
毕业设计:基于双目视觉的果实目标检测与定位系统 人工智能
毕业设计:基于双目视觉的果实目标检测与定位系统利用深度学习和计算机视觉技术实现果实目标的精确检测和定位。通过分析双目图像的深度信息和视差信息,我们设计了一个高效的果实目标检测和定位系统。该系统在果实识别和定位方面取得了显著的性能提升,并在实际农业生产中展示了广阔的应用前景。为计算机毕业设计提供了一个有意义的研究课题,结合了深度学习和计算机视觉技术,对于计算机专业、软件工程专业、人工智能专业、大数据
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于双目视觉的果实目标检测与定位系统
课题背景和意义
随着农业行业的发展和人们对食品质量与安全的关注增加,果实目标检测与定位成为了一个重要的研究领域。传统的图像处理方法在果实目标检测与定位任务中存在着一定的局限性,而基于深度学习和计算机视觉技术的双目视觉系统提供了一种创新的解决方案。通过利用双目图像的深度信息和视差信息,该系统可以实现对果实目标的准确检测和定位,为农业生产提供精确的数据支持。这项研究具有重要的理论和实际意义,可以提高果实检测与定位的精度和效率,为农业机械化、智能化以及精准农业发展提供技术支持。
实现技术思路
一、算法理论基础
1.1 卷积神经网络
在神经网络中,神经元是其基本组成单元之一。神经元是受到生物神经元启发而设计的数学模型,用于模拟人工神经网络的工作原理。每个神经元接收一组输入信号,并通过激活函数对这些输入进行加权求和,然后产生一个输出。这个输出可以作为其他神经元的输入,形成网络中的连接和传递信息的路径。神经元的主要组成部分包括权重(Weights)、偏置(Bias)和激活函数(Activation Function):
- 权重表示每个输入信号的重要性,通过调整权重可以控制不同输入对神经元输出的影响程度。
- 偏置是一个常数,用于调整神经元的激活阈值,影响神经元是否激活。
- 激活函数将加权求和后的输入转换为神经元的输出。常见的激活函数包括Sigmoid、ReLU、Tanh等,它们引入了非线性特性,使得神经网络能够学习和表示更复杂的函数关系。

卷积神经网络是一种包含卷积计算并存在深度结构的前反馈神经网络,能够处理具有网格结构的数据,特别适用于图像处理任务。CNN的结构包括输入层、卷积层、激活层、池化层、全连接层和输出层。输入层接收数据,通常为RGB三通道的图像,经过预处理后送入卷积层进行特征提取。卷积层采用卷积操作和权值矩阵(卷积核)来提取输入图像的特征,随着层数的增加,可以提取更复杂的语义特征信息。激活层对卷积层输出的结果进行非线性变换,引入非线性特性。池化层夹在连续的卷积层之间,通过下采样保留关键信息,减少数据维度和过拟合风险。全连接层在网络尾部,整合之前提取的特征信息。输出层是CNN的最后一层,负责输出目标的类别信息和位置信息。通过这些层的组合和堆叠,CNN能够自动学习图像中的特征表示,在目标检测、分类和其他计算机视觉任务中具备强大的自适应学习能力。

1.2 目标检测算法
目标检测方法可分为基于图像特征和基于图像分割两种。基于特征的检测方法通过设定的特征或算法提取抽象特征来进行目标识别和检测。而基于图像分割的检测方法则利用目标的颜色、形状和边缘等特性来实现目标的识别和检测。传统目标检测算法一般包括四个步骤:首先,使用不同尺寸的滑动窗口自上而下、从左到右逐步选择图像中的一部分作为候选区域;接下来,对候选区域进行特征提取;然后,将提取的特征输入分类器进行分类识别;如果候选区域具有较高的分类概率,则将其标记为目标;最后,对图像进行后处理操作,如使用非极大值抑制(NMS)来消除多余的候选框,以获得最佳的目标框,并输出结果图像。这些传统的方法虽然在一定程度上能够完成目标检测任务,但通常需要手动选择和设计特征,并且在复杂场景下性能可能有限。

RCNN算法的原理是,首先使用选择性搜索(Selective Search)在输入图像中生成可能包含目标物体的候选区域。选择性搜索通过不同尺度的滑动窗口在图像中自下而上地搜索,生成大约2000个不同大小的候选区域。然后,对每个候选区域进行尺度变换,将其变为固定大小(例如227x227)的图像块,并输入到卷积神经网络(CNN)中进行特征提取。最后,将提取到的特征图传入支持向量机(SVM)进行分类识别和定位回归。由于RCNN需要将每个候选区域都传入CNN进行特征提取,并使用SVM进行分类和回归,因此计算量非常大,耗时较长,无法满足实际目标检测的需求。
为了改进RCNN的计算效率,Fast-RCNN算法提出了一种改进方法。它使用整个图像作为输入,归一化后送入CNN进行特征提取,不再使用卷积层进行特征提取。相反,在最后一个池化层中加入了候选区域的坐标信息来计算特征。Fast-RCNN的网络结构包括ROI(Region of Interest)池化层,它通过将每个候选区域均匀划分为MxN的网格,并对每个网格进行最大池化,以得到固定大小的特征向量。然后,将这些特征向量传入下一层进行分类和回归。与RCNN相比,Fast-RCNN具有更快的训练和检测速度。它将目标分类和候选区域回归统一到CNN中,减少了特征存储和处理的开销。

1.3 双目测距
Bouguet双目校正算法是一种用于双目视觉的校正方法,通过相机标定和图像处理,实现了双目图像的对齐和立体匹配。算法的步骤包括图像采集、特征提取、相机标定、立体校正和立体匹配。首先,通过双目摄像头采集一组图像序列,其中包括校准板图案在不同位置和姿态下的图像。校准板上的特殊图案提供已知的几何特征,用于相机标定。然后,从图像序列中提取校准板的特征点,例如角点,通过图像处理算法获得。接下来,利用提取到的校准板特征点,进行相机标定,通过相机标定方法计算出相机的内部参数和外部参数。然后,根据相机的内部参数和外部参数,进行双目图像的立体校正,通过计算校正变换矩阵对左右图像进行透视矫正和像素重采样,保持它们在水平方向上的一致性。最后,在校正后的图像上进行立体匹配,根据图像的像素强度、颜色、纹理等信息,使用立体匹配算法找到左右图像中对应的特征点或像素。

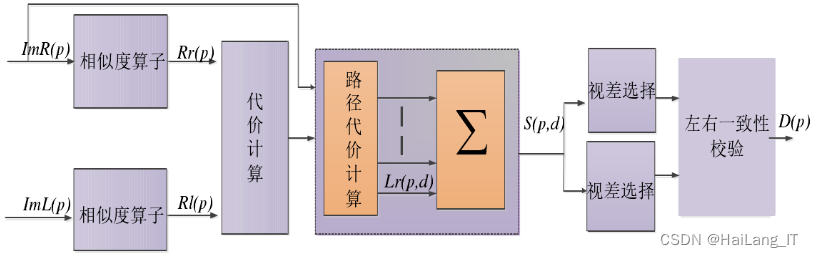
半全局立体匹配算法(SGM)是一种用于双目视觉的立体匹配算法。它通过代价计算、代价聚合、视差优化和深度图生成等步骤,实现了对图像中对应点的匹配和深度信息的计算。SGM算法考虑了像素间的一致性约束,通过路径优化和代价聚合技术,提高了匹配的准确性和鲁棒性。最终,该算法能够生成深度图,揭示场景中物体的距离信息,为三维重构和双目视觉应用提供基础。
二、 数据集
2.1 数据集
由于网络上没有现有的合适的数据集,我们决定自己进行数据收集,通过网络爬取了大量果实图像。我们利用各种果实图像的多样性和真实性,包括不同种类的果实、不同角度的拍摄、不同光照条件下的图像等,构建了一个全新的数据集。通过自制数据集的方式,我们能够获得更具代表性和多样性的果实图像,为果实目标检测与定位的研究提供了更准确、可靠的数据支持。
2.2 数据扩充
为了进一步增加数据集的规模和多样性,我们采用了数据扩充的方法。利用图像处理技术,我们对原始数据集进行了旋转、缩放、平移、镜像等操作,生成了更多的图像样本。此外,我们还通过改变图像的亮度、对比度和色彩等参数,产生了更多具有多样性的图像变体。通过数据扩充,我们成功地增加了数据集的大小,并丰富了其中的样本多样性,提升了模型的泛化能力。
三、实验及结果分析
3.1 实验环境搭建

3.2 模型训练
果实目标检测与定位系统的设计思路可以分为以下几个关键步骤。
- 双目视觉系统需要采集来自两个摄像头的图像数据。这两个摄像头应该被安装在一定的距离上,以模拟人类双眼的视觉效果。通过同时捕捉两个视角的图像,可以获取更多的信息用于果实目标的检测和定位。
- 对于每个摄像头捕获的图像,需要进行相机校准和立体匹配。相机校准是为了确定摄像头的内部和外部参数,以便将图像坐标映射到世界坐标系中。立体匹配则是通过对两个视角的图像进行匹配,找出对应的特征点或像素,从而计算出果实目标在三维空间中的位置。
- 在完成相机校准和立体匹配后,接下来是目标检测阶段。这一阶段的目标是在双目图像中准确地检测出果实目标的位置和边界框。可以利用深度学习的目标检测算法,如Faster-RCNN或YOLO等,对双目图像进行处理,通过卷积神经网络提取特征并进行目标分类和边界框回归。由于双目图像提供了更多的深度信息,可以帮助提高目标检测的准确性。
- 通过融合双目图像和目标检测结果,可以实现果实目标的定位。根据相机校准和立体匹配的结果,可以将检测到的目标在图像中的位置映射到三维空间中。通过计算果实目标在三维空间中的坐标,可以实现对目标的精确定位。
相关代码示例:
# 加载预训练的Faster R-CNN模型
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
model.eval()
# 进行预测
def predict(image):
# 转换图像为Tensor
image_tensor = F.to_tensor(image).unsqueeze(0).to(device)
# 获取预测结果
with torch.no_grad():
prediction = model(image_tensor)
return prediction
# 读取测试图像
image_path = 'test.jpg'
image = Image.open(image_path).convert('RGB')
# 进行预测
prediction = predict(image)
# 处理预测结果
boxes = prediction[0]['boxes'].cpu().numpy()
labels = prediction[0]['labels'].cpu().numpy()
scores = prediction[0]['scores'].cpu().numpy()
海浪学长项目示例:





最后
我是海浪学长,创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!

NVIDIA官方入驻,分享最新的官方资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐


 24
24 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)