
LimSim++: 一个自动驾驶中部署多模态LLMs的闭环平台
24年2月论文“LimSim++: A Closed-Loop Platform for Deploying Multimodal LLMs in Autonomous Driving“, 来自上海AI实验室和浙江大学。
24年2月论文“LimSim++: A Closed-Loop Platform for Deploying Multimodal LLMs in Autonomous Driving“, 来自上海AI实验室和浙江大学。
多模态大语言模型(M)LLM的出现为人工智能开辟了新的途径,特别是提供增强的理解和推理能力,为自动驾驶开辟了新途径。本文介绍LimSim++,LimSim的一个扩展版本,旨在将(M)LLM应用于自动驾驶。LimSim++克服了现有模拟平台的局限性,解决了对长期闭环基础设施的需求,支持自动驾驶中的持续学习和改进的泛化能力。该平台提供了持续时间更长的多场景模拟,为LLM驱动的车辆提供了关键信息。用户可以参与提示工程、模型评估和框架增强,使LimSim++成为研究和实践的通用工具。本文还介绍了一个基线(M)LLM驱动的框架,在不同场景下的定量实验进行系统验证。
如图是LimSim++的组件示意图:LimSim++提供了一个包含道路拓扑、动态交通流、导航、交通控制和其他基本信息的闭环系统。提示是(M)LLM支持的智体系统基础,它包含通过图像或文本描述呈现的实时场景信息。LLM支持的智体系统具有信息处理、工具使用、策略制定和自我评估等功能。
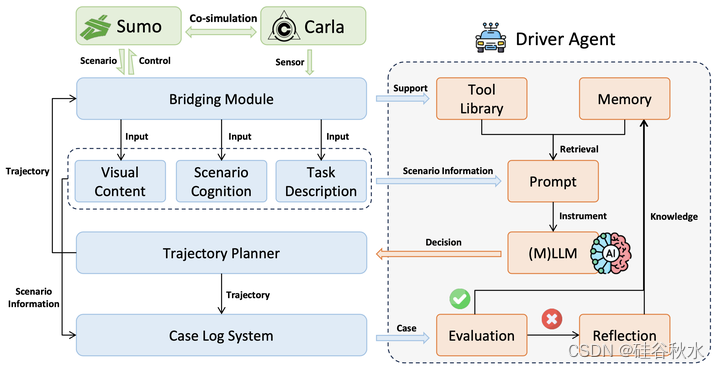
如图给出LimSim++的框架。(1) 信息集成:SUMO提供的场景和CARLA的可视化内容通过桥接模块集成到LimSim++中。(2) 提示引擎:构建多模态提示支持(M)LLM来理解场景和任务,包括VLM和LLM。(3) 持续学习:驾驶员智体在(M)LLM的驱动下,做出行为决策,并通过评估、反思、记忆和工具库等机制不断增强决策能力。
LimSim++提供各种类型和模态的提示输入,满足不同(M)LLM完成驾驶任务的需求。在每个决策框架中,LimSim++提取自车周围的道路网络和车辆信息。然后,场景描述和任务描述的这些信息被打包并以自然语言传递给驾驶员智体。LimSim++根据nuScenes的摄像头设置为自车配备了六个摄像头。这些摄像头能够拍摄自车的全景图像。LimSim++的场景描述是模块化的,提供实时状态、导航信息和任务描述。用户可以根据驾驶员智体的需求自由组合场景信息,并将其打包成合适的提示。除了LimSim++提供的信息外,用户还可以定义他们的工具库,允许(M)LLM通过调用工具获得更多自定义信息,并帮助驾驶员智体做出决策。
LimSim++作为一个闭环仿真评估平台,支持依赖(M)LLM的推理和决策过程,可以通过零样本或少样本驾驶方法完成。零样本驾驶涉及直接根据获得的提示做出判断;然而,(M)LLM的幻觉问题可能导致决策失败。对于非专业(M)LLM,少样本学习被证明是至关重要的,使这些模型能够暴露于有限的一组实例来获得驾驶任务的可能解决方案,尤其是当不同的场景需要不同的反应时。毫无疑问,利用预训练的基础模型进行自动驾驶的前景是非常有希望的。
LimSim++可以处理来自决策结果的各种控制信号。如果驾驶员智体仅提供行为基元,如加速、减速、左转、右转等,则LimSim++为这些基元提供控制接口,有助于将驾驶员智体的决策转换为车辆轨迹。此外,Lim-Sim++支持直接利用驾驶员智体输出的轨迹来控制车辆运动,尽管对(M)LLM的性能要求有所提高。
评估模块基于对车辆轨迹的分析来量化和评估驾驶员智体做出的车辆行为决策。这一过程是持续学习框架中的一个重要组成部分。评估周期对应于两个连续决策之间的时间间隔,由(M)个LLM的决策频率确定。驾驶性能综合考虑了路线补全R和驾驶分数S。路线完成R表示已补全的路线长度与总长度的比率,即
其中Lcompleted表示驾驶员智体补全的路线长度,Ltotal表示预设路线的总长度。驾驶分数S包括各种因素,如
其中,三个惩罚因子项,α、β和γ,分别表示碰撞、信号违规和速度违规,λ1、λ2和λ3分别表示三种类型的惩罚行为在整个轨迹中的发生次数,k1、k2和k3是用于每个决策的轨迹质量评估加权系数,包括定义的乘坐舒适性(表示为rc)、驾驶效率(表示为re)和驾驶安全(表示为rs)。
LimSim++引入了一种用于持续学习的反思和记忆机制,旨在提高驾驶员智体的性能。在补全一段路径后,评估者评估驾驶决策。LimSim++利用这些评估结果进行持续学习,因为它们与驾驶员智体的决策性能密切相关。得分高的决策会直接集成到记忆模块中。对于得分较低的决策,LimSim++通常在人类专家的帮助下,提示(M)LLM进行自我反思或纠错,提高决策的准确性。随后,细化的推理结果被集成到记忆模块中。
具体而言,在自我反思过程中,驾驶员智体根据评估者的得分确定需要改进的领域,并调整这些方面以优化推理过程。在驾驶员智体缺乏反思能力的情况下,采用专家纠错来确保正确的推理。当驾驶员智体遇到类似场景时,细化的推理结果将作为少样本实例来帮助(M)LLM在随后的决策过程中进行决策。LimSim++采用矢量数据库来存储和检索类似场景[8]。
如图所示:关键场景的提示和驾驶决策,其中绿色突出显示GPT-4的正确答案。
如下两个图所示:分别是在交叉路口和换道场景中如何通过记忆增强,其中绿色突出显示正确答案,红色突出显示错误答案,黄色突出显示从记忆模块中提取的类似经验,其中包括过去的场景描述和正确的推理过程。


分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐



 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)