
一文吃透多模态:从定义到发展,详解 Transformer 与多模态任务对齐!
一文吃透多模态:从定义到发展,详解 Transformer 与多模态任务对齐!
在当今信息爆炸的时代,人类获取和处理信息的方式是多元的,我们通过文字阅读新闻、借助图像欣赏艺术、依靠音频聆听音乐,这些不同类型的信息载体共同构成了我们对世界的认知。而在人工智能领域,多模态技术正是模拟人类这种多元信息处理能力的关键。它打破了单一数据类型的局限,让机器能够像人类一样同时理解文本、图像、音频等多种信息,这一技术的发展正在深刻改变着人工智能与世界交互的方式,为各个领域带来了革命性的突破。
1、多模态概念与意义
多模态指的是能够处理和理解多种不同类型数据(如文本、图像、音频、视频等)的技术和方法。这些不同类型的数据被称为 “模态”,每种模态都有其独特的特征和表达方式。
多模态技术的意义重大,具体体现在以下几个方面:
- 符合人类认知习惯:人类在认识世界时通过多种感官获取信息并综合处理,多模态技术让机器更接近人类的认知模式,从而能更好地与人类交互。
- 融合信息弥补不足:多模态技术能够融合不同模态的信息,弥补单一模态的缺陷。例如,图像可以提供直观的视觉信息,但缺乏具体的描述,而文本可以补充详细内容,两者结合能让机器更全面地理解信息。
- 适配实际应用场景:在很多实际应用场景中,数据本身就是多模态的,如视频包含图像和音频,社交媒体内容包含文本和图像等。多模态技术能更好地处理这些实际数据,推动人工智能在智能客服、自动驾驶、医疗诊断等各个领域的应用。
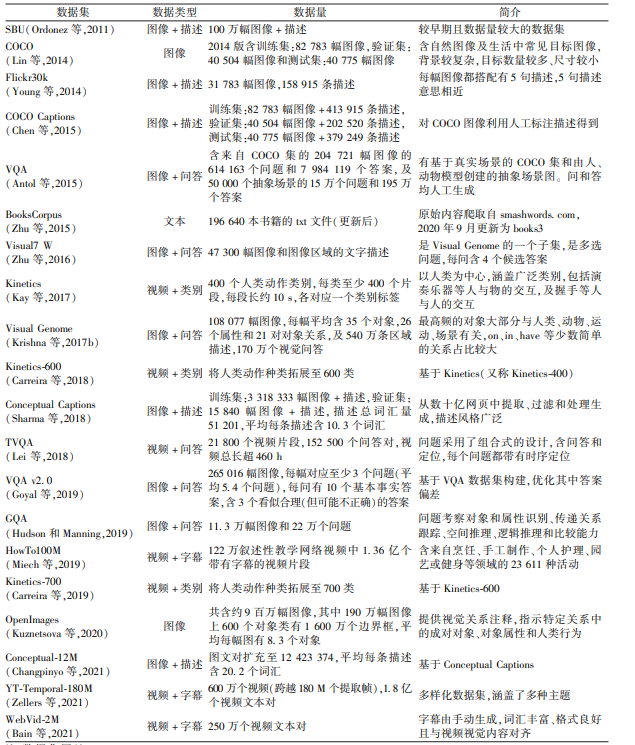
2、多模态任务类型及数据集
多模态大模型在许多领域都有广泛的应用,应用方向不限于自然语言处理、计算机视觉、音频处理等。具体任务又可以分为文本和图像的语义理解、图像描述、视觉定位、对话问答、视觉问答、视频的分类和识别、音频的情感分析和语音识别等。
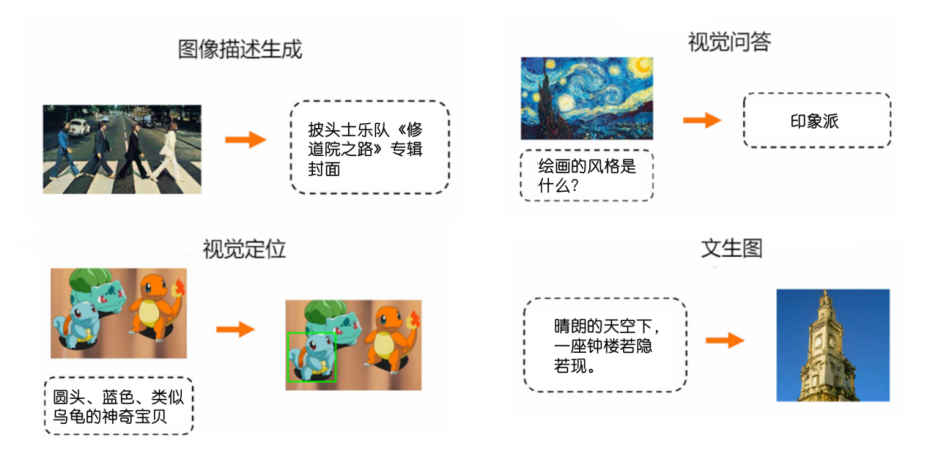
基础任务数据集版本:
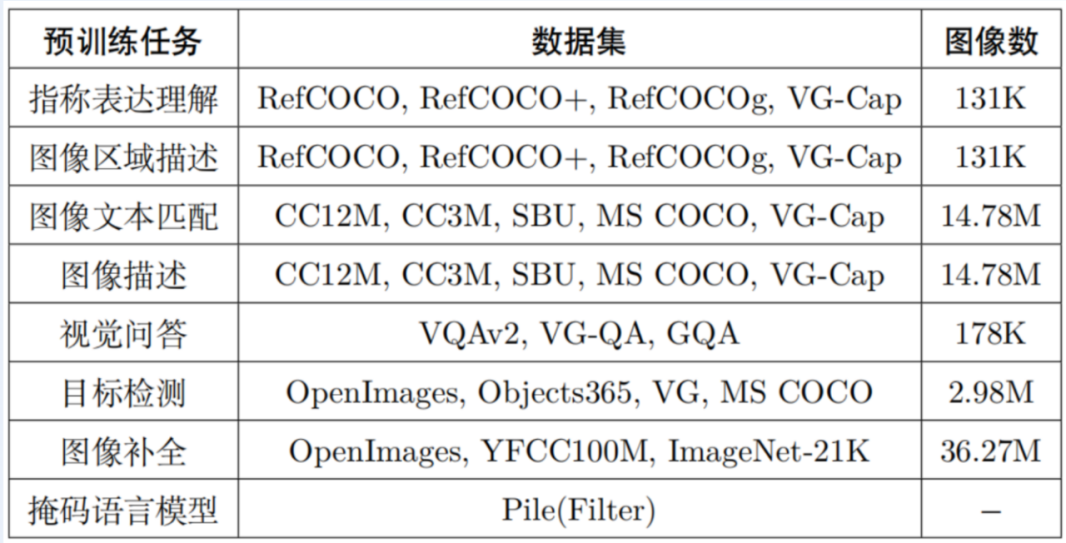
详细任务数据集版本:
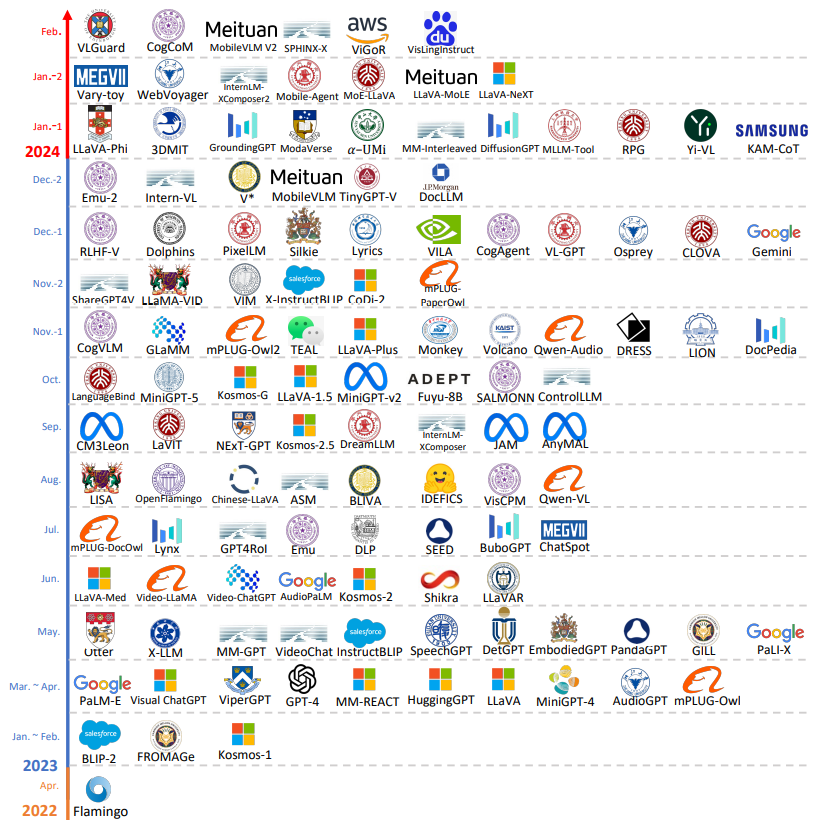
3、多模态模型发展关系及时间线
上述的大多多模态模型结构可以总结为五个主要关键组件,具体如下图所示:
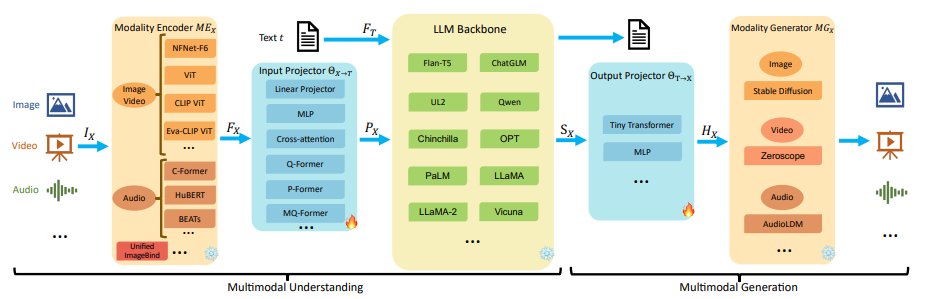
模态编码器(Modality Encoder, ME): 图像编码器(Image Encoder)、视频编码器(Video Encoder)、音频编码器(Audio Encoder)
输入投影器(Input Projector, IP): 线性投影器(Linear Projector)、多层感知器(Multi-Layer Perceptron, MLP)、交叉注意力(Cross-Attention)、Q-Former等
大模型基座(LLM Backbone): ChatGLM、LLaMA、Qwen、Vicuna等
输出投影器(Output Projector, OP): Tiny Transformer、Multi-Layer Perceptron (MLP)等
模态生成器(Modality Generator, MG): Stable Diffusion、Zeroscope、AudioLDM
按上述五部分结构对经典多模态模型进行总结,结果如下:
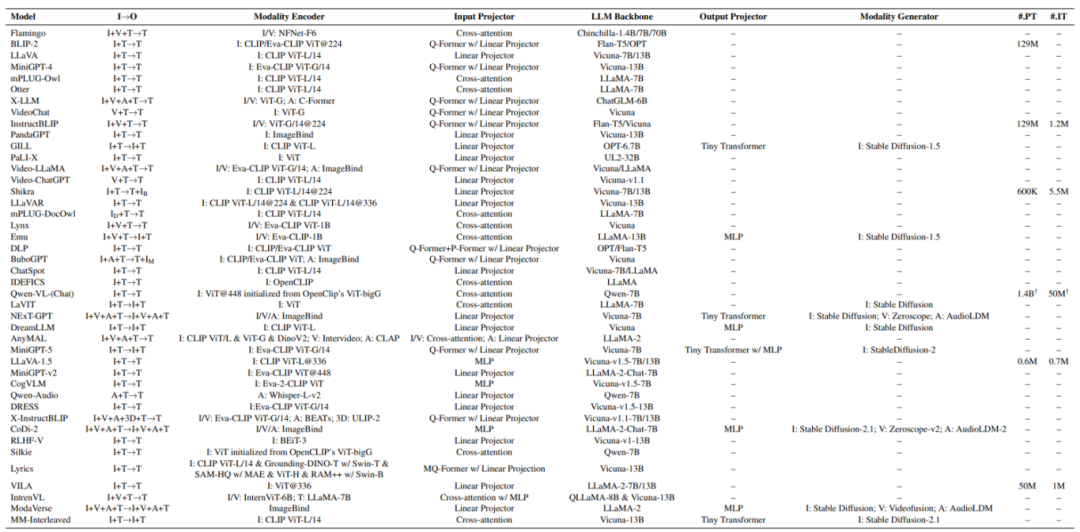
以VIT为基础视觉预训练可以通过Transformers模型对视觉进行有效表征,逐渐成为视觉信息编码的主流手段。此部分主要梳理以VIT为延伸的预训练和多模态对齐工作,具体分类如下:
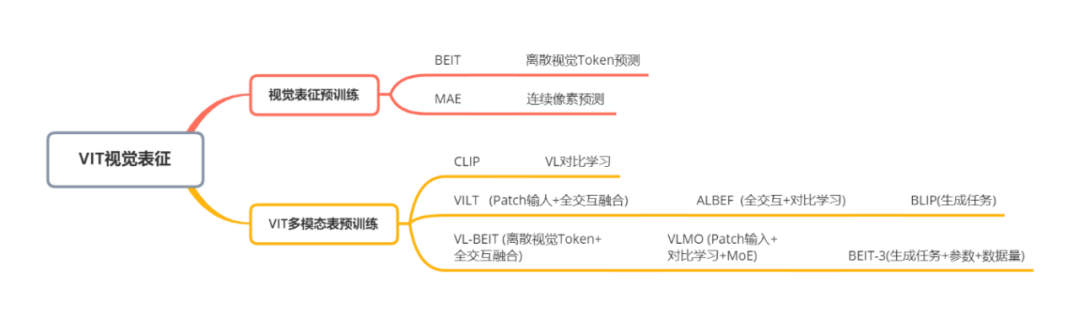
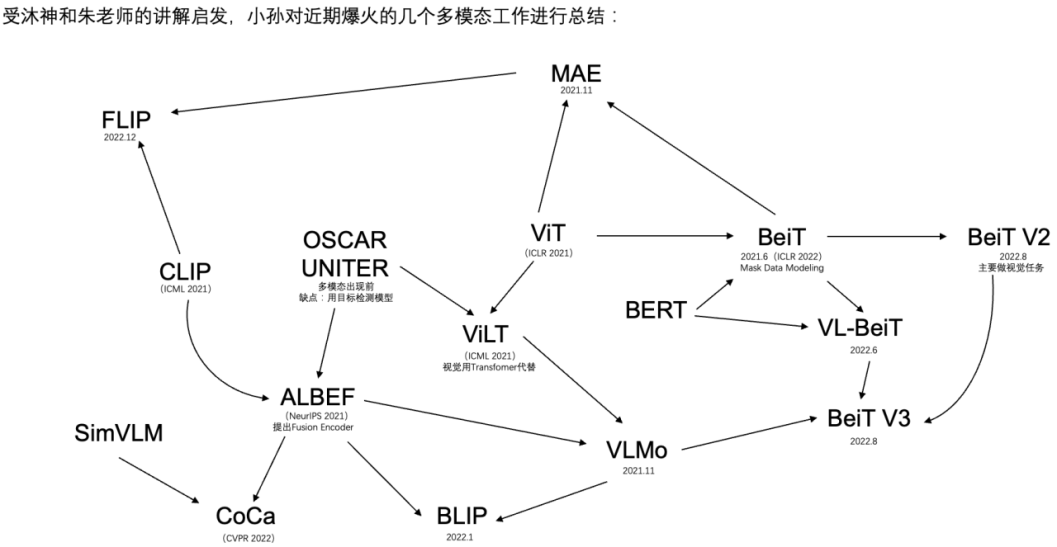
上述多模态预训练模型发展关系如下:
4、多模态基础知识–Transformer
Transformer 是一种基于自注意力机制的神经网络模型,它在自然语言处理领域取得了巨大成功,同时也成为了多模态模型的重要基础。
目前,主流的多模态大模型大多以Transformer为基础。Transformer是一种由谷歌在2017年提出的深度学习模型,主要用于自然语言处理(NLP)任务,特别是序列到序列(Sequence-to-Sequence)的学习问题,如文本生成。Transformer彻底改变了之前基于循环神经网络(RNNs)和长短期记忆网络(LSTMs)的序列建模范式,并且在性能提升上取得了显著成效。Transformer结构如下图所示:
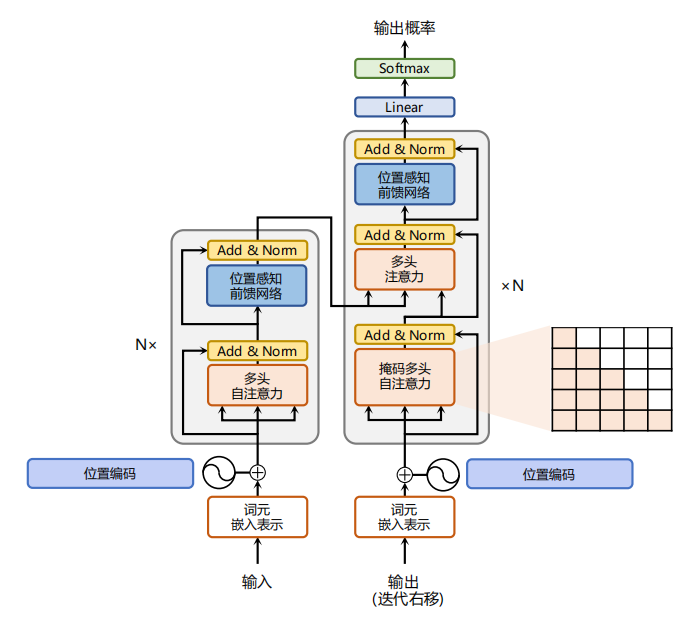
Transformer的核心构成包括:
自注意力机制(Self-Attention Mechanism): Transformer模型摒弃了传统RNN结构的时间依赖性,通过自注意力机制实现对输入序列中任意两个位置之间的直接关联建模。每个词的位置可以同时关注整个句子中的其他所有词,计算它们之间的相关性得分,然后根据这些得分加权求和得到该位置的上下文向量表示。这种全局信息的捕获能力极大地提高了模型的表达力。
多头注意力(Multi-Head Attention): Transformer进一步将自注意力机制分解为多个并行的“头部”,每个头部负责从不同角度对输入序列进行关注,从而增强了模型捕捉多种复杂依赖关系的能力。最后,各个头部的结果会拼接并经过线性变换后得到最终的注意力输出。
位置编码(Positional Encoding): 由于Transformer不再使用RNN的顺序处理方式,为了引入序列中词的位置信息,它采用了一种特殊的位置编码方法。这种方法对序列中的每个位置赋予一个特定的向量,该向量的值与位置有关,确保模型在处理过程中能够区分不同的词语顺序。
编码器-解码器架构(Encoder-Decoder Architecture): Transformer采用了标准的编码器-解码器结构,其中,编码器负责理解输入序列,将其转换成高级语义表示;解码器则依据编码器的输出,结合自身产生的隐状态逐步生成目标序列。在解码过程中,解码器还应用了自注意力机制以及一种称为“掩码”(Masking)的技术来防止提前看到未来要预测的部分。
残差连接(Residual Connections): Transformer沿用了ResNet中的残差连接设计,以解决随着网络层数加深带来的梯度消失或爆炸问题,有助于训练更深更复杂的模型。
层归一化(Layer Normalization): Transformer使用了层归一化而非批量归一化,这使得模型在小批量训练时也能获得良好的表现,并且有利于模型收敛。
5、多模态任务对齐
本文以文本和图像的多模态数据对齐为例:
1、 文本转Embedding
Tokenization:
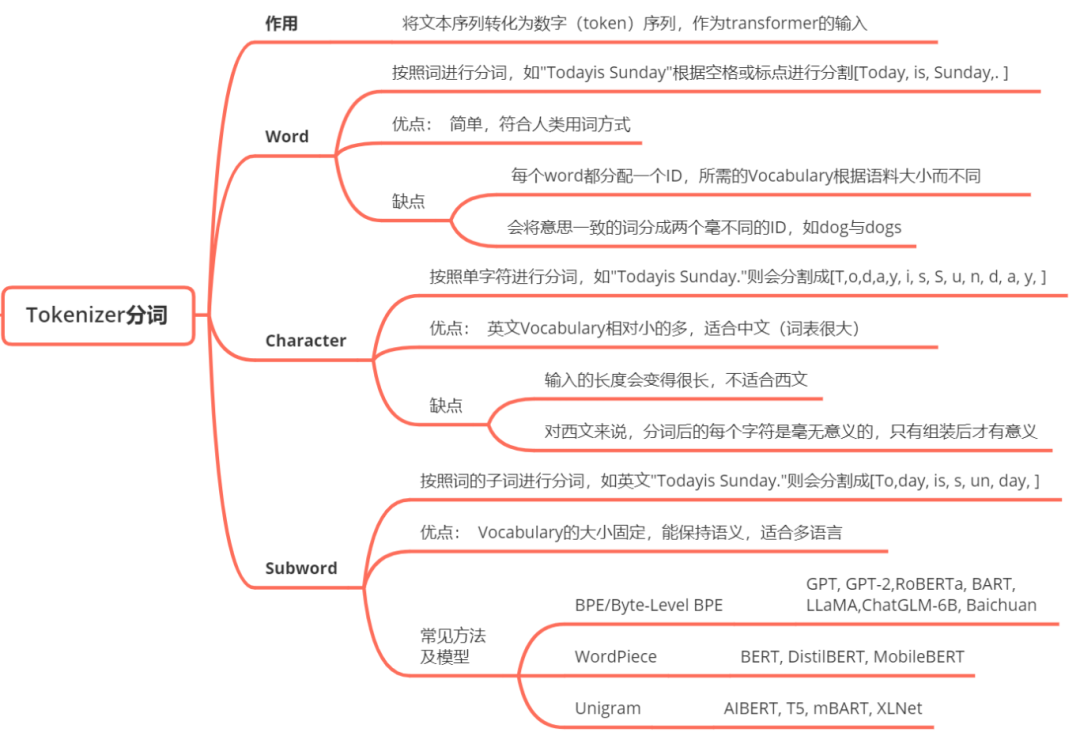
Tokenization也称作分词,是把一段文本切分成模型能够处理的token或子词的过程,通常会使用BPE或WordPiece的分词算法,有助于控制词典大小的同时保留了表示文本序列的能力。Tokenization的知识点总结如下:
Embedding:
Embedding将token或子词用映射到多维空间中的向量表示,用以捕捉语义含义。这些连续的向量使模型能够在神经网络中处理离散的token,从而使其学习单词之间的复杂关系。经典的文本转Embedding可采用 Tramsformer(bert) 模型
具体步骤:
- 输入文本:“thank you very much”
- Tokenization后: [“thank”, “you”, “very”,“much”]
- Embedding:假设每个token被映射到一个2048维的向量,“thank you very much”被转换成4*2048的embeddings
2、图像转换Embedding
图像转Emdedding一般采用Vit Transformer模型。首先,把图像分成固定大小的patch,类比于LLM中的Tokenization操作;然后通过线性变换得到patch embedding,类比LLM中的Embedding操作。由于Transformer的输入就是token embeddings序列,所以将图像的patch embedding送入Transformer后就能够直接进行特征提取,得到图像全局特征的embeddings。具体步骤如下:
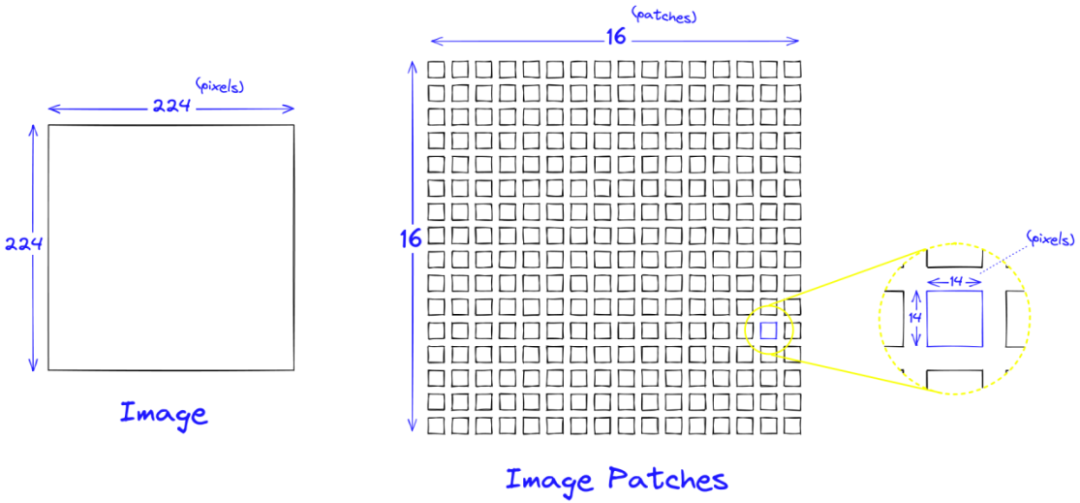
图像预处理:
- 输入图像大小:224x224像素,3个颜色通道(RGB)+ 预处理:归一化,但不改变图像大小图像切分:
- 假设每个patch大小为14x14像素,图像被切分成(224/14) × (224/14) =256个patches 线性嵌入:
- 将每个14x14x3的patch展平成一个一维向量,向量大小为 14×14×3=588
- 通过一个线性层将每个patch的向量映射到其他维的空间(假设是D维),例如D=768 , 每个patch被表示为一个D维的向量。最后,由于Transformer内部不改变这些向量的大小,就可以用256*768的embeddings表示一张图像。
3、模态对齐
上述介绍文本和图像都被转换成向量的形式,但这并不意味着它们可以直接结合使用。问题在于,这两种模态的向量是在不同的向量空间中学习并形成的,它们各自对事物的理解存在差异。例如,图像中“小狗”的Embedding和文本中“小狗”的Embedding,在两种模态中的表示可能截然不同。这就引出了一个重要的概念——模态对齐。

那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~
👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐

 31
31 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)