数级别的查找效率。
实践:创建字典
训练字典
/***************************************************
* 本节演示了如何根据data/目录下的十张图训练字典
* ************************************************/
int main( int argc, char** argv )
{
// read the image
cout<<"reading images... "<<endl;
vector<Mat> images;
for ( int i=0; i<10; i++ )
{
string path = "/home/xiaohu/slambook-master/ch12/data/"+to_string(i+1)+".png";
images.push_back( imread(path) );
}
// detect ORB features
cout<<"detecting ORB features ... "<<endl;
Ptr< Feature2D > detector = ORB::create();
vector<Mat> descriptors;
for ( Mat& image:images )
{
vector<KeyPoint> keypoints;
Mat descriptor;
detector->detectAndCompute( image, Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
}
// create vocabulary
cout<<"creating vocabulary ... "<<endl;
DBoW3::Vocabulary vocab;
vocab.create( descriptors );
cout<<"vocabulary info: "<<vocab<<endl;
vocab.save( "vocabulary.yml.gz" );
cout<<"done"<<endl;
return 0;
}
对十张目标图像提取 ORB 特征并存放至 vector容器中,然后调用 DBoW3 的字典生成接口即可。在 DBoW3::Vocabulary 对象的构造函数中,我们能够指定树的分叉数量以及深度,不过这里使用了默认构造函数,也就是 k =10, d = 5。这是一个小规模的字典,最大能容纳 10000 个单词。对于图像特征,我们亦使
用默认参数,即每张图像 500 个特征点。最后我们把字典存储为一个压缩文件。
相似度
TF-IDF(Term Frequency / Inverse Document Frequency,译频率-逆文本频率)
TF 部分的思想是,某单词在一个图像中经常出现,它的区分度就高。另一方面,IDF 的思想是,某单词在字典中出现的频率越低,则分类图像时区分度越高。
在词袋模型中,在建立字典时可以考虑 IDF 部分。统计某个叶子节点 wiw _iwi中的特
征数量相对于所有特征数量的比例,作为 IDF 部分。假设所有特征数量为 n,wiw_iwi 数量为nin_ini ,那么该单词的 IDF 为:.
TF 部分则是指某个特征在单个图像中出现的频率。假设图像 A 中,单词wiw_ iwi 出现了 nin_ini 次,而一共出现的单词次数为 n,那么 TF 为
于是wiw_ iwi 的权重等于 TF 乘 IDF 之积:
考虑权重以后,对于某个图像 A,它的特征点可对应到许多个单词,组成它的 Bag-of-Words:
单个向量vAv_AvA描述了一个图像 A。这个向量vAv_AvA是一个稀疏的向量,它的非零部分指示出图像 A 中含有哪些单词
计算相似度
L 1 范数形式:
相似性评分的处理:
取一个先验相似度 s(vt,vt−∆t)s(v_t , v_{t−∆t})s(vt,vt−∆t),它表示某时刻关键帧图像与上一时刻的关键帧的相似性。然后,其他的分值都参照这个值进行归一化:
如果当前帧与之前某关键帧的相似度,超过当前帧与上一个关键帧相似度的 3 倍,就认为可能存在回环。这个步骤避免了引入绝对的相似性阈值,使得算法能够适应更多的环境。
实践:相似度的计算
使用此字典,演示了两种比对方式:图像之间的直接比较以及图像与数据库之间的比较,生成 Bag-of-Words 并比较它们的差异
#include "DBoW3/DBoW3.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
/***************************************************
* 本节演示了如何根据前面训练的字典计算相似性评分
* ************************************************/
int main( int argc, char** argv )
{
// read the images and database
cout<<"reading database"<<endl;
//DBoW3::Vocabulary vocab("./vocabulary.yml.gz");
DBoW3::Vocabulary vocab("/home/xiaohu/slambook-master/ch12/vocab_larger.yml.gz"); // use large vocab if you want:
if ( vocab.empty() )
{
cerr<<"Vocabulary does not exist."<<endl;
return 1;
}
cout<<"reading images... "<<endl;
vector<Mat> images;
for ( int i=0; i<10; i++ )
{
string path = "/home/xiaohu/slambook-master/ch12/data/"+to_string(i+1)+".png";
images.push_back( imread(path) );
}
// NOTE: in this case we are comparing images with a vocabulary generated by themselves, this may leed to overfitting.
// detect ORB features
cout<<"detecting ORB features ... "<<endl;
Ptr< Feature2D > detector = ORB::create();
vector<Mat> descriptors;
for ( Mat& image:images )
{
vector<KeyPoint> keypoints;
Mat descriptor;
detector->detectAndCompute( image, Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
}
// we can compare the images directly or we can compare one image to a database
// images :
cout<<"comparing images with images "<<endl;
for ( int i=0; i<images.size(); i++ )
{
DBoW3::BowVector v1;
vocab.transform( descriptors[i], v1 );
for ( int j=i; j<images.size(); j++ )
{
DBoW3::BowVector v2;
vocab.transform( descriptors[j], v2 );
double score = vocab.score(v1, v2);
cout<<"image "<<i<<" vs image "<<j<<" : "<<score<<endl;
}
cout<<endl;
}
// or with database
cout<<"comparing images with database "<<endl;
DBoW3::Database db( vocab, false, 0);
for ( int i=0; i<descriptors.size(); i++ )
db.add(descriptors[i]);
cout<<"database info: "<<db<<endl;
for ( int i=0; i<descriptors.size(); i++ )
{
DBoW3::QueryResults ret;
db.query( descriptors[i], ret, 4); // max result=4
cout<<"searching for image "<<i<<" returns "<<ret<<endl<<endl;
}
cout<<"done."<<endl;
}
自行训练字典
用rgbd_dataset_freiburg1_xyz训练字典
#include "DBoW3/DBoW3.h"
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <iostream>
#include <vector>
#include <string>
using namespace cv;
using namespace std;
int main( int argc, char** argv )
{
string dataset_dir = argv[1];
ifstream fin ( dataset_dir+"/associate.txt" );
if ( !fin )
{
cout<<"please generate the associate file called associate.txt!"<<endl;
return 1;
}
vector<string> rgb_files, depth_files;
vector<double> rgb_times, depth_times;
while ( !fin.eof() )
{
string rgb_time, rgb_file, depth_time, depth_file;
fin>>rgb_time>>rgb_file>>depth_time>>depth_file;
rgb_times.push_back ( atof ( rgb_time.c_str() ) );
depth_times.push_back ( atof ( depth_time.c_str() ) );
rgb_files.push_back ( dataset_dir+"/"+rgb_file );
depth_files.push_back ( dataset_dir+"/"+depth_file );
if ( fin.good() == false )
break;
}
fin.close();
cout<<"generating features ... "<<endl;
vector<Mat> descriptors;
Ptr< Feature2D > detector = ORB::create();
int index = 1;
for ( string rgb_file:rgb_files )
{
Mat image = imread(rgb_file);
vector<KeyPoint> keypoints;
Mat descriptor;
detector->detectAndCompute( image, Mat(), keypoints, descriptor );
descriptors.push_back( descriptor );
cout<<"extracting features from image " << index++ <<endl;
}
cout<<"extract total "<<descriptors.size()*500<<" features."<<endl;
// create vocabulary
cout<<"creating vocabulary, please wait ... "<<endl;
DBoW3::Vocabulary vocab;
vocab.create( descriptors );
cout<<"vocabulary info: "<<vocab<<endl;
vocab.save( "vocab_larger_train.yml.gz" );
cout<<"done"<<endl;
return 0;
}
结果:
generating features ...
[ INFO:0] Initialize OpenCL runtime...
extracting features from image 1
extracting features from image 2
extracting features from image 3
......
extracting features from image 788
extracting features from image 789
extracting features from image 790
extracting features from image 791
extracting features from image 792
extracting features from image 793
extract total 396500 features.
creating vocabulary, please wait ...
vocabulary info: Vocabulary: k = 10, L = 5, Weighting = tf-idf, Scoring = L1-norm, Number of words = 88334
done

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐


 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)