
【V100显卡】 用vllm本地部署 QWEN3
:/mnt/data/wen/wen/hub/models/JunHowie/Qwen3-14B-GPTQ-Int8 这个路径换成自己的模型路径。---指定Attention计算的后端实现,【这里是最大的坑】 因为v100不支持flash attn 所以要用以前的办法。---- 配置PyTorch的CUDA内存分配器。希望大家也能布起来 vllm的kv cache做的还是可以的。海鲜市场可以买到配
#vllm 对并发优势大 而且v100便宜 容易入手 #
自己手搓了一套v100 双卡拓展坞 用来创建个人知识库

海鲜市场可以买到配件 需要的可以自己diy
*****************************************************************************************************
因为v100比较老 我踩了很多坑才把qwen3 布上 现在分享给大家。
【先看效果】:
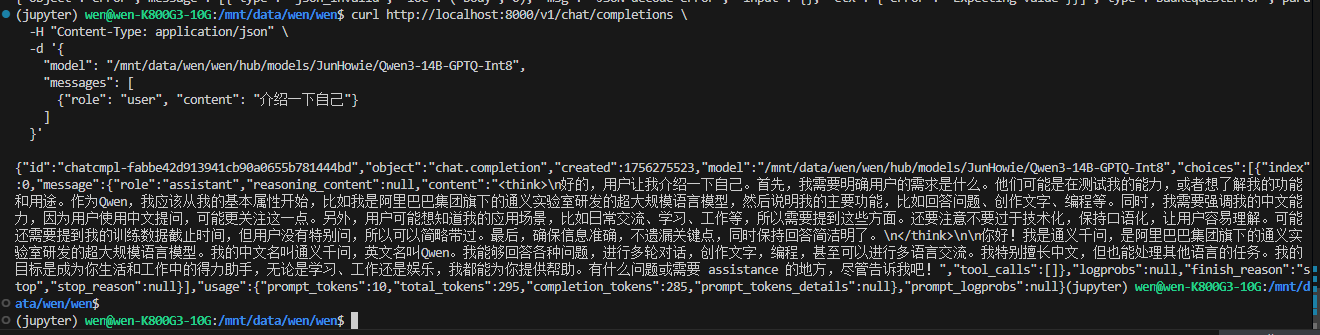
占用情况: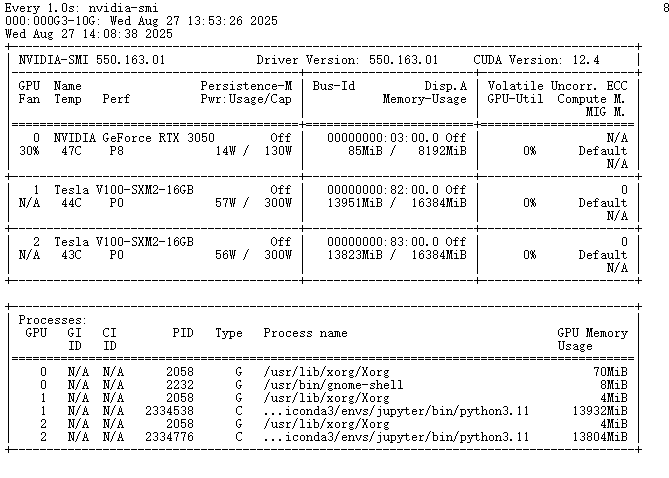
【启动代码】:
工具:首先要有vllm 版本号要是 0.8.5 系统是ubuntu
【踩坑】这里下了好几个版本的vllm 才找到 原来0.9以上不支持v100 而0.8.4以下不支持qwen3 如果运行会报错
bash代码
CUDA_VISIBLE_DEVICES=0,1 \
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True \
VLLM_WORKER_MULTIPROC_METHOD=spawn \
VLLM_ATTENTION_BACKEND=XFORMERS \
vllm serve /mnt/data/wen/wen/hub/models/JunHowie/Qwen3-14B-GPTQ-Int8 \
--tensor-parallel-size 2 \
--quantization gptq \
--dtype float16 \
--gpu-memory-utilization 0.85 \
--max-model-len 4096 \
--max-num-seqs 12 \
--host 0.0.0.0 \
--port 8000【注意!!!】:/mnt/data/wen/wen/hub/models/JunHowie/Qwen3-14B-GPTQ-Int8 这个路径换成自己的模型路径
【解释一下,这些都是踩过的坑】:
CUDA_VISIBLE_DEVICES=0,1
----双卡,指定显卡。
PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
---- 配置PyTorch的CUDA内存分配器。允许内存段动态扩展,减少内存碎片化,提高内存利用效率,避免OOM错误
VLLM_WORKER_MULTIPROC_METHOD=spawn
----指定vLLM工作进程的创建方式
VLLM_ATTENTION_BACKEND=XFORMERS
---指定Attention计算的后端实现,【这里是最大的坑】 因为v100不支持flash attn 所以要用以前的办法。
什么指定 --enforce-eager 、VLLM_ATTENTION_BACKEND=SDPA、 VLLM_USE_V1=0都没用
【注意】 有些情况需要加上这个:
export VLLM_USE_V1=0如果上面代码无法满足 可以尝试这个
正常启动就是这个样子啦:
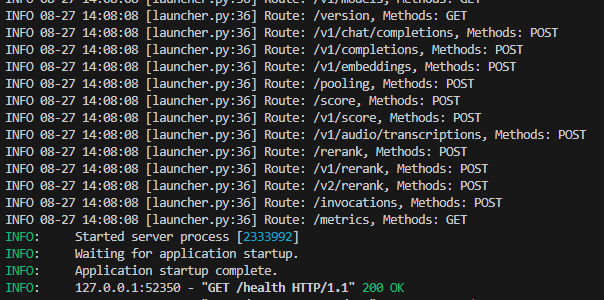
希望大家也能布起来 vllm的kv cache做的还是可以的
喜欢的麻烦点个赞和关注

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐

 26
26 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)