
翻译:SplatAD:用于自动驾驶的实时激光雷达和相机渲染的三维高斯点阵法
“所谓坚持,就是觉得还有希望!GeorgHess†,1,2CarlLindstr¨om†,1,2MaryamFatemi1Petersson1,2LennartSvensson21Zenseact2查尔姆斯理工大学名字姓氏图1.SplatAD是首个能够使用3D高斯点阵实现逼真的相机和激光雷达渲染的方法。与以往的方法相比,要么速度快,要么多模态,而SplatAD能够实现实时、高质量的相机和激光雷达渲
个人主页:云纳星辰怀自在
座右铭:“所谓坚持,就是觉得还有希望!”
SplatAD:用于自动驾驶的实时激光雷达和相机渲染的三维高斯点阵法
Georg Hess†,1,2 Carl Lindstr¨om †,1,2 Maryam Fatemi1 Christoffer Petersson1,2 Lennart Svensson2
1 Zenseact 2查尔姆斯理工大学
{名字.姓氏}@{zenseact.com, chalmers.se}

图 1. SplatAD 是首个能够使用 3D 高斯点阵实现逼真的相机和激光雷达渲染的方法。与以往的方法相比,要么速度快,要么多模态,而 SplatAD 能够实现实时、高质量的相机和激光雷达渲染。此外,SplatAD 能够在几分钟内达到具有竞争力的性能,例如图像的峰值信噪比(PSNR)和点云的切比雪夫距离。
Abstract
确保自动驾驶汽车等自主机器人的安全性需要在各种驾驶场景中进行大量测试。模拟是进行此类测试的一种经济高效且可扩展的方式。神经渲染方法因其能够以数据驱动的方式从收集的日志中构建模拟环境而受到欢迎。然而,现有的用于相机和激光雷达数据传感器真实感渲染的神经辐射场(NeRF)方法存在渲染速度慢的问题,这限制了其在大规模测试中的应用。虽然 3D 高斯点阵(3DGS)能够实现实时渲染,但目前的方法仅限于相机数据,无法渲染自动驾驶中必不可少的激光雷达数据。为了解决这些局限性,我们提出了 SplatAD,这是首个基于 3DGS 的方法,能够对动态场景进行相机和激光雷达数据的真实感实时渲染。SplatAD 使用专门设计的算法准确建模关键的传感器特定现象,如滚动快门效应、激光雷达强度和激光雷达光束丢失,从而优化渲染效率。在三个自动驾驶数据集上的评估表明,SplatAD 实现了最先进的渲染质量,对于神经隐式场景合成(NVS)的峰值信噪比(PSNR)提高了多达 2 分,对于重建提高了多达 3 分,同时渲染速度比基于 NeRF 的方法快了一个数量级。请访问我们的项目页面。
†These authors contributed equally to this work.
1. Introduction
大规模测试对于确保自动驾驶汽车(SDV)等自主机器人在实际部署前的安全性至关重要。从收集的日志中生成数字孪生的数据驱动方法为构建多样化、逼真的模拟环境以进行测试提供了一种可扩展的方式。与成本高昂、耗时且受物理限制的现实世界测试不同,模拟能够快速、低成本地探索多种场景,有助于优化 SDV 的安全性、舒适性和效率。受此启发,基于神经辐射场(NeRFs)[25, 35, 36, 45] 和 3D 高斯点阵(3DGS)[14, 43, 51] 的众多方法应运而生。
近期基于 NeRF 的方法 [35, 45] 能够为相机和激光雷达提供高保真的传感器模拟,与流行的自动驾驶(AD)数据集 [1, 5, 38] 中最常见的传感器配置相匹配。然而,基于 NeRF 的方法渲染速度慢,这使得它们在大规模测试中成本高昂且难以使用。3DGS 为 NeRF 提供了一个颇具吸引力的替代方案,其加速渲染在实现相当图像逼真度的同时,将推理速度提高了几个数量级。不过,针对自动驾驶场景的基于 3DGS 的方法 [7, 43, 51] 继承了只能渲染相机数据的局限性,忽略了激光雷达这一模态。激光雷达能够直接感知三维环境,是现代自动驾驶系统中的强大工具,因此也是需要模拟的重要模态。
在本文中,我们旨在利用 3D 高斯点阵法实现对相机和激光雷达数据的高效、可微且逼真的渲染。将 3DGS 应用于激光雷达传感器面临独特的挑战,这源于其自身的特性。首先,与相机不同,激光雷达记录的是稀疏、非线性的点云,其间存在大量未返回光线造成的空隙。其次,大多数激光雷达能够捕捉到场景的 360°全景,而现有方法通常将数据投影到多个深度图像中[7],这是一种低效的方法,忽略了激光雷达数据的稀疏结构。最后,激光雷达存在滚动快门效应,每次扫描可能需要长达 100 毫秒,期间自动驾驶车辆可能移动数米,这违背了 3DGS 的单源假设。为克服这些挑战,我们引入了 SplatAD,这是一种新颖的视图合成方法,能够统一相机和激光雷达的渲染,并专为大规模动态交通场景的实时渲染而设计。我们的方法用每个高斯分布的可学习特征取代球谐函数,以联合建模传感器特有的现象——从激光雷达的点云丢失和强度变化到相机特有的外观变化。通过引入专门用于在球坐标系中渲染激光雷达的定制光栅化算法,我们实现了更高的效率和更逼真的效果。此外,我们还展示了针对两种传感器模式的滚动快门效应的有效建模方法。我们在三个流行的汽车数据集上验证了我们方法的有效性和通用性,在所有数据集上均取得了最先进的成果。总之,我们的贡献如下:
我们提出了首个利用三维高斯分布实现高效激光雷达渲染的方法,引入了自定义的 CUDA 加速算法,用于将球坐标系下的稀疏点云进行光栅化。
我们推出了首个 3DGS 方法,能够从统一的表示形式渲染相机和激光雷达,从而加快汽车应用中新型视图合成的扩展速度。
我们提出了使用三维高斯分布进行逼真传感器建模的有效技术,能够精确处理滚动快门、激光雷达强度、光线丢失以及传感器外观变化等问题。
通过在三个热门汽车数据集上进行广泛评估,我们在所有基准测试中均取得了最先进的成果,这验证了我们方法的有效性和通用性。
2. 相关工作
用于汽车数据的神经辐射场(NeRF):自神经辐射场(NeRF)问世以来,神经表示已成为三维重建和新视角合成的核心技术[2-4, 25]。许多研究将基于 NeRF 的方法应用于汽车数据[35, 36, 44, 45],从而能够在大型动态场景中实现传感器真实的新型视角渲染
。近期的进展已足以满足下游应用对真实感的要求[22, 23]。早期的方法要么专注于相机[10, 19, 29, 42],要么专注于激光雷达[13, 39, 49],而较新的方法则致力于同时处理这两种传感器。UniSim [45] 展示了基于 PandaSet [41] 数据的前视相机和 360◦lidar 的逼真渲染效果。该方法采用哈希网格表示[27],为天空、静态背景和动态对象分别设置特征,并从体渲染特征中解码颜色和激光雷达强度。NeuRAD [35] 提出了一种简化的网络架构和改进的传感器建模,实现了全 360°相机和激光雷达套件的最先进成果。尽管如此,基于 NeRF 的方法渲染速度慢的问题使得其扩展成本高昂且颇具挑战性。SplatAD 旨在通过使用基于光栅化的 CUDA 加速算法来渲染相机和激光雷达数据,从而克服这一限制,同时受 Neu-RAD 的启发,强调对重要传感器特性的建模以提高逼真度。
用于汽车数据的 3DGS:3DGS [14] 采用显式表示与光栅化技术以及定制的硬件加速算法相结合,实现了实时渲染。此外,3DGS 已被证明能够生成逼真的场景重建,其渲染质量接近近期基于 NeRF 的方法。因此,已有若干研究将 3DGS 应用于汽车数据的相机渲染 [7, 15, 43, 50, 51]。周期振动高斯(PVG)[6] 通过学习所有高斯的三维流,将 3DGS 应用于动态场景。然而,PVG 缺乏显式的角色表示,这限制了该方法的可控性,从而影响其在模拟中的适用性。与 Unisim 和 NeuRAD 类似,街道高斯 [43] 利用 3D 边界框将场景分解为静态背景和刚性动态角色。作者进一步扩展了 3DGS,通过添加傅里叶系数来捕捉动态角色随时间变化的特征。此外,为了处理天空区域,他们的方法使用语义掩码和视图相关的立方体映射。OmniRe [7] 通过添加非刚性节点来增强场景图的组合,从而更好地模拟行人和骑自行车的人。然而,这需要进行预处理来跟踪和对齐人体姿态[12],以初始化 SMPL[24] 姿态参数。
PVG、Street Gaussians 和 OmniRe 都使用激光雷达点进行初始化和深度监督。然而,它们的点云是通过将激光雷达点投影到深度图像中生成的,这种方法效率低下,也不适用于新视角。因此,这些方法都无法对激光雷达的重要特性(如强度变化、光束丢失和滚动快门)进行建模。相比之下,我们的方法支持从 3D 高斯分布中高效渲染相机和激光雷达的新视角图像,并对这两种模态的重要传感器特性进行建模。
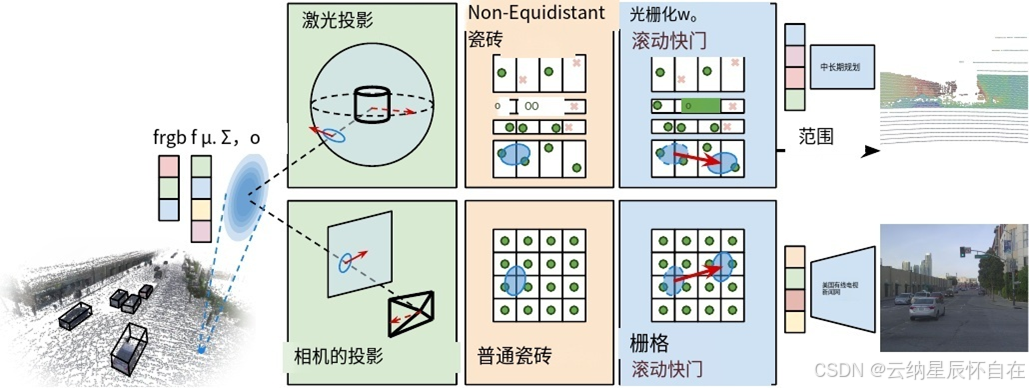
图 2. 我们所提出方法的概述。给定静态和动态 3D 高斯分布的组合,SplatAD 能够对激光雷达和相机数据进行可微分渲染。我们提出的激光雷达渲染在高层次上与图像渲染相匹配,但对每个组件进行了修改,以准确地模拟传感器特性。我们的方法将带有相关特征向量的 3D 高斯分布投影到相应的传感器模态(相机和激光雷达)上,并采用特定于传感器的分块来匹配它们的不同特性。在光栅化过程中,对投影的高斯分布进行校正,以消除由传感器移动以及可能的自身速度所引起的滚动快门效应。最后,将光栅化后的特征解码为相应的图像和激光雷达点云表示。
3. Method
我们的目标是从收集到的车辆日志中学习场景表示,从而能够生成逼真的相机和激光雷达数据,并且能够改变自身车辆和其他车辆的位置。为了有效扩展,渲染过程必须快速,因为更快的推理速度能增强其在实际应用中的实用性。接下来,我们将描述场景表示(第 3.1 节)、渲染算法(第 3.2 节和第 3.3 节)以及实现和优化策略(第 3.4 节),图 2 给出了概述。
3.1. 场景表示
我们的场景表示基于 3DGS [14],但针对 AD 场景的特殊性进行了关键修改,并且能够从同一表示中实现相机和激光雷达的渲染。与 3DGS 类似,每个场景都由一组具有可学习占用率 o ∈(0, 1)、均值 µ∈R3 和协方差矩阵 Σ∈R3×3 的半透明 3D 高斯分布来表示,而协方差矩阵 Σ∈R3×3 又由尺度 S ∈R3 和四元数 q ∈R4 参数化。我们不再使用球谐函数 [14],而是为每个高斯分布分配一个可学习的基础颜色 f rgb ∈R3 和特征向量 f ∈RDf ,其中 f 用于视图相关效果和激光雷达属性。最后,我们的表示为每个传感器包含一个可学习的嵌入,以建模其特定的外观特征。
为了处理动态变化,我们遵循常用的场景图分解方法[29, 35, 43, 51],将场景划分为静态背景和一组动态角色。每个动态角色都由一个三维
包围盒和一系列 SE(3) 姿态来描述,这些姿态要么来自现成的对象检测器和跟踪器,要么来自标注。每个高斯分布都有一个不可学习的 ID,用于表明其是属于静态世界,还是属于某个特定角色。对于分配给角色的高斯分布,其均值和协方差是在对应轴对齐包围盒的局部坐标系中表示的。要在给定时间 t 组合场景,分配给包围盒的高斯分布会根据其角色的姿态转换到世界坐标系。由于角色姿态估计可能存在不准确,我们用可学习的偏移量对其进行调整。此外,每个角色都有一个根据姿态差值初始化的速度和一个可学习的速度偏移量。
3.2. 相机渲染
对于给定的拍摄相机,我们在对应的拍摄时间 t 组合高斯分布集,并使用 3DGS [14] 中的高效基于瓦片的渲染方法生成图像 I。虽然我们保留了 3DGS 的主要步骤——投影、视锥体剔除、瓦片分配、深度排序和基于瓦片的光栅化,但我们引入了关键的改进以更好地模拟 AD 数据的独特特性。
投影、平铺和排序:每个均值和协方差都从世界坐标转换为相机坐标,得到 µC 和 ΣC 。然后,均值通过透视投影转换到图像空间 µI ∈R2 ,而协方差则使用投影的雅可比矩阵的前两行进行转换,即 ΣI = JI ΣC (JI )T ∈R2×2 。对于超出视锥体的高斯分布,3DGS 进行剔除,为提高效率,3DGS 对高斯分布的范围进行了近似处理。
使用一个正方形的轴对齐包围盒(AABB),该包围盒覆盖其 99% 的置信水平。此外,3DGS 将图像划分为 16×16 像素的瓦片,并将高斯分布分配给它们所相交的所有瓦片,必要时进行复制。这样,在光栅化过程中,每个像素只需处理所有高斯分布的一个子集。最后,根据高斯分布均值的 z 深度对它们进行排序 µC 。
卷帘快门:许多相机使用卷帘快门,图像的捕捉并非瞬间完成,而是逐行进行,这使得相机在曝光期间可以移动。先前的研究[35]强调了对卷帘快门效应建模的重要性,因为在 AD 数据中存在很高的传感器速度,其基于光线追踪的方法可以通过移动每条光线的起点轻松解决这一问题。对于 3DGS,等效的方法需要将所有 3D 高斯分布投影到曝光期间遇到的所有相机姿态上,因为高斯分布相对于相机的位置会随时间变化。由于这会带来高昂的计算成本,我们借鉴了[31]的方法,转而在 2D 图像空间中直接近似这些效应。具体来说,将每个高斯分布相对于相机的速度投影到图像空间,并在光栅化过程中根据像素的捕获时间调整其像素均值 µI。然而,[31]仅考虑了静态场景,因此我们调整了公式以同时考虑动态情况。
对于每个高斯分布,其像素速度近似为
![]()
其中 ωC 和 vC 分别表示以相机坐标系表示的相机的角速度和线速度,以及
![]()
表示由其关联角色的角速度 ωdyn 和线速度 vdyn(在角色坐标系中表示)所引起的高斯分布的速度,而 µact 表示角色坐标系中的高斯分布均值。要将速度从角色坐标系转换到相机坐标系,T act→C 是角色到世界和世界到相机变换的组合。对于属于静态背景的高斯分布,vdyn 为零。更多细节请参见附录 D。
在剔除高斯分布以及检查高斯分布与瓦片之间的相交情况时,我们通过增加近似高斯分布的范围来考虑像素速度。我们使用覆盖三倍标准差的矩形包围盒,而不是 3DGS 和 [31] 中使用的正方形包围盒,并向其范围增加 trs | ·trs/2 。这里,trs 表示滚动快门持续时间,即最后一行像素与第一行像素之间的时间差。范围的增加对应于在滚动快门时间内高斯分布均值所覆盖的区域,假设传感器时间戳处于曝光的中间。由于实际情况并非总是如此,我们进一步引入了一个可学习的时间偏移量,用于描述传感器时间戳与曝光中间时刻
之间的差异。与 [14, 31] 相比,使用矩形包围盒减少了不必要的相交情况,特别是对于窄高斯分布和轴对齐速度的高斯分布,后者在侧视相机中经常出现。
光栅化:3DGS 通过为每个瓦片启动一个线程块,并将每个线程分配给瓦片内的一个像素来并行光栅化像素。对于每个像素,其坐标 p = [pu, pv]T 从块和线程索引中推断得出。由此,我们找到该像素的捕获时间与图像中间行之间的时间差为
![]()
要对一个像素进行光栅化,我们需要对当前图块中深度排序的高斯分布的 RGB 值 firgb 和特征 fi 进行α混合。
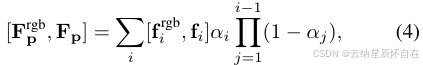
其中α计算为
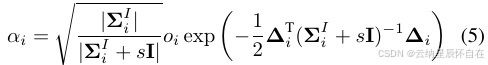
和
![]()
与 [31] 中的做法一致,我们使用由滚动快门补偿后的均值来计算像素与高斯分布之间的距离 ∆i ,从而将高斯分布有效地移动到图像中的正确位置。与 3DGS 相比,在公式(5)中,我们采用了 [47] 中的 3DGS+EWA [52] 表达式,其中 s = 0.3 。
视相关效果通过一个小卷积神经网络进行建模;给定特征图 F ∈RH×W×Df 、对应的光线方向 d ∈RH×W×3 以及特定于相机的学习嵌入 e ,它预测应用于 Frgb 的逐像素仿射映射 M ∈RH×W×3 和 b ∈RH×W×3 。
![]()
![]()
我们发现,使用小型卷积神经网络(CNN)而非多层感知机(MLP)对于高效地进行纹理建模至关重要,例如对于高频路面纹理。此外,受[30]的启发,特定于相机的学习嵌入能够对曝光差异进行建模。
3.3. 激光雷达渲染
激光雷达传感器能让自动驾驶汽车测量一组离散点的距离和反射率(强度)。它们通过发射激光脉冲并测量飞行时间来确定距离,同时测量返回功率来确定反射率。大多数自动驾驶数据集都使用激光雷达。
我们使用垂直排列的多个激光二极管(16 - 128 个),通过旋转二极管阵列来捕获数据,通常一次扫描需要 100 毫秒。因此,我们专注于这种类型的激光雷达。不过,我们注意到,通过相应地修改投影,用我们的方法对其他类型的激光雷达(如固态激光雷达[21])进行建模也很容易实现。我们提出的激光雷达渲染遵循图像渲染的高级步骤,但对每个组件进行了修改,以准确地模拟激光雷达的特性。
投影:对于在捕获时间 t 由激光雷达获取的点云和高斯分布,我们将每个均值和协方差从世界坐标系转换为激光雷达坐标系,得到 µL = ?x, y, z?T 和 ΣL。原始激光雷达数据通常以球坐标形式捕获,即方位角 ϕ、仰角 ω 和距离 r。因此,我们将高斯分布的均值从激光雷达坐标系转换为球坐标系。
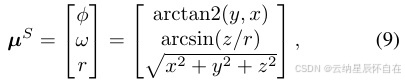
并利用变换的雅可比矩阵(式 9)将协方差 ΣL 转换为 ΣS = JS ΣL (JS)T ,其中
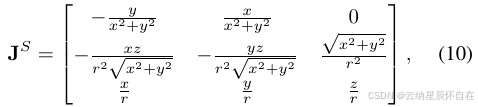
并且 µS 和 ΣS 分别表示球坐标系中的均值和协方差。
与相机的情况相同,我们通过在传感器空间中近似其影响来考虑滚动快门效应。
![]()
请注意,与公式(1)中的 vI 不同, vS 是三维的,因为我们需要它来进行精确的范围栅格化。最后,我们使用 vS trs/2 的前两个元素来增加近似高斯分布大小的矩形包围盒的范围,并剔除超出激光雷达视场的高斯分布。
瓦片划分与排序:3DGS 效率的核心在于其基于瓦片的光栅化技术。尽管激光雷达通常具有固定的方位角分辨率,但许多激光雷达在感兴趣区域使用非等距的二极管间距以获得更高的分辨率,从而导致非线性的高度分辨率,如图 1 所示。为此,我们设计了垂直方向上具有固定数量二极管、水平方向上具有固定方位角分辨率的瓦片。在水平方向上,通过将方位角坐标除以公共瓦片方位角大小,并将结果限制在 360◦ 范围内来找到相交的瓦片。在垂直方向上,我们对高度瓦片边界进行排序,并通过一个简短的 for 循环找到交点,详情见附录 A。瓦片分配完成后,根据高斯分布的均值范围 µS 对高斯分布进行排序。
与使用大小相同的瓦片(类似于文献[7]中的基于深度图像的渲染)的策略相比,我们避免了许多不必要的计算。在那种方法中,瓦片大小必须从最精细的分辨率确定,以确保线程数量至少与激光雷达点的数量相同。因此,在激光雷达点分布稀疏的区域,瓦片的分辨率会显得过高,甚至可能缺少相应的激光雷达点来进行渲染。
光栅化:我们使用所提出的基于可微分分块的光栅化器来渲染激光雷达数据。同样,每个分块启动一个线程块,其中每个线程负责光栅化一个激光雷达点。每个线程都获得了用于光栅化的方位角、仰角和捕获时间。这些信息要么根据激光雷达规格确定,要么在训练时根据现有的点云计算得出,详情见附录 A。之所以这样,是因为在训练过程中,不能期望数据完全遵循笔直的扫描线。因此,我们不能采用图像策略,不能仅依靠块和线程索引来直接推断像素坐标。此外,激光雷达射线的方位角和仰角并不一定能确定其相对于激光雷达扫描中心的时间偏移。
对于每个激光雷达点,我们使用公式(4)至(6)对高斯特征进行α混合 fi 。受[47]中关于公式(5)中的 s 应对应一个像素的启发,我们将 s 设置为对应激光雷达垂直和水平光束发散度的几何平均值。渲染后的特征与其对应的光线方向进行拼接,并通过一个小的多层感知机(MLP)解码为强度和光线丢失概率。
为了呈现某一点的预期范围,我们对每个高斯分布的滚动快门校正范围进行α混合。
![]()
其中 vrS 是相对于激光雷达的速度的范围分量, tl 是当前激光雷达点的捕获时间和激光雷达扫描中间时间的间隔。此外,在公式(4)中的α混合过程中,我们将第一个满足 j=1(1−α j ) < 0.5 的高斯分布的中位数范围作为 rollingQi快门校正范围。在训练时我们使用预期范围,而在推理时使用中位数范围,因为与预期范围不同,中位数范围不会产生高斯分布之间的深度值。
3.4. 优化与实施
所有模型组件均使用损失函数进行联合优化。
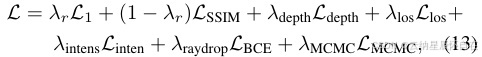
其中 L1 和 LSSIM 分别是渲染图像上的 L1 损失和结构相似性指数(SSIM)损失。Ldepth 和 Linten 分别是渲染的预期激光雷达距离和强度上的 L2 损失。Llos 是视线损失,对在真实激光雷达之前出现的不透明度进行惩罚。
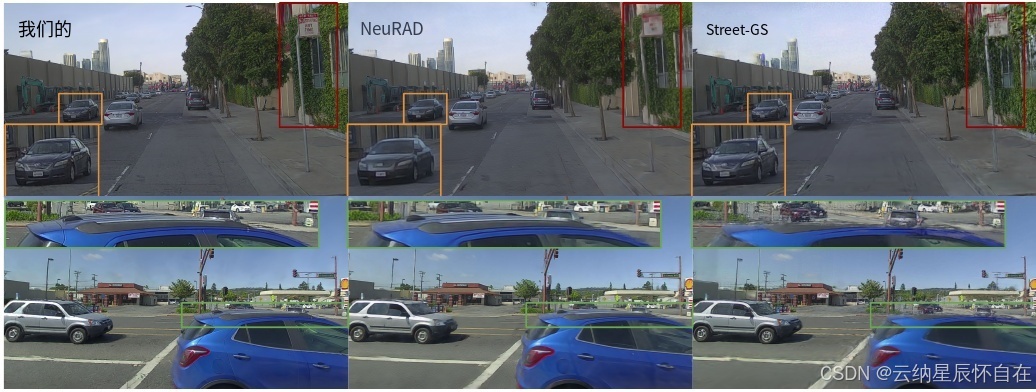
图 3. 与基线方法相比,SplatAD 生成的图像清晰且细节丰富。此外,底部一行突显了我们激光雷达渲染的优势。先前的 3DGS 方法将激光雷达点投影到图像中以进行深度监督,但由于相机和激光雷达之间的姿态差异,这会导致视线误差和不正确的体积雕刻。
范围。 LBCE 是预测光线掉落概率的二元交叉熵损失。 LMCMC 是 [16] 中使用的不透明度和缩放正则化。
我们使用激光雷达点和随机点来初始化高斯分布集合。位于边界框内的激光雷达点被分配给相应的对象。此外,所有激光雷达点都被投影到其最近的图像中以设置初始颜色。随机点分为两类:(1)在激光雷达范围内均匀采样的点;(2)在激光雷达范围外按视差线性采样的点,初始化时都使用随机颜色。此外,我们没有采用 3DGS [14] 的分裂和密集化策略,而是采用了 [16] 中介绍的 MCMC 策略。我们选择 MCMC 策略,部分原因是发现它能提高远场渲染质量,部分原因是其计算需求可预测,因为它允许选择高斯分布的最大数量。我们直接使用 [16] 中的方法,对分配给动态对象的高斯分布不做特殊处理。更多训练细节见附录 B。
实现:为了提高效率,我们使用自定义的 CUDA 内核来实现卷帘快门补偿、激光雷达投影和栅格化的前向和反向传播。SplatAD 基于协作开源框架 gsplat [46] 和 neurad-studio [34] 构建,我们希望我们的贡献不仅能在自动驾驶领域,还能在多模态模拟的未来研究中发挥作用。我们使用 Adam 优化器对 SplatAD 训练 30,000 次迭代,在单个 NVIDIA A100 上耗时一小时。更多细节请参见附录 B。
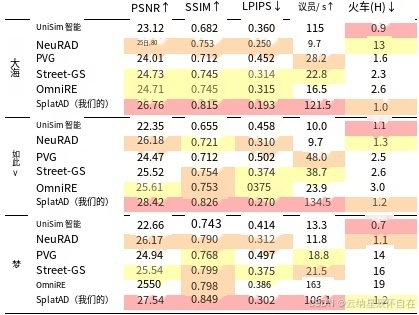
表 1.NVS 在三个数据集上的图像结果,第一,第二,第三。
4. Experiments
为了验证我们方法的稳健性,我们在多个流行的自动驾驶数据集上对其进行评估,使用相同的超参数设置。对于每个数据集,我们将 SplatAD 与针对自动驾驶数据在新视角合成方面表现最佳的 NeRF 和基于 3DGS 的方法进行比较,涵盖相机和激光雷达数据。此外,我们对 SplatAD 的关键元素进行消融研究,并测量它们对传感器真实感和渲染速度的影响。
数据集:我们在 PandaSet [41]、Argoverse2 [38] 和 nuScenes [5] 上进行实验。这些数据集在激光雷达、相机外观和分辨率方面各不相同。对于 PandaSet 和 nuScenes,我们使用了六台可用的相机。对于 Argoverse2,我们使用了七台环视相机,而未使用黑白立体相机。此外,有些相机是
为了去除对自身车辆(如引擎盖和后备箱)的视角,对图像进行了轻微裁剪。我们使用与 [35] 中相同的每个数据集的 10 个具有挑战性的序列,这些序列包含不同类型的光照、动态角色和速度。我们还遵循 [35] 的评估协议,即使用全分辨率数据,并且对于新视角合成(NVS),每隔一帧用于训练,其余帧用于保留验证。我们认为这种设置比以往工作中常见的设置更具挑战性[6, 7, 43],因为那些工作考虑的数据集较少,图像被下采样,且用于训练的数据比例更大。
基线方法:我们将我们的结果与在 AD 数据上表现最佳的 NeRF 和 3DGS 方法进行比较,即 UniSim [45]、NeuRAD [35]、PVG [6]、Street Gaussians [43] 和 OmniRe [7]。请注意,所有这些方法都是为动态场景设计的,并使用激光雷达数据进行监督。我们使用 NeuRAD 的官方实现 neurad-studio [34] 及其版本的 UniSim,以及 OmniRe 的官方实现 drivestudio [8] 及其版本的 PVG 和 Street Gaussians。我们使用 drivestudio 为 Street Gaussians 和 OmniRe 生成所需的天空掩码,并提取人体姿态估计,这在 A100 上分别需要大约 10 分钟和 30 分钟来处理每个序列。
尽管在 [7] 中展示了点云渲染,但在 drivestudio 中没有相关功能。为了在训练和验证视图中渲染点云,我们在激光雷达原点放置了 6 个虚拟相机,每个相机的水平视场角为 60°。垂直视场角设置为能够捕捉到整个扫描中的所有激光雷达点,焦距为每个数据集的中位焦距。我们将地面实况激光雷达点投影到这些图像中,获取每个点的深度,并将其重新投影到 3D 空间。由于 drivestudio 缺乏推断缺失激光雷达点的功能,因此这些基线仅针对现有点进行评估。相比之下,SplatAD 则是在更具有挑战性的任务上进行评估,即不仅要预测存在的激光雷达点的距离,还要预测缺失的激光雷达点的距离,并且必须根据预测的激光束丢失概率对其进行过滤。更多基线细节请参见附录 C。
4.1. 图像渲染
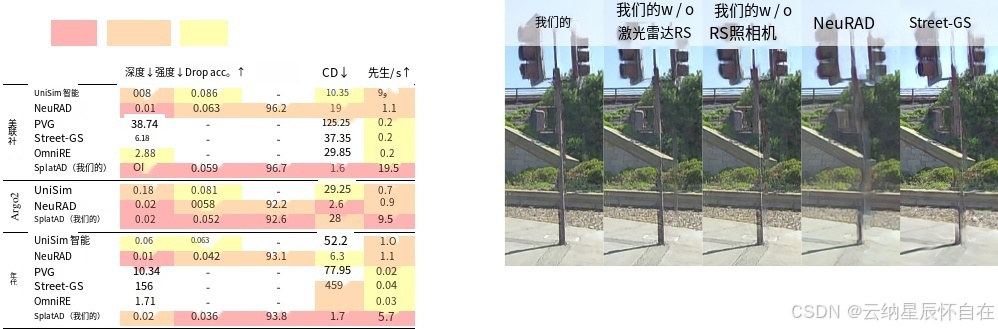
新颖视图合成:我们在表 1 中使用标准的 NVS 指标 PSNR、SSIM [37] 和 LPIPS [48] 对保留的验证图像的渲染质量进行了评估。我们使用每秒百万像素(与分辨率无关)来衡量速度。对于所考虑的三个数据集,SplatAD 在图像质量方面始终大幅优于现有的 3DGS 方法。此外,我们的方法在所有 NVS 指标上都超越了 NeuRAD 的 SOTA 结果,同时渲染速度提高了 10 倍。我们在图 3 中提供了定性比较。
重建:为了衡量这些方法建模能力的上限,我们在表 3 中报告了在 PandaSet 上的重建指标。在此,所有方法均基于序列中的所有数据进行训练,并在相同视图上进行评估。此外,我们为所有方法启用传感器姿态优化,以弥补任何姿态不准确的情况。与 NVS 设置相比,除了 UniSim 之外,所有方法在增加训练数据后均有所改进。SplatAD 达到了 SOTA 结果,且渲染速度比之前的最佳方法快 10 倍。此外,我们注意到 SplatAD 在表 1 中的保留验证图像上的表现与表 3 中 3DGS 方法的重建结果相当。
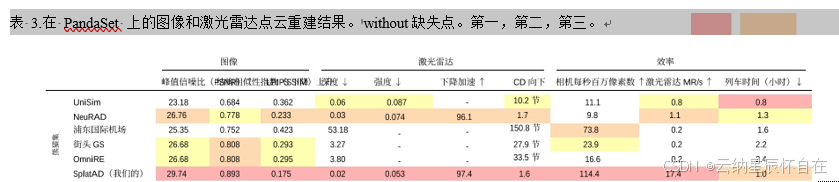
外推:我们研究了 SplatAD 对于与训练期间所遇场景差异显著的视角的泛化能力。我们使用每隔一帧训练的模型,并遵循 [35] 中的三种设置:水平移动主车、垂直移动主车以及对所有动态对象进行平移和旋转。我们使用 DINOv2 [28] 特征报告弗雷歇距离,因为已有研究表明 [32],与使用 Inception-v3 [33] 特征相比,这些特征更符合人类感知。不过,我们注意到,若使用 Inception-v3 特征,模型排名和我们的结论均不会改变。表 4 展示了 SplatAD 学习有意义的泛化表示的能力,明显优于其他 3DGS 方法。

|
表 4. FDDINOv2 当主车或行人的姿态发生变化时的得分。第一、第二、第三。 |
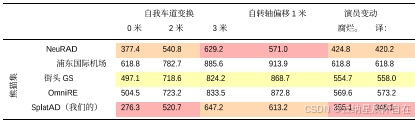
表 5. 从 PandaSet、nuScenes 和 Argoverse2 中选取的 10 个序列在移除模型组件时的 NVS 结果平均值。
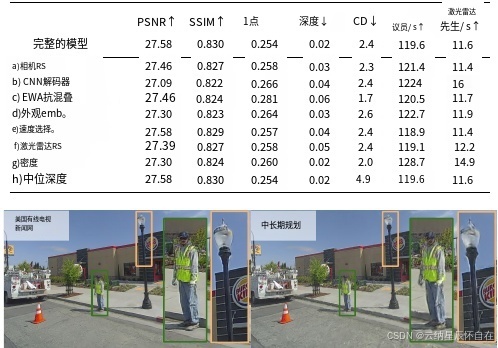
图 5. 卷积神经网络(CNN)解码器提高了清晰度,并且比多层感知机(MLP)解码器更保真地还原了色彩。
4.2. 激光雷达渲染
我们使用与文献[35]相同的指标来衡量激光雷达点云的质量,即中值深度误差平方、均方根强度误差、射线丢失准确率和切比雪夫距离,详见表2(NVS)和表3(重建)。需要注意的是,我们未报告 3DGS 基线的强度或射线丢失准确率,因为它们无法推断这些指标。此外,由于 DriveStudio 的内存需求无法很好地适应图像数量的增加和更高图像分辨率,因此无法为这些基线生成 Argoverse2 点云结果。我们发现 SplatAD 在点云质量方面与 NeuRAD 的精确光线追踪公式相当,但运行速度要快多达 18 倍。此外,我们的激光雷达渲染方法在速度和质量方面都优于 3DGS 基线所使用的基于深度图像的简单方法。
4.3. Ablations
我们通过测量表 5 中关键组件对 NVS 指标的影响来验证其有效性。为避免任何特定数据集的偏差,指标是基于所有三个数据集的平均值。我们发现,移除相机(a)或激光雷达(f)的滚动快门建模会降低 NVS 性能,而省去传感器速度的优化(e)会对我们的深度预测产生负面影响。虽然滚动快门建模对定量指标的影响相对较小,但我们定性地发现,它对于捕捉细小结构和边缘非常重要,见图 4。移除这些组件会导致视线误差,错误地穿过物体。此外,我们注意到我们的滚动快门算法的高效性,因为移除它们几乎不会提高渲染速度。
我们还发现,在图像解码时使用卷积神经网络(CNN)而非多层感知机(MLP)(c),能显著提升图像的真实感,且对运行时间没有重大影响,具体示例见图 5。此外,我们验证了在推理过程中使用中位深度而非预期深度对于生成真实的激光雷达数据在切比雪夫距离(h)方面至关重要。最后,我们注意到马尔可夫链蒙特卡罗(MCMC)[16] 和 EWA 抗锯齿技术[47, 52]均能提升我们的性能,其中抗锯齿技术对感知质量(以 LPIPS 为衡量标准)的影响最大。
5. Conclusion
在这项工作中,我们提出了 SplatAD,这是首个从三维高斯分布渲染相机和激光雷达数据的方法。我们结合了精确的传感器建模和高效的算法,在实现最先进的新视角合成结果的同时,将运行时间提高了超过一个数量级。我们希望 SplatAD 能够提升模拟环境的可扩展性和逼真度,从而为自动驾驶系统的测试提供更安全、更经济的选择。
局限性与未来工作:当前 SplatAD 仅能将所有动态角色建模为刚体。从近期人体重建方面的进展 [18, 20, 26] 中汲取灵感,可为未来研究如何克服这一局限性提供思路。此外,我们认为引入诸如扩散模型 [9, 11, 40] 这类数据驱动的先验知识是提升外推性能以及改变外观属性的一个有前景的方向。
致谢
我们感谢亚当·利尔贾、威廉·伦格伯格和亚当·托恩德斯基提出的宝贵意见。本研究部分得到了由瑞典皇家科学院和阿尔弗雷德·诺贝尔基金会资助的瓦伦堡人工智能、自主系统和软件计划(WASP)的支持。计算资源由瑞典国家超算中心(NSC)的贝采利乌斯超级计算机提供,部分资金来自瑞典研究理事会,资助协议编号为 2022-06725。
参考文献
[1] Mina Alibeigi, William Ljungbergh, Adam Tonderski, Georg Hess, Adam Lilja, Carl Lindstr¨om, Daria Motorniuk, Jun- sheng Fu, Jenny Widahl, and Christoffer Petersson. Zenseact open dataset: A large-scale and diverse multimodal dataset for autonomous driving. In ICCV, pages 20178–20188, 2023. 1
[2] Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neu- ral radiance fields. In ICCV, pages 5855–5864, 2021. 2
[3] Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In CVPR, pages 5470– 5479, 2022.
[4] Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Zip-nerf: Anti-aliased grid- based neural radiance fields. In ICCV, pages 19697–19705, 2023. 2
[5] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A mul- timodal dataset for autonomous driving. In CVPR, pages11621–11631, 2020. 1, 6
[6] Yurui Chen, Chun Gu, Junzhe Jiang, Xiatian Zhu, and Li Zhang. Periodic vibration gaussian: Dynamic urban scene reconstruction and real-time rendering. arXiv preprint arXiv:2311.18561, 2023. 2, 7
[7] Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lutio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Go- jcic, Sanja Fidler, Marco Pavone, et al. Omnire: Omni ur- ban scene reconstruction. arXiv preprint arXiv:2408.16760, 2024. 1, 2, 5, 7
[8] Ziyu Chen, Jiawei Yang, Jiahui Huang, Riccardo de Lu- tio, Janick Martinez Esturo, Boris Ivanovic, Or Litany, Zan Gojcic, Sanja Fidler, Marco Pavone, Li Song, and Yue Wang. drivestudio. https://github.com/ziyc/ drivestudio, 2024. 7, 2
[9] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. In ICML, 2024. 8
[10] Xiao Fu, Shangzhan Zhang, Tianrun Chen, Yichong Lu, Lanyun Zhu, Xiaowei Zhou, Andreas Geiger, and Yiyi Liao.
Panoptic nerf: 3d-to-2d label transfer for panoptic urban scene segmentation. In 3DV, pages 1–11. IEEE, 2022. 2
[11] Ruiqi Gao, Aleksander Holynski, Philipp Henzler, Arthur Brussee, Ricardo Martin Brualla, Pratul P. Srinivasan, Jonathan T. Barron, and Ben Poole. CAT3d: Create any- thing in 3d with multi-view diffusion models. In NeurIPS, 2024. 8
[12] Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Re- constructing and tracking humans with transformers. In ICCV, pages 14783–14794, 2023. 2
[13] Shengyu Huang, Zan Gojcic, Zian Wang, Francis Williams, Yoni Kasten, Sanja Fidler, Konrad Schindler, and Or Litany. Neural lidar fields for novel view synthesis. In ICCV, pages18236–18246, 2023. 2
[14] Bernhard Kerbl, Georgios Kopanas, Thomas Leimk¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. TOG, 42(4):139–1, 2023. 1, 2, 3, 4, 6
[15] Mustafa Khan, Hamidreza Fazlali, Dhruv Sharma, Tongtong Cao, Dongfeng Bai, Yuan Ren, and Bingbing Liu. Autosplat: Constrained gaussian splatting for autonomous driving scene reconstruction, 2024. 2
[16] Shakiba Kheradmand, Daniel Rebain, Gopal Sharma, Wei- wei Sun, Yang-Che Tseng, Hossam Isack, Abhishek Kar, Andrea Tagliasacchi, and Kwang Moo Yi. 3d gaussian splat- ting as markov chain monte carlo. In NeurIPS, 2024. 6, 8,2
[17] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In ICLR, 2015. 2
[18] Muhammed Kocabas, Jen-Hao Rick Chang, James Gabriel, Oncel Tuzel, and Anurag Ranjan. Hugs: Human gaussian splats. In CVPR, pages 505–515, 2024. 8
[19] Abhijit Kundu, Kyle Genova, Xiaoqi Yin, Alireza Fathi, Car- oline Pantofaru, Leonidas J Guibas, Andrea Tagliasacchi, Frank Dellaert, and Thomas Funkhouser. Panoptic neural fields: A semantic object-aware neural scene representation. In CVPR, pages 12871–12881, 2022. 2
[20] Youngjoong Kwon, Baole Fang, Yixing Lu, Haoye Dong, Cheng Zhang, Francisco Vicente Carrasco, Albert Mosella- Montoro, Jianjin Xu, Shingo Takagi, Daeil Kim, Aayush Prakash, and Fernando De la Torre. Generalizable human gaussians for sparse view synthesis. In ECCV, pages 451– 468, Cham, 2025. Springer Nature Switzerland. 8
[21] Nanxi Li, Chong Pei Ho, Jin Xue, Leh Woon Lim, Guanyu Chen, Yuan Hsing Fu, and Lennon Yao Ting Lee. A progress review on solid-state lidar and nanophotonics-based lidar sensors. Laser & Photonics Reviews, 16(11):2100511, 2022.5
[22] Carl Lindstr¨om, Georg Hess, Adam Lilja, Maryam Fatemi, Lars Hammarstrand, Christoffer Petersson, and Lennart Svensson. Are nerfs ready for autonomous driving? towards closing the real-to-simulation gap. In CVPRW, pages 4461– 4471, 2024. 2
[23] William Ljungbergh, Adam Tonderski, Joakim Johnan- der, Holger Caesar, Kalle Astr¨˚
om, Michael Felsberg, and
Christoffer Petersson. Neuroncap: Photorealistic closed-
loop safety testing for autonomous driving. In ECCV, pages161–177. Springer, 2025. 2
[24] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: A skinned multi- person linear model. TOG, 34(6):248:1–248:16, 2015. 2
[25] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view syn- thesis. In ECCV, pages 405–421, Cham, 2020. Springer In- ternational Publishing. 1, 2
[26] Arthur Moreau, Jifei Song, Helisa Dhamo, Richard Shaw, Yiren Zhou, and Eduardo P´erez-Pellitero. Human gaussian splatting: Real-time rendering of animatable avatars. In CVPR, pages 788–798, 2024. 8
[27] Thomas M¨uller, Alex Evans, Christoph Schied, and Alexan- der Keller. Instant neural graphics primitives with a multires- olution hash encoding. TOG, 41(4):1–15, 2022. 2
[28] Maxime Oquab, Timoth´ee Darcet, Th´eo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Je- gou, Julien Mairal, Patrick Labatut, Armand Joulin, and Pi- otr Bojanowski. DINOv2: Learning robust visual features without supervision. TMLR, 2024. 7
[29] Julian Ost, Fahim Mannan, Nils Thuerey, Julian Knodt, and Felix Heide. Neural scene graphs for dynamic scenes. In CVPR, pages 2856–2865, 2021. 2, 3
[30] Konstantinos Rematas, Andrew Liu, Pratul P Srini- vasan, Jonathan T Barron, Andrea Tagliasacchi, Thomas Funkhouser, and Vittorio Ferrari. Urban radiance fields. In CVPR, pages 12932–12942, 2022. 4
[31] Otto Seiskari, Jerry Ylilammi, Valtteri Kaatrasalo, Pekka Rantalankila, Matias Turkulainen, Juho Kannala, Esa Rahtu, and Arno Solin. Gaussian splatting on the move: Blur and rolling shutter compensation for natural camera mo- tion. In ECCV, pages 160–177, Cham, 2025. Springer Nature Switzerland. 4, 3
[32] George Stein, Jesse Cresswell, Rasa Hosseinzadeh, Yi Sui, Brendan Ross, Valentin Villecroze, Zhaoyan Liu, Anthony L Caterini, Eric Taylor, and Gabriel Loaiza-Ganem. Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models. NeurIPS, 36, 2024. 7
[33] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Rethinking the inception ar- chitecture for computer vision. In CVPR, pages 2818–2826, 2016. 7
[34] Adam Tonderski, Carl Lindstr¨om, Georg Hess, and William Ljungbergh. neurad-studio. https://github.com/ georghess/neurad-studio, 2024. 6, 7
[35] Adam Tonderski, Carl Lindstr¨om, Georg Hess, William Ljungbergh, Lennart Svensson, and Christoffer Petersson. Neurad: Neural rendering for autonomous driving. In CVPR, pages 14895–14904, 2024. 1, 2, 3, 4, 7, 8
[36] Haithem Turki, Jason Y Zhang, Francesco Ferroni, and Deva Ramanan. Suds: Scalable urban dynamic scenes. In CVPR, pages 12375–12385, 2023. 1, 2
[37] Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE TIP, 13(4):600–612, 2004. 7
[38] Benjamin Wilson, William Qi, Tanmay Agarwal, John Lam- bert, Jagjeet Singh, Siddhesh Khandelwal, Bowen Pan, Rat- nesh Kumar, Andrew Hartnett, Jhony Kaesemodel Pontes, Deva Ramanan, Peter Carr, and James Hays. Argoverse 2: Next generation datasets for self-driving perception and fore- casting. In Proceedings of the Neural Information Process- ing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks 2021), 2021. 1, 6
[39] Hanfeng Wu, Xingxing Zuo, Stefan Leutenegger, Or Litany, Konrad Schindler, and Shengyu Huang. Dynamic lidar re- simulation using compositional neural fields. In CVPR, pages 19988–19998, 2024. 2
[40] Rundi Wu, Ben Mildenhall, Philipp Henzler, Keunhong Park, Ruiqi Gao, Daniel Watson, Pratul P Srinivasan, Dor Verbin, Jonathan T Barron, Ben Poole, et al. Reconfusion: 3d reconstruction with diffusion priors. In CVPR, pages21551–21561, 2024. 8
[41] Pengchuan Xiao, Zhenlei Shao, Steven Hao, Zishuo Zhang, Xiaolin Chai, Judy Jiao, Zesong Li, Jian Wu, Kai Sun, Kun Jiang, Yunlong Wang, and Diange Yang. Pandaset: Ad- vanced sensor suite dataset for autonomous driving. In 2021 IEEE International Intelligent Transportation Systems Con- ference (ITSC), pages 3095–3101, 2021. 2, 6
[42] Ziyang Xie, Junge Zhang, Wenye Li, Feihu Zhang, and Li Zhang. S-neRF: Neural radiance fields for street views. In ICLR, 2023. 2
[43] Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. Street gaussians for modeling dynamic ur- ban scenes. In ECCV, 2024. 1, 2, 3, 7
[44] Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Se- ung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, and Yue Wang. EmerneRF: Emergent spatial- temporal scene decomposition via self-supervision. In ICLR, 2024. 2
[45] Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Mani- vasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Ur- tasun. Unisim: A neural closed-loop sensor simulator. In CVPR, pages 1389–1399, 2023. 1, 2, 7, 3
[46] Vickie Ye, Ruilong Li, Justin Kerr, Matias Turkulainen, Brent Yi, Zhuoyang Pan, Otto Seiskari, Jianbo Ye, Jeffrey Hu, Matthew Tancik, et al. gsplat: An open-source library for gaussian splatting. arXiv preprint arXiv:2409.06765, 2024.6
[47] Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. Mip-splatting: Alias-free 3d gaussian splat- ting. In CVPR, pages 19447–19456, 2024. 4, 5, 8
[48] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. In CVPR, pages 586–595, 2018. 7
[49] Zehan Zheng, Fan Lu, Weiyi Xue, Guang Chen, and Changjun Jiang. Lidar4d: Dynamic neural fields for novel space-time view lidar synthesis. In CVPR, pages 5145–5154, 2024. 2
[50] Hongyu Zhou, Jiahao Shao, Lu Xu, Dongfeng Bai, Weichao Qiu, Bingbing Liu, Yue Wang, Andreas Geiger, and Yiyi Liao. Hugs: Holistic urban 3d scene understanding via gaus- sian splatting. In CVPR, pages 21336–21345, 2024. 2
[51] Xiaoyu Zhou, Zhiwei Lin, Xiaojun Shan, Yongtao Wang, Deqing Sun, and Ming-Hsuan Yang. Drivinggaussian: Composite gaussian splatting for surrounding dynamic au- tonomous driving scenes. In CVPR, pages 21634–21643, 2024. 1, 2, 3
[52] Matthias Zwicker, Hanspeter Pfister, Jeroen Van Baar, and Markus Gross. Ewa volume splatting. In Proceedings Visu- alization, 2001. VIS’01., pages 29–538. IEEE, 2001. 4, 8


分享最新的 NVIDIA AI Software 资源以及活动/会议信息,精选收录AI相关技术内容,欢迎大家加入社区并参与讨论。
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)