
【多模态LLM】以ViT进行视觉表征的多模态模型1(BLIP、BLIP-2、InstructBLIP)
- CLIP和BLIP的区别:- CLIP:通过对比学习联合训练,预测图像和文本之间的匹配关系。即使用双塔结构,分别对图像和文本编码,然后通过计算cos进行图文匹配。- BLIP:包括两个单模态编码器(图像编码器和文本编码器)、一个图像基础的文本编码器和一个图像基础的文本解码器。BLIP通过联合训练三个损失函数:图像-文本对比损失(ITC)、图像-文本匹配损失(ITM)和语言建模损失(LM),以实
note
- CLIP和BLIP2的区别:
- CLIP:通过对比学习联合训练,预测图像和文本之间的匹配关系。即使用双塔结构,分别对图像和文本编码,然后通过计算cos进行图文匹配。
- BLIP2:包括两个单模态编码器(图像编码器和文本编码器)、一个图像基础的文本编码器和一个图像基础的文本解码器。BLIP通过联合训练三个损失函数:图像-文本对比损失(ITC)、图像-文本匹配损失(ITM)和语言建模损失(LM),以实现多任务学习和迁移学习。
- 训练方式的区别:除了对比学习,BLIP还采用了一种高效率利用噪声网络数据的方法(CapFilt),通过生成和过滤模块来迭代优化原模型,以提高对噪声数据的鲁棒性。
- ViT模型:先将图片进行分patch,然后通过线性投影层将patch转为固定长度的图片特征,并且每个patch有对应的位置序号,即patch向量需要和视觉位置向量相加,作为视觉编码器的输入。
- BLIP-2提出两阶段预训练 Q-Former 来弥补模态差距:表示学习阶段和生成学习阶段。
- 设计了三个损失函数:图文对比损失 (ITC image-text contrastive loss)、基于图像的文本生成损失 (ITG image-grounded text generation loss)、图文匹配损失 (ITM image-text matching loss)
- Q-former能够减少视觉token,类似的qwen-vl也使用q-former;但说实话主流的如书生大模型、llava、cogvlm等多模态大模型都是使用MLP,即直接“模态翻译”,减少视觉信息的压缩。如果真的要减少视觉token,也可以使用pooling操作;但是如果在视频、多图、高分辨率上训练其实用q-former问题也挺好。
- 注意:BLIP-2使用q-former时,是固定了视觉编码器和语言模型参数,如果只使用MLP那训练参数是不太够的;但如果类似像cogvlm训练参数还有语言模型的expert视觉专家模块,只使用MLP是合理的。
文章目录
一、多模态综述
《A Survey on Multimodal Large Language Models》
论文链接:https://arxiv.org/pdf/2306.13549.pdf
项目链接:https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models
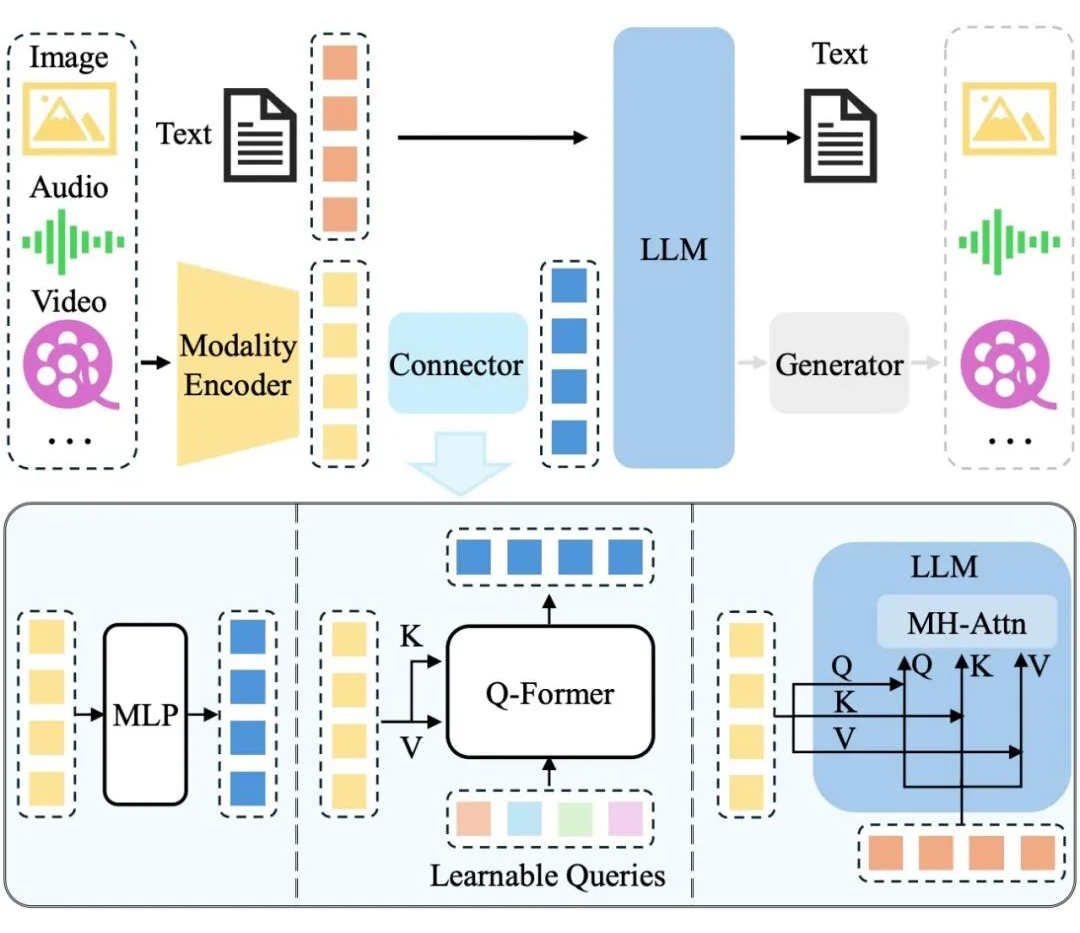
常见的多模态LLM结构:

- 对于多模态输入-文本输出的典型 MLLM,其架构一般包括编码器、连接器以及 LLM。
- 如要支持更多模态的输出(如图片、音频、视频),一般需要额外接入生成器,如上图所示
- 三者的参数量并不等同,以 Qwen-VL [1] 为例,LLM 作为“大脑”参数量为 7.7B,约占总参数量的 80.2%,视觉编码器次之(1.9B,约占 19.7%),而连接器参数量仅有 0.08B。
- 模态编码器:模态编码器负责将原始的信息(如图片)编码成特征,连接器则进一步将特征处理成 LLM 易于理解的形式,即视觉 Token。LLM 则作为“大脑”综合这些信息进行理解和推理,生成回答。
- 视觉编码器:对于视觉编码器而言,增大输入图片的分辨率是提升性能的有效方法。
- 一种方式是直接提升分辨率,这种情况下需要放开视觉编码器进行训练以适应更高的分辨率,如 Qwen-VL [1] 等。
- 另一种方式是将大分辨率图片切分成多个子图,每个子图以低分辨率送入视觉编码器中,这样可以间接提升输入的分辨率,如 Monkey [2] 等工作。
- 连接器:相对前两者来说,连接器的重要性略低。
- 例如,MM1 [7] 通过实验发现,连接器的类型不如视觉 token 数量(决定之后 LLM 可用的视觉信息)及图片的分辨率(决定视觉编码器的输入信息量)重要。
参考:多模态大语言模型全面综述:架构,训练,数据,评估,扩展,应用,挑战,机遇
二、视觉表征与多模态

1. VIT:Transformer视觉表征
- VIT将输入图片平铺成2D的Patch序列(16x16),并通过线性投影层将Patch转化成固定长度的特征向量序列,对应自然语言处理中的词向量输入。
- 同时,每个Patch可以有自己的位置序号,同样通过一个Embedding层对应到位置向量。最终Patch向量序列和视觉位置向量相加作为Transfomer Encoder的模型输入,这点与BERT模型类似。

VIT通过一个可训练的CLS token得到整个图片的表征,并接入全链接层服务于下游的分类任务。当经过大量的数据上预训练,迁移到多个中等或小规模的图像识别基准(ImageNet, CIFAR-100, VTAB 等)时,ViT取得了比CNN系的模型更好的结果,同时在训练时需要的计算资源大大减少。
ViT的思路并不复杂,甚至一般人也不难想到,但是为什么真正有效的工作确没有很快出现?不卖关子,VIT成功的秘诀在于大量的数据做预训练,如果没有这个过程,在开源任务上直接训练,VIT网络仍会逊色于具有更强归纳偏置的CNN网络。因此,在此之后的一大研究方向就是如何更加有效的对VIT结构的网络进行预训练。
2. 怎么分patch
Vision Transformer(ViT)是一种基于Transformer架构的模型,它将自然语言处理(NLP)中的Transformer模型扩展到了计算机视觉任务中。ViT的核心思想是将图像表示为一系列的“patches”,然后使用这些patches作为输入来捕获图像的全局和局部特征。
以下是ViT模型处理图像的主要步骤:
-
图像分割:首先,ViT将输入图像分割成多个较小的、固定大小的矩形区域,这些区域被称为“patches”。例如,一个224x224像素的图像可以被分割成16个8x8像素的patches。
-
线性嵌入:每个patch通过一个线性层(通常是一个卷积层或线性变换)映射到一个高维空间中,这个步骤将图像的每个局部区域转换为一个向量表示。
-
位置编码:由于Transformer架构本身不具备捕捉序列中元素顺序的能力,因此ViT为每个patch添加了一个位置编码(Positional Encoding),以便模型能够理解每个patch在图像中的位置信息。
-
序列化:经过嵌入和编码后,所有的patches被串联成一个序列,这个序列随后被输入到Transformer模型中。
-
多头自注意力机制:Transformer模型使用多头自注意力机制来处理序列数据。在ViT中,这意味着模型可以在处理图像时同时考虑全局和局部的上下文信息。
-
层次化表示:ViT通常采用多个Transformer层来逐步构建图像的层次化表示,每一层都在前一层的基础上进一步抽象和整合特征。
-
分类器:在Transformer层之后,ViT通常使用一个或多个全连接层(或称为线性层)来对图像进行分类。
理解ViT中的“分patch”概念,可以将其想象为将图像分解为多个小块,每个小块都是图像的一个局部视图。这种方法允许模型学习到图像的局部特征,并通过Transformer的自注意力机制整合这些局部特征以形成对整个图像的理解。这种处理方式使得ViT能够有效地捕获图像的全局结构和细节信息,从而在多种视觉任务中表现出色。
三、以VIT为基础的多模态对齐与预训练

1. CLIP视觉预训模型
CLIP视觉预训模型:用于生成图像-文本对齐向量表示
CLIP模型是OpenAI 2021发布的多模态对齐方法。CLIP模型采用文本作为监督信号,属于多模态学习的领域。该模型将文本和图像映射到一个共同的隐空间,以实现它们在语义上的对齐。
使用400million的数据文本对,跟webText差不多,称为WIT,即WebImageText,<图像,文本描述>样本进行训练,CLIP通过一个线性层将两个模态的向量映射到一个空间。
文字编码器是transformer,编码器模型使用了ViT等
(1)训练方式
CLIP的核心思路:
通过对比学习的方法进行视觉和自然语言表征的对齐。如下图(1),CLIP首先分别对文本和图像进行特征抽取,文本的Encoder为预训练BERT,视觉侧的Encoder可以使用传统的CNN模型,也可是VIT系列模型。得到图文表征向量后,在对特征进行标准化(Normalize)后计算Batch内图文Pair对之间的余弦距离,通过Triple Loss或InfoNCELoss等目标函数拉近正样本对之间的距离,同时使负样本对的距离拉远。

经过大量的图文Pair对进行预训练后,我们可以得到在同一表征空间下的文本Encoder和图像Encoder。下游应用通常也是两种方式,一是在下游任务上对模型进行微调,适应定制的图文匹配任务,或者仅使用文本或图像Encoder做单模态任务;另一种使用方式是直接使用预训练的图文表征Zero-Shot方式完成下游任务。
CLIP进行Zero-Shot的一种使用方式如图14(2)和(3),对于一个图像分类任务,可以首先将所有的候选类别分别填充“A photo of a {object}”的模板,其中object为候选类别,对于一张待预测类别的图像,通过图像Encoder的到视觉表征后,与所有类别的模板文本Encoder表征进行相似度计算,最后选择相似度最高的类别即可作为预测结果。
CLIP凭借其简洁的架构和出众的效果,被后来很多工作引用,并使用CLIP预训练的Backbone作为视觉表征模块的初始化参数。
论文:
《Learning Transferable Visual Models From Natural Language Supervision》,https://github.com/openai/CLIP.git,https://github.com/mlfoundations/open_clip
《Reproducible scaling laws for contrastive language-image learning》,https://arxiv.org/abs/2212.07143
(2)模型评估
zero-shot能力:

few-shot能力:

(3)训练超参数

2. BLIP模型
统一图文理解和生成任务

特别注意BLIP使用boostrap方法进行过滤训练数据:
- bootstrap数据:先使用含有噪声的网络数据训练一遍 BLIP,再在 COCO 数据集上进行微调以训练 Captioner 和 Filter,然后使用 Filter 从原始网络文本和合成文本中删除嘈杂的字幕,得到干净的数据。最后再使用干净的数据训练一遍得到高性能的 BLIP。
- captioner:对网络图像生成caption。image-grounded text decoder,进行text的next token prediction
- filter:image-grounded text encoder,学习目标是ITC和ITM,判断text和图片是否match,去除网络文本和生成文本中的噪音文本。
- Bootstrap过程,Captioner生成的图文对与Filter过滤后的网络图文,再加上人工标注的图文对结合起来,形成一个新的数据集,重新预训练一个新模型。


3. BLIP-2模型
《BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models》:https://arxiv.org/pdf/2301.12597.pdf
项目代码:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
第一次提出q-former。
(1)模型结构

- Image Encoder:负责从输入图片中提取视觉特征。
- Large Language Model:负责文本生成。
- Q-Former:负责弥合视觉和语言两种模态的差距,由Image Transformer和Text Transformer两个子模块构成,它们共享相同自注意力层,如下图所示。
- Image Transformer通过与图像编码器进行交互提取视觉特征,它的输入是可学习的 Query,这些Query通过自注意力层相互交互,并通过交叉注意力层与冻结的图像特征交互,还可以通过共享的自注意力层与文本进行交互。
- Text Transformer作为文本编码器和解码器,它的自注意力层与Image Transformer共享,根据预训练任务,应用不同的自注意力掩码来控制Query和文本的交互方式(见下面的三种mask机制)。
第一阶段

为了减少计算成本并避免灾难性遗忘的问题,BLIP-2 在预训练时冻结预训练图像模型和语言模型,但是,简单地冻结预训练模型参数会导致视觉特征和文本特征难以对齐,为此BLIP-2提出两阶段预训练 Q-Former 来弥补模态差距:表示学习阶段和生成学习阶段。
上图是第一阶段,图像编码器被冻结,Q-former 通过三个损失函数进行训练(见下面三个),将文本输入[CLS]对应transformer的输出记为
E
T
∈
R
N
×
D
E_T \in \mathbb{R}^{N \times D}
ET∈RN×D 其中
N
N
N 为batch size:
- 图文对比损失 (ITC image-text contrastive loss):每个查询的输出都与文本输出的 CLS 词元计算成对相似度,并从中选择相似度最高的一个最终计算对比损失。在该损失函数下,查询嵌入和文本不会 “看到” 彼此。
# 对比损失 ITC
# output (N, K, N)
sim_matrix = matmul(E_V, E_T, transposed_Y=True)
# output (N, N), maxpool for a best text-vision matching
sim_matrix = reduce_max(sim_matrix, axis=1)
dig_label = tensor(list(range(0, batch_size))).reshape(batch_size, 1)
itc_loss = cross_entropy_with_softmax(sim_matrix, dig_label)
- 基于图像的文本生成损失 (ITG image-grounded text generation loss):查询内部可以相互计算注意力但不计算文本词元对查询的注意力,同时文本内部的自注意力使用因果掩码且需计算所有查询对文本的注意力。
# output (N, S, 1)
logits = model(Q, T, mask)
itg_loss = cross_entropy_with_softmax(logits, gt_char_label)
- 图文匹配损失 (ITM image-text matching loss):查询和文本可以看到彼此,最终获得一个几率 (logit) 用以表示文字与图像是否匹配。这里,使用难负例挖掘技术 (hard negative mining) 来生成负样本。
- 其中的T_neg为负样本文本,可以参考ALBEF [6] 的工作进行难负样本采样
# 匹配损失 ITM
# positive sample score, output (N, 1)
pos_score = model(Q, T)
# negative sample score, output (N, 1), T_neg could be the hard negative sampled at ITC stage
neg_score = model(Q, T_neg)
itm_loss = mse(pos_score, 1) + mse(neg_score, 0)
Learned Query 的引入在这里至关重要。可以看到这些 Query 通过 Cross-Attention 与图像的特征交互,通过 Self-Attention 与文本的特征交互。这样做的好处有两个:
- 这些 Query 是基于两种模态信息得到的;
- 无论多大的视觉 Backbone,最后都是 Query 长度的特征输出,大大降低了计算量。
下图是每个目标的自注意力屏蔽策略,以控制查询-文本交互:

第二阶段
第二阶段: BLIP-2 的第二阶段视觉到语言生成预训练,从冻结的大型语言模型(LLM)中引导。
(顶部)引导基于解码器的 LLM(例如 OPT)。
(底部)引导基于编码器-解码器的 LLM(例如 FlanT5)。全连接层从 Q-Former 的输出维度调整到所选 LLM 的输入维度。

(2)训练细节
- 训练数据方面:包含常见的 COCO,VG,SBU,CC3M,CC12M 以及 115M的LAION400M中的图片。采用了BLIP中的CapFilt方法来 Bootstrapping 训练数据。
- 视觉编码模型:选择了 CLIP 的 ViT-L/14 和 ViT-G/14,特别的是,作者采用倒数第二层的特征作为输出。
- 训练时,CV 模型和 LLM 都是冻结的状态,并且参数都转为了 FP16。这使得模型的计算量大幅度降低。主要训练的基于 BERT-base 初始化的 Q-Former 只有 188M 的参数量。
关于BLIP2的微调参考:
基于LoRA微调多模态大模型
Blip2 视觉-语言 预训练大模型
4. InstructBLIP模型
(1)模型架构

InstructBLIP 的模型架构。Q-Former 从冻结的图像编码器的输出嵌入中提取了指示感知的视觉特征,并将这些视觉特征作为软提示输入馈送给冻结的 LLM。我们使用语言建模损失对模型进行指令调整,以生成响应。
视觉编码器提取输入图片的特征,并喂入 Q-Former 中。此外,Q-Former 的输入还包括可学习的 Queries(BLIP-2 的做法)和 Instruction。Q-Former 的内部结构黄色部分所示,其中可学习的 Queries 通过 Self-Attention 和 Instruction 交互,可学习的 Queries 通过 Cross-Attention 和输入图片的特征交互,鼓励提取与任务相关的图像特征。
Q-Former 的输出通过一个 FC 层送入 LLM,Q-Former 的预训练过程遵循 BLIP-2 的两步:1)不用 LLM,固定视觉编码器的参数预训练 Q-Former 的参数,训练目标是视觉语言建模。2)固定 LLM 的参数,训练 Q-Former 的参数,训练目标是文本生成。
(2)训练数据
指令微调数据的prompt:

其他模型:
(2)VILT
(3)ALBEF与BLIP
(4)VL-BEIT、VLMO与BEIT-3
备注:大模型的训练少不了算力资源,博主和一些平台有合作~
高性价比4090算力租用,注册就送20元代金券,更有内容激励活动,点击。
GPU云服务器租用,P40、4090、V100S多种显卡可选,点击。
Reference
[1] 多模态超详细解读 (六):BLIP:统一理解和生成的自举多模态模型
[2] 调研120+模型!腾讯AI Lab联合京都大学发布多模态大语言模型最新综述
[3] 多模态RAG应用
[4] 一文看完多模态:从视觉表征到多模态大模型
[5] 超越 GPT-4V 和 Gemini Pro!HyperGAI 发布最新多模态大模型 HPT,已开源
[6] “闭门造车”之多模态模型方案浅谈
[7] 一文看完多模态:从视觉表征到多模态大模型
[8] 万字长文总结多模态大模型最新进展(Modality Bridging篇)
[9] 某乎:一文看完多模态:从视觉表征到多模态大模型
[10] “闭门造车”之多模态模型方案浅谈
[11] 图生文多模态大模型开源项目回顾.刘NLP
[12] BLIP2——采用Q-Former融合视觉语义与LLM能力的方法
[13] 多模态大语言模型(MLLM)为什么最近的工作中用BLIP2中Q-Former结构的变少了?
[14] 【BLIP/BLIP2/InstructBLIP】一篇文章快速了解BLIP系列(附代码讲解说明)
[15] LLava: 指令跟随的多模态大语言模型
[16] 浅析多模态大模型的前世今生.tx技术工程
[17] 一文读懂BLIP和BLIP-2多模态预训练

NVIDIA官方入驻,分享最新的官方资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐


 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)