
自动驾驶中的环境感知 学习笔记
自动驾驶系统包含感知,决策和控制这三个主要模块。进一步来说,感知系统又包含了环境感知和车辆定位两个任务。环境感知利用各种传感器(摄像头、激光雷达、毫米波雷达等)检测各种移动和静止的障碍物(车辆、行人、建筑物等),以及收集道路上的各种信息。车辆定位则根据环境感知得到的信息来确定车辆在环境中所处位置,这里需要高精度地图,以及惯性导航(IMU)和全球定位系统(GPS)的辅助。对于环境感知系统,主要会用到
本文内容整理主要来自知乎用户@巫婆塔里的工程师 发布的文章,建议大家去看原文(一位很有深度,专业性极强的宝藏博主,搬运的目的也是为了记录自己学习的过程,没有其他用途)侵权删。
1.前言
自动驾驶系统包含感知,决策和控制这三个主要模块。进一步来说,感知系统又包含了环境感知和车辆定位两个任务。环境感知利用各种传感器(摄像头、激光雷达、毫米波雷达等)检测各种移动和静止的障碍物(车辆、行人、建筑物等),以及收集道路上的各种信息。车辆定位则根据环境感知得到的信息来确定车辆在环境中所处位置,这里需要高精度地图,以及惯性导航(IMU)和全球定位系统(GPS)的辅助。
对于环境感知系统,主要会用到摄像头、激光雷达和毫米波雷达这三种主要的传感器以及他们的融合。摄像头是感知系统中最常用的传感器,优势在于能够提取丰富的纹理和颜色信息,因此适用于目标的分类。但是其缺点在于对于距离的感知能力较弱,并且受光照条件影响较大。激光雷达在一定程度上弥补了摄像头的缺点,可以精确的感知物体的距离和形状,因此适用于中近距的目标检测和测距。但是其缺点在于成本较高,量产难度大,感知距离有限,而且同样受天气影响较大。毫米波雷达具有全天候工作的特点,可以比较精确的测量目标的速度和距离,感知距离较远,价格也相对较低,因此适用于低成本的感知系统或者辅助其它的传感器。但是缺点在于高度和横向的分辨率较低,对于静止物体的感知能力有限。
2.技术概览
环境感知系统的硬件基础是多种传感器以及他们的组合,而软件方面的核心则是感知算法。感知算法主要完成两个主要的任务:物体检测和语义分割。前者得到的是场景中重要目标的信息,包括位置,大小,速度等,是一种稀疏的表示;而后者得到的是场景中每一个位置的语义信息,比如可行驶,障碍物等,是一种稠密的表示。这两个任务的结合被称为全景分割。对于物体目标(比如车辆,行人),全景分割输出其分割Mask(分割区域),类别和实例ID;对于非物体目标(比如道路,建筑物),则只输出其分割Mask和类别。环境感知系统的终极目标就是要得到车辆周边三维空间中全景分割结果。当然对于不同级别,不同场景下的自动驾驶应用来说,需要的感知输出不也尽相同。
在自动驾驶环境感知中,深度学习最先取得应用的任务是单张二维图像中的物体检测。这个领域中的经典算法,比如Faster R-CNN,YOLO,CenterNet等都是不同时期视觉感知算法的主流。但是,车辆不能仅仅依靠一张二维图像上的检测结果来行驶。因此,为了满足自动驾驶应用的需求,这些基础的算法还需要进行进一步的扩展,其中最重要的就是融合时序信息和三维信息。前者衍生出了物体跟踪算法,后者衍生出了单目/双目/多目的三维物体检测算法。以此类推,语义分割包含了图像语义分割,视频语义分割,稠密深度估计。
概括一下上面这段,物体检测的演进:单帧检测->时序跟踪->三维检测;语义分割的演进:图像语义分割->视频语义分割->稠密深度估计
为了得到更加精确的三维信息,激光雷达也一直是自动驾驶感知系统的重要组成部分,尤其是对于L3/4级别的应用。激光雷达的数据是相对稀疏的点云,这与图像稠密的网格结构差别非常大,因此图像领域常用的算法需要经过一定的改动才能应用到点云数据。点云感知的任务也可以按照物体检测和语义分割来划分,前者输出三维的物体边框,而后者输出点云中每个点的语义类别。为了利用图像领域的算法,点云可以转换为鸟瞰视图(Bird's Eye View)或者前视图(Range View)下的稠密网格结构。此外,也可以改进深度学习中的卷积神经网络(Convolutional Neural Network, CNN),使其适用于稀疏的点云结构,比如PointNet或者Graph Neural Network。
毫米波雷达由于其全天候工作,测速准确,以及低成本的特点,也被广泛的用于自动驾驶感知系统中,不过一般应用在L2级别的系统中,或者在L3/4级系统中作为其它传感器的辅助。毫米波雷达的数据一般来说也是点云,但是比激光雷达的点云更为稀疏,空间分辨率也更低。相比于摄像头和激光雷达,毫米波雷达的数据密度非常低,因此一些传统方法(比如聚类和卡尔曼滤波)表现的并不比深度学习差很多,而这些传统方法的计算量相对较低。最近几年来,开始有研究者从更底层的数据出发,用深度学习代替经典的雷达信号处理,通过端对端的学习取得了近似激光雷达的感知效果。
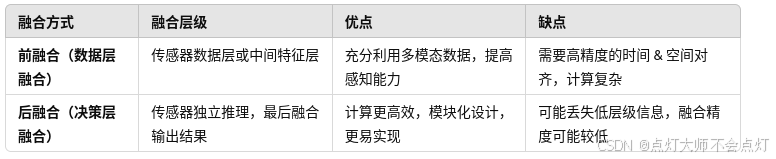
单个传感器的感知能力总是有限的,如果把系统成本先放在一边,多传感器融合的方案自然更好的选择。一般来说,摄像头是感知系统的必备的传感器,为了得到深度信息和360度的视场,可以采用双目或者多目融合的方案。为了更准确的获得三维和运动信息,摄像头也可以与激光雷达和毫米波雷达进行融合。这些传感器的坐标系不同,数据形式不同,甚至采集频率也不同,因此融合算法的设计并不是一件简单的任务。粗略来说,融合可以在决策层(融合不同传感器的输出)或者数据层(融合不同传感器的数据或者中间结果)来进行。数据层融合理论上说是更好的方法,但是对传感器之间的空间和时间对齐要求会更高。
3.行业现状
粗略来说,自动驾驶公司可以分为两大类别。一类是传统的车企(比如国外的大众,宝马,通用,丰田等,国内的长城,吉利等),新能源车企(比如特斯拉,蔚来,小鹏等)和Tier1(一级供应商,供应关键零部件或系统的供应商,比如国外老牌的博世,大陆,安波福等,以及国内新兴的华为,大疆等)。这类公司的首要目标是量产,一般以L2级别方案为主,目前也在向L3级别扩展。另外一类是一些方案提供商或者初创公司(比如Waymo,Mobileye,Pony.AI,Momenta,TuSimple等)。这些公司致力于发展L4级别的自动驾驶技术,面向的是诸如Robotaxi,Robotruck和Robobus之类的应用。
对于不同的自动驾驶级别,不同的应用场景,传感器的配置方案也不尽相同。对于L2级别的应用,比如紧急制动和自适应巡航,可以只采用前视单目摄像头或者前向毫米波雷达。如果需要变道辅助功能,则需要增加传感器对相邻车道进行感知。常用的方案是在车头和车尾增加多个角雷达,以实现360度的目标检测能力。对于L3级别的应用,需要在特定场景下实现车辆的完全自主驾驶,因此需要扩展车辆对周边环境的感知能力。这时就需要增加激光雷达,侧视和后视的摄像头和毫米波雷达,以及GPS,IMU和高精度地图来辅助车辆定位。到了L4级别以后,由于在特定场景下不需要人工接管了,传感器就不仅需要高精确度,还需要高可靠性。这就需要增加传感器的冗余性,也就是说需要备用系统。

分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐


 45
45 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)