
Dify+LLaVA实现多模态应用
本文介绍了如何利用Dify平台部署开源多模态模型LLaVA。LLaVA是由微软与威斯康星大学联合开发的支持文本和图像理解的多模态AI,其特点包括:基于Vicuna/LLaMA2等开源模型、支持图像描述/视觉问答等任务、可在消费级GPU运行。部署步骤包含:1)通过Ollama拉取LLaVA-7B模型;2)在Dify中配置支持视觉的模型参数;3)创建工作流时启用文件上传功能,直接连接LLM节点处理图像
目录
前言
前面的文章有详细解读多模态的一系列知识点,现在我们使用Dify来进行简单的应用。
一、LLaVA 是什么?
LLaVA 由微软和威斯康星大学麦迪逊分校的研究团队开发,旨在让 AI 不仅能理解文本,还能处理图像信息。它类似于 OpenAI 的 GPT-4V(支持视觉的 GPT-4),但更轻量且开源。
二、LLaVA 的特点
-
多模态能力:可以同时理解文本和图像,适用于:
-
图像描述(Image Captioning)
-
视觉问答(Visual Question Answering, VQA)
-
文档理解(OCR + 推理)
-
视觉推理(如数学题、图表分析)
-
-
基于开源 LLM:
-
早期版本基于 Vicuna(类似 ChatGPT 的开源模型)
-
新版本(如 LLaVA-1.5)结合 CLIP 视觉编码器 和 LLaMA 2 / Mistral 语言模型
-
-
轻量化部署:
-
相比 GPT-4V,LLaVA 可在消费级 GPU(如 RTX 3090)上运行
-
三、本地部署LLaVA模型
1.打开cmd,输入ollama run llava:7b,即开始自动拉取模型,等待完成即可。
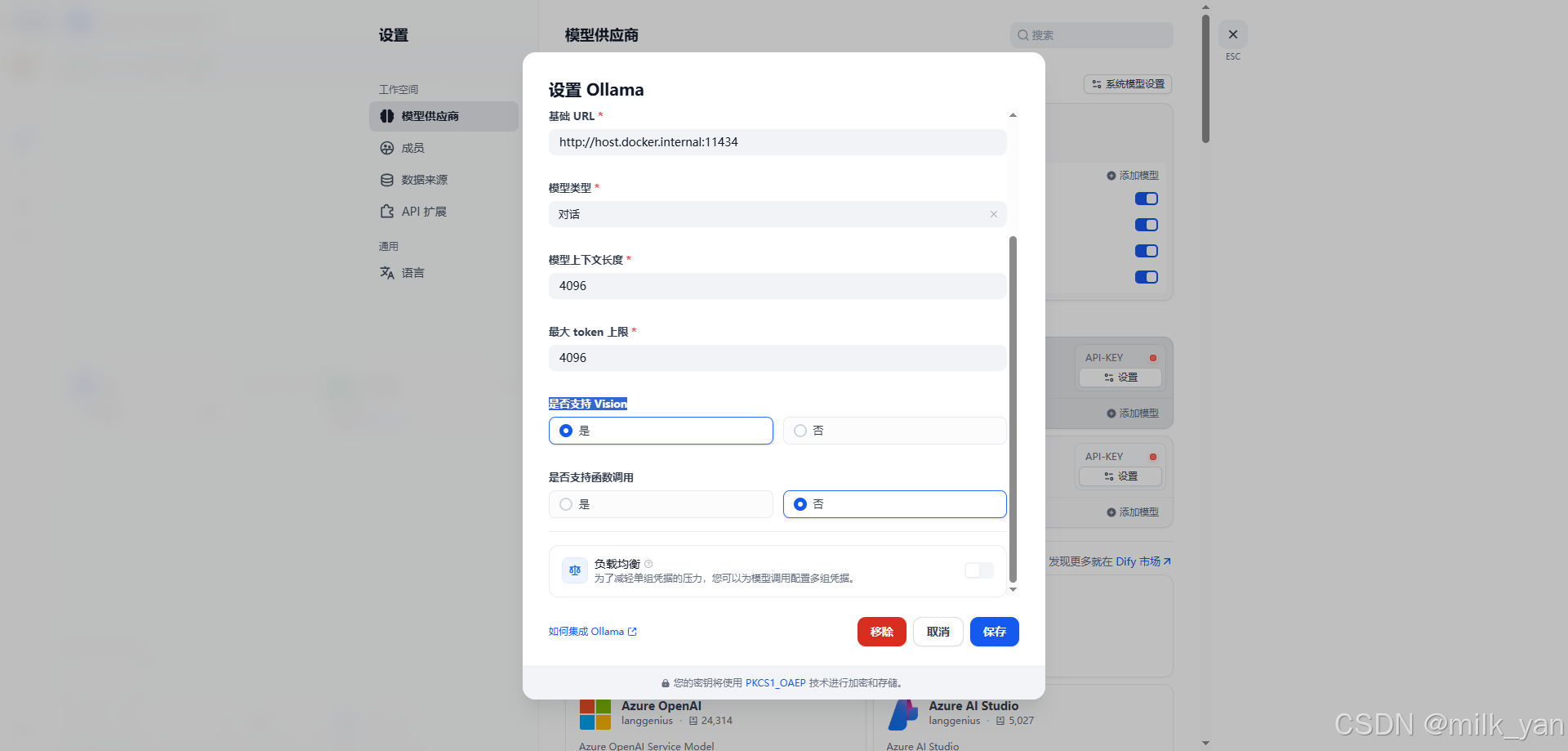
2.进入Dify设置界面添加llava模型,在是否支持 Vision选项中选择是,如下图所示:
四、Dify创建工作流
1.进入工作室,点击创建空白应用,选择工作流。
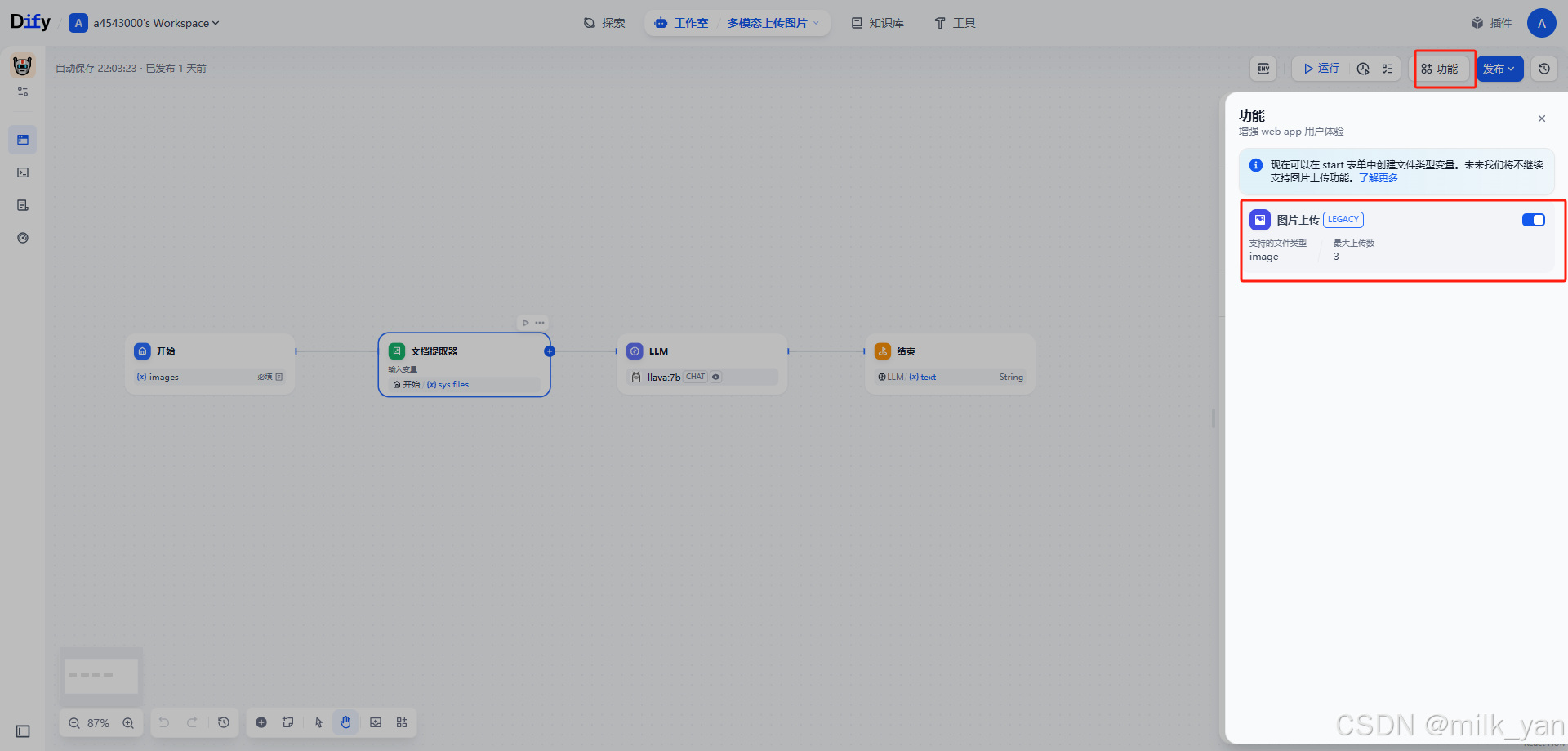
2.点击右上角的功能按钮,勾选文件上传
3.在开始节点添加必填的输入字段,然后设置为文件上传并添加文件的属性。
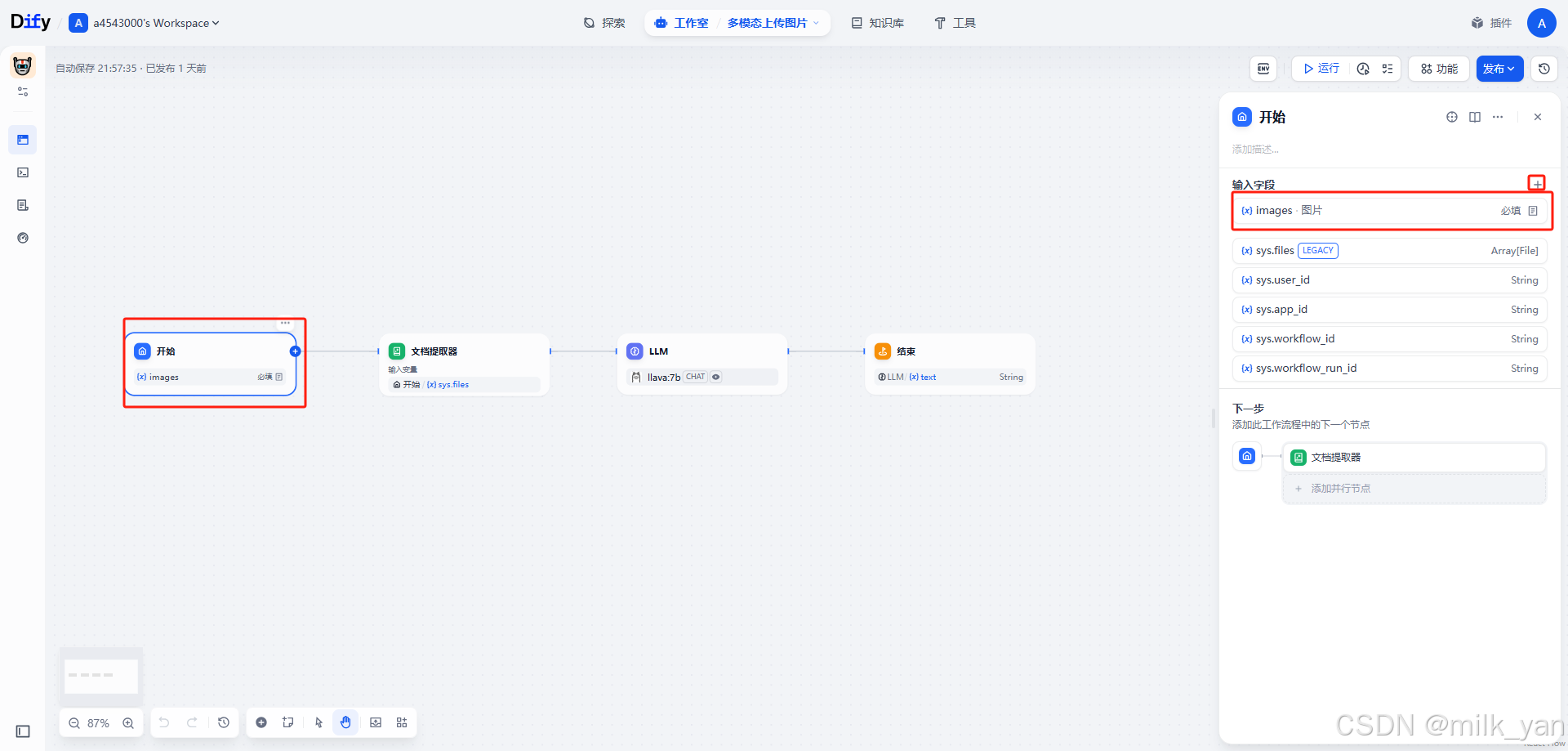
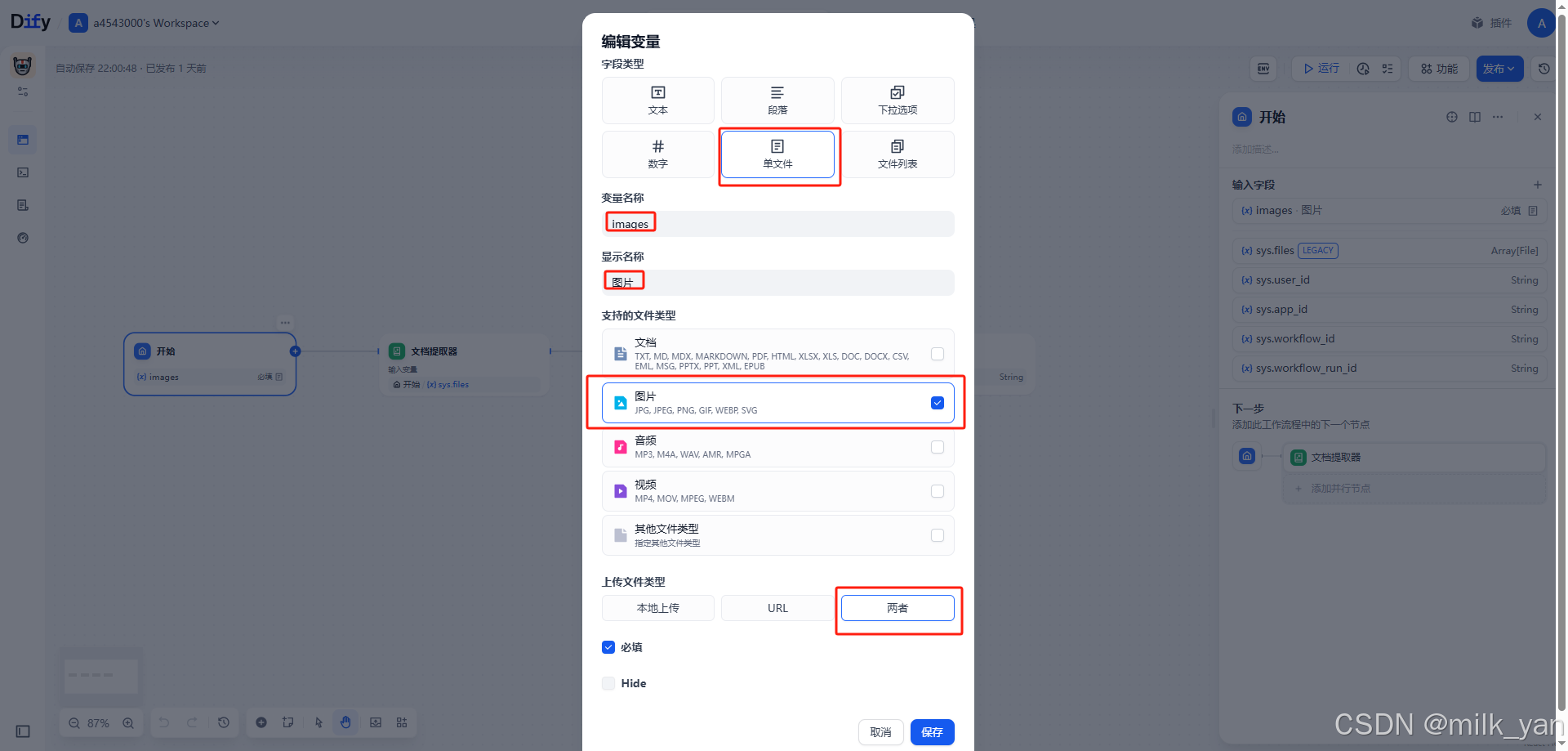
4.由于是多模态大模型,所以可以直接解析图片,所以不需要再加文档提取器了,直接对接我们的llm模型即可。点击llm节点选择我们的多模态模型,然后上下文选择我们的image变量,并且添加提示词:
这是用户上传的图片:
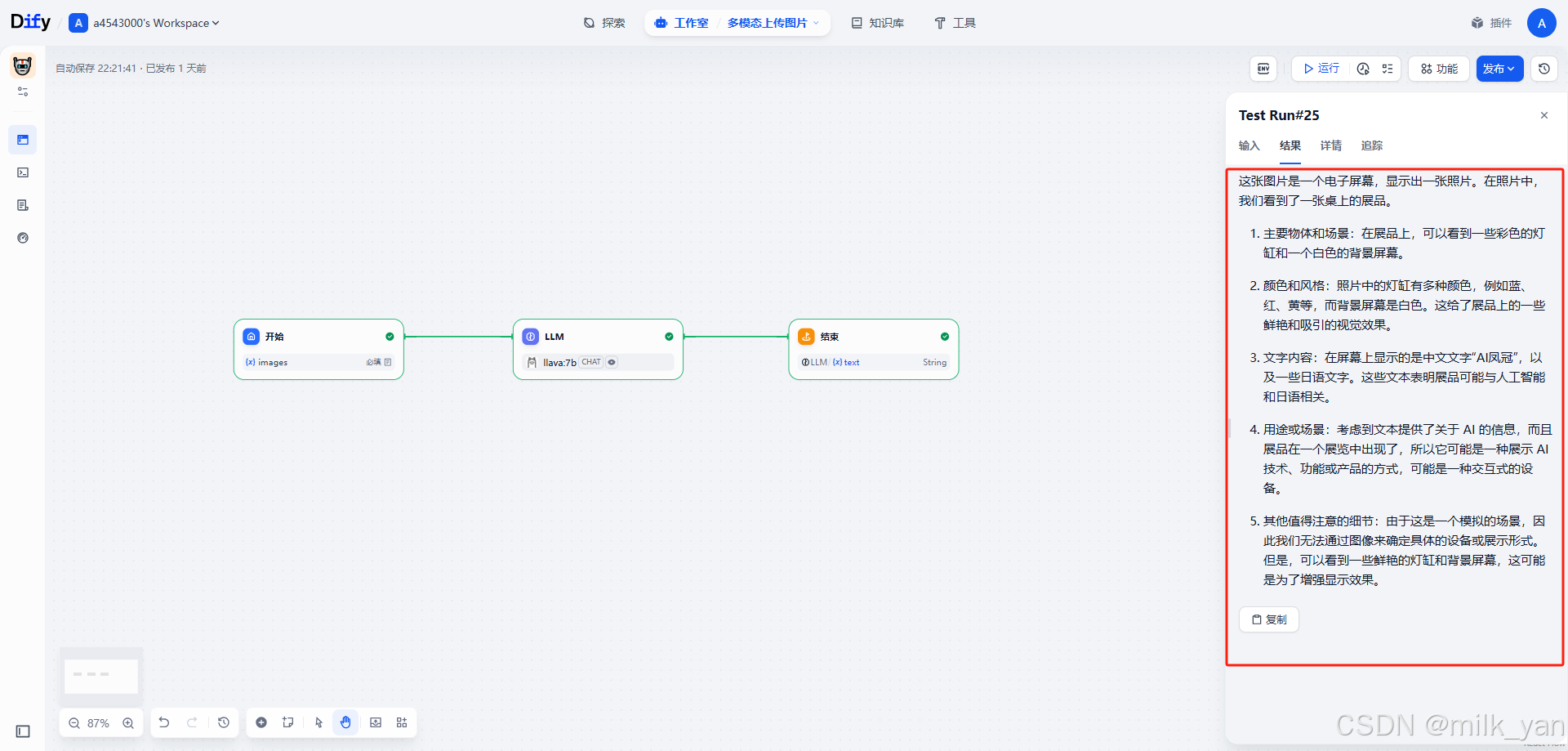
,你是一个专业的图片内容分析助手。请详细用中文描述这张图片的内容,包括:1. 主要物体和场景
2. 颜色和风格
3. 文字内容(如果有)
4. 可能的用途或场景
5. 其他值得注意的细节
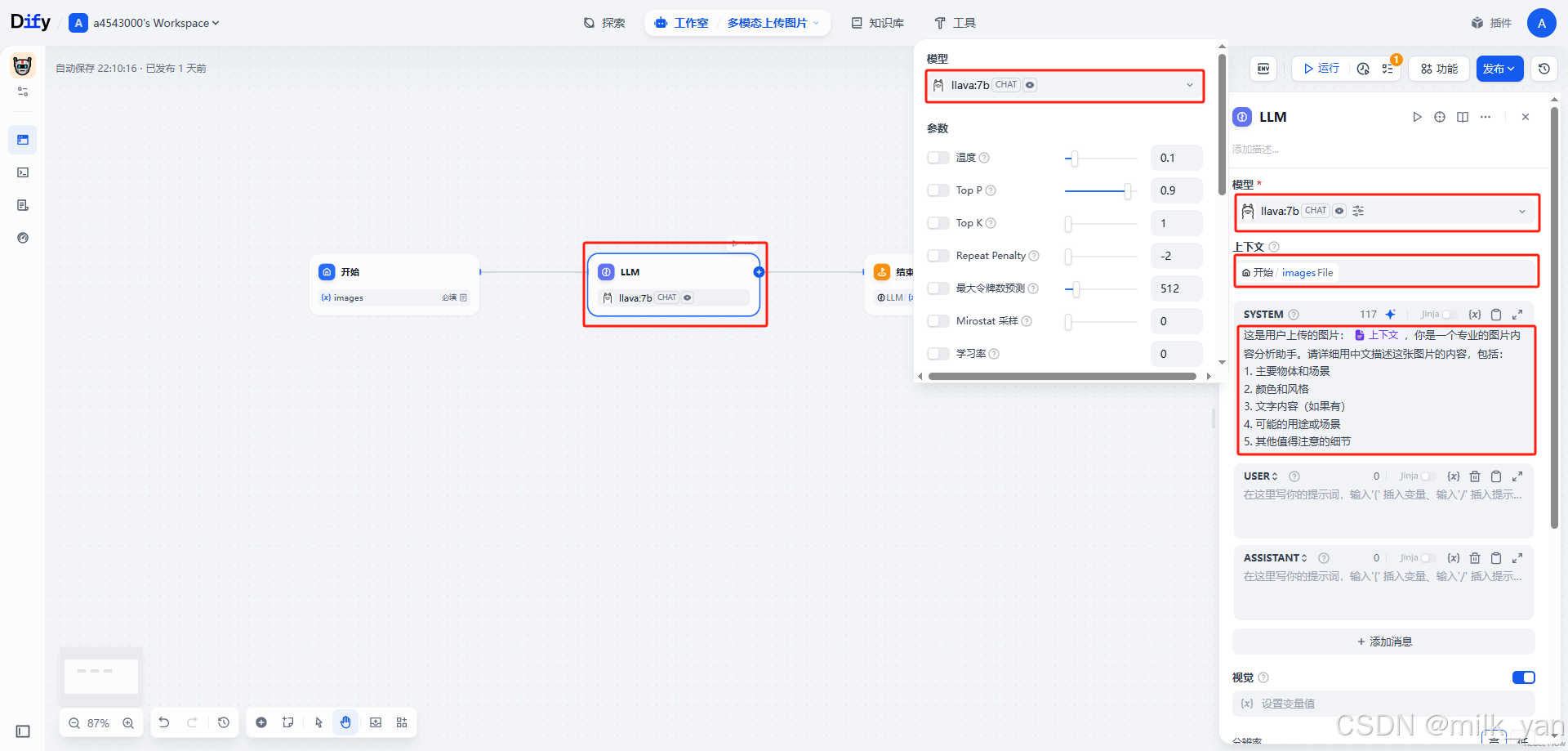
然后开启我们的视觉功能,并且分辨率选择高:

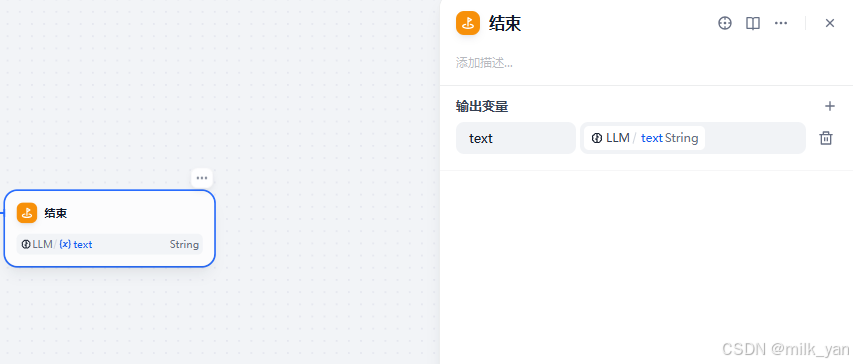
5.添加结束节点,直接输出大模型的文本。
五、运行测试应用
点击右侧上方的运行按钮,从本地上传一张图片,点击开始运行。
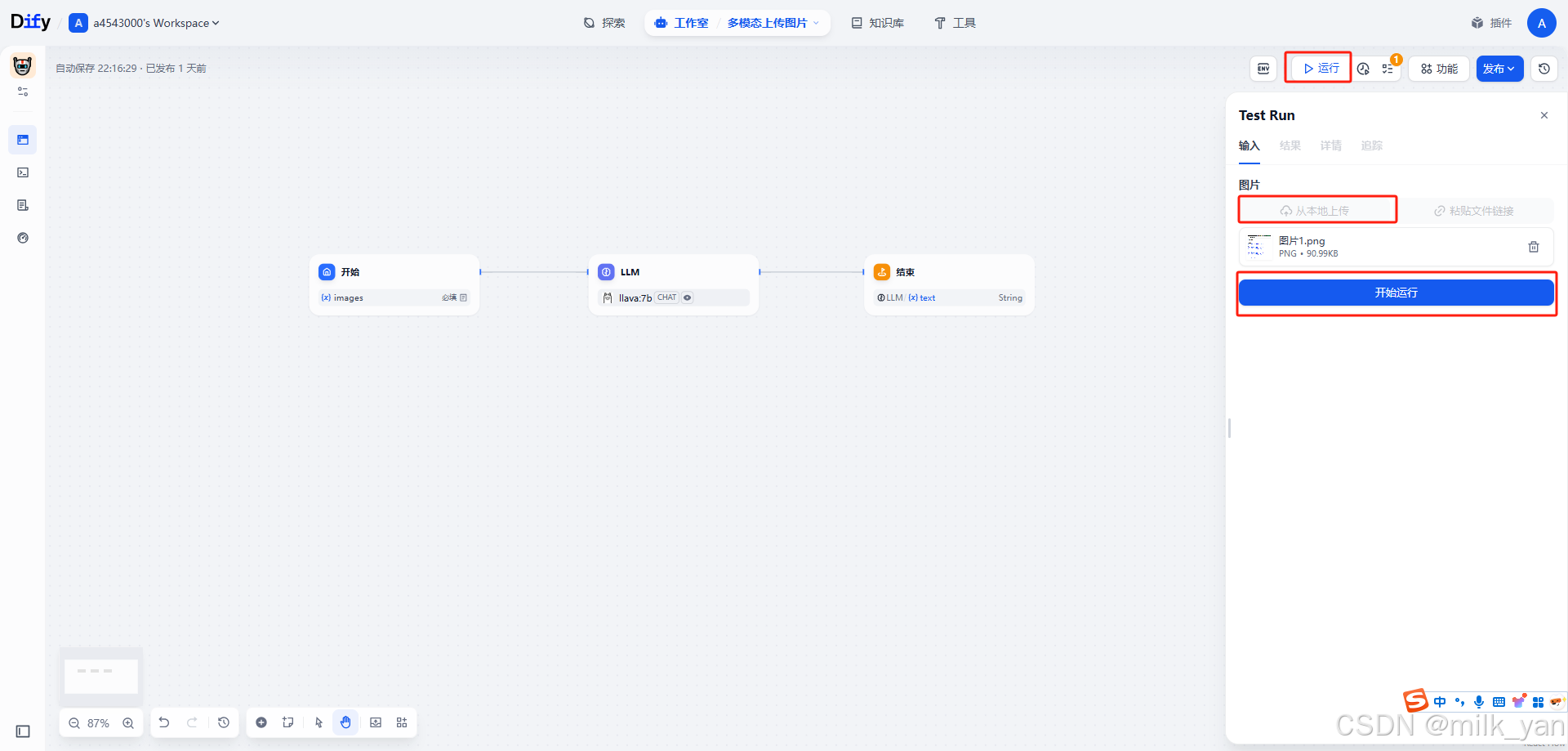
返回的结果会根据我们的提示词来对图片进行分析和解读。

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐


 32
32 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)